 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRandom Walks: A Review of Algorithms and Applications
Aug 09, 2020
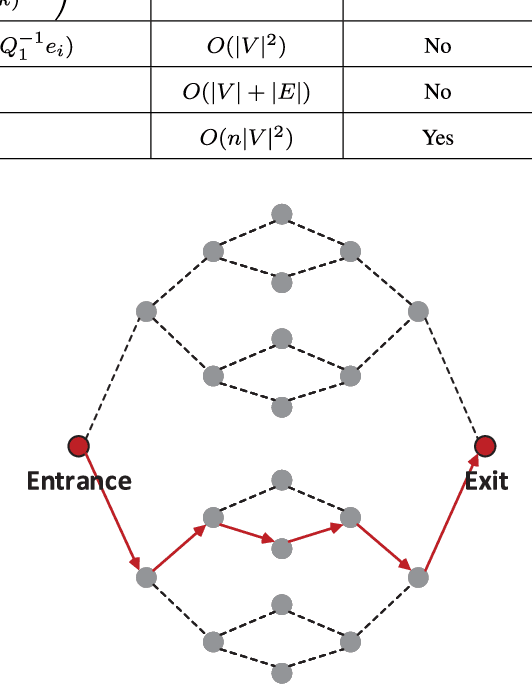
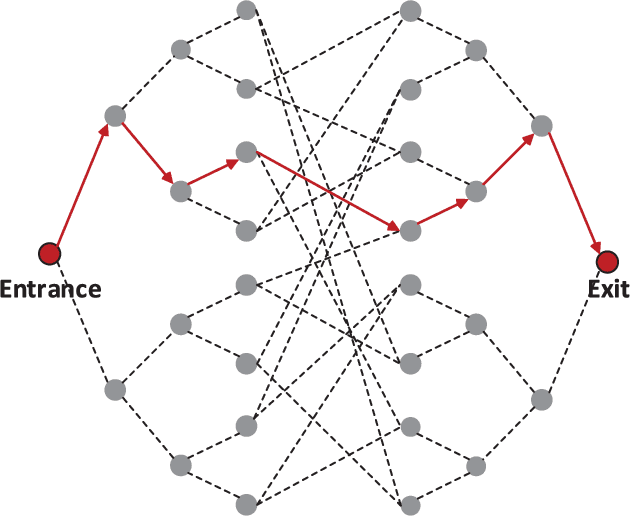
A random walk is known as a random process which describes a path including a succession of random steps in the mathematical space. It has increasingly been popular in various disciplines such as mathematics and computer science. Furthermore, in quantum mechanics, quantum walks can be regarded as quantum analogues of classical random walks. Classical random walks and quantum walks can be used to calculate the proximity between nodes and extract the topology in the network. Various random walk related models can be applied in different fields, which is of great significance to downstream tasks such as link prediction, recommendation, computer vision, semi-supervised learning, and network embedding. In this paper, we aim to provide a comprehensive review of classical random walks and quantum walks. We first review the knowledge of classical random walks and quantum walks, including basic concepts and some typical algorithms. We also compare the algorithms based on quantum walks and classical random walks from the perspective of time complexity. Then we introduce their applications in the field of computer science. Finally we discuss the open issues from the perspectives of efficiency, main-memory volume, and computing time of existing algorithms. This study aims to contribute to this growing area of research by exploring random walks and quantum walks together.
* 13 pages, 4 figures
Recurrent Exposure Generation for Low-Light Face Detection
Jul 21, 2020
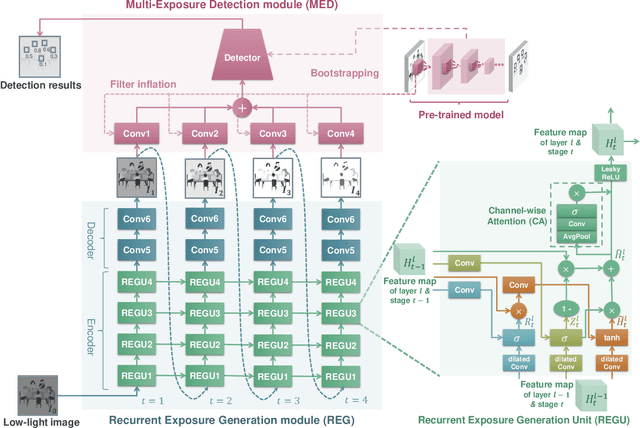
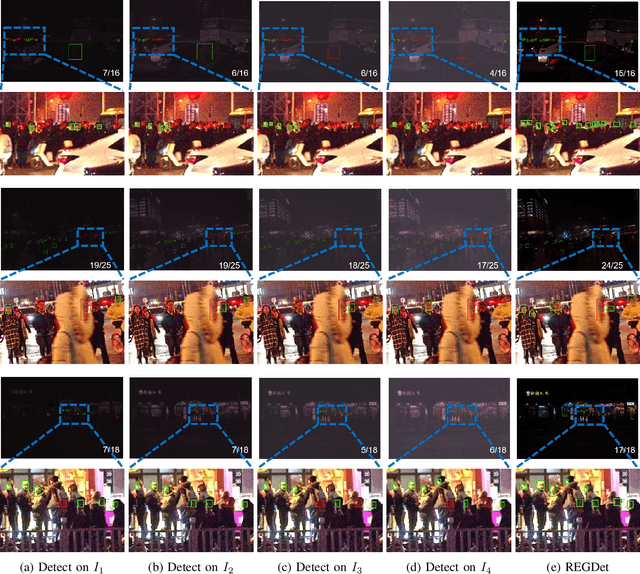
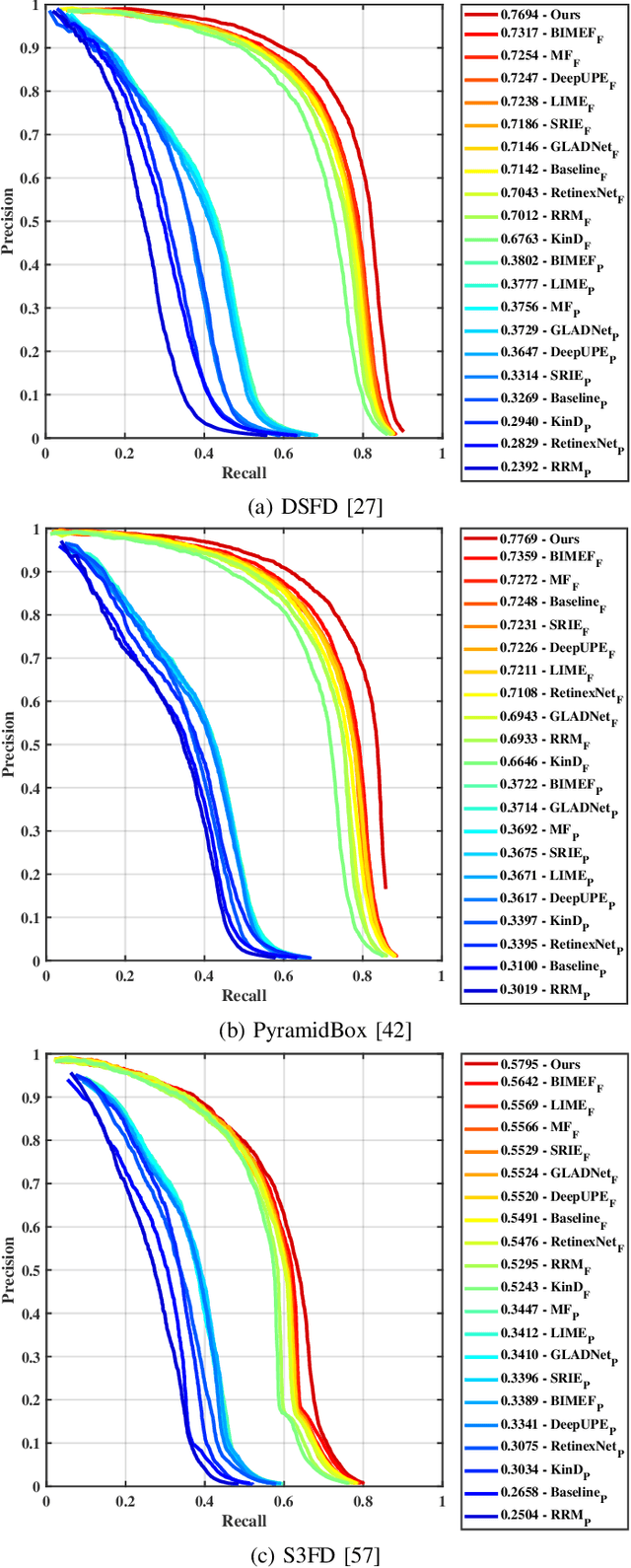
Face detection from low-light images is challenging due to limited photos and inevitable noise, which, to make the task even harder, are often spatially unevenly distributed. A natural solution is to borrow the idea from multi-exposure, which captures multiple shots to obtain well-exposed images under challenging conditions. High-quality implementation/approximation of multi-exposure from a single image is however nontrivial. Fortunately, as shown in this paper, neither is such high-quality necessary since our task is face detection rather than image enhancement. Specifically, we propose a novel Recurrent Exposure Generation (REG) module and couple it seamlessly with a Multi-Exposure Detection (MED) module, and thus significantly improve face detection performance by effectively inhibiting non-uniform illumination and noise issues. REG produces progressively and efficiently intermediate images corresponding to various exposure settings, and such pseudo-exposures are then fused by MED to detect faces across different lighting conditions. The proposed method, named REGDet, is the first `detection-with-enhancement' framework for low-light face detection. It not only encourages rich interaction and feature fusion across different illumination levels, but also enables effective end-to-end learning of the REG component to be better tailored for face detection. Moreover, as clearly shown in our experiments, REG can be flexibly coupled with different face detectors without extra low/normal-light image pairs for training. We tested REGDet on the DARK FACE low-light face benchmark with thorough ablation study, where REGDet outperforms previous state-of-the-arts by a significant margin, with only negligible extra parameters.
Fashion Meets Computer Vision: A Survey
Mar 31, 2020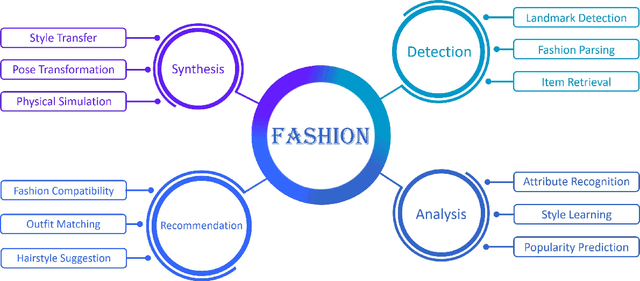

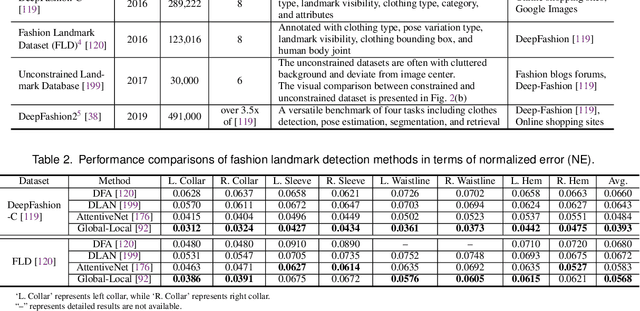

Fashion is the way we present ourselves to the world and has become one of the world's largest industries. Fashion, mainly conveyed by vision, has thus attracted much attention from computer vision researchers in recent years. Given the rapid development, this paper provides a comprehensive survey of more than 200 major fashion-related works covering four main aspects for enabling intelligent fashion: (1) Fashion detection includes landmark detection, fashion parsing, and item retrieval, (2) Fashion analysis contains attribute recognition, style learning, and popularity prediction, (3) Fashion synthesis involves style transfer, pose transformation, and physical simulation, and (4) Fashion recommendation comprises fashion compatibility, outfit matching, and hairstyle suggestion. For each task, the benchmark datasets and the evaluation protocols are summarized. Furthermore, we highlight promising directions for future research.
Learning End-to-End Lossy Image Compression: A Benchmark
Feb 19, 2020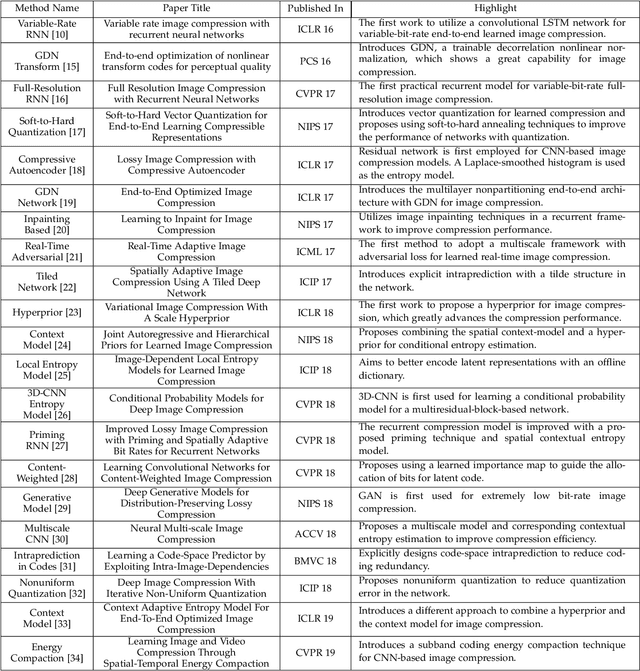
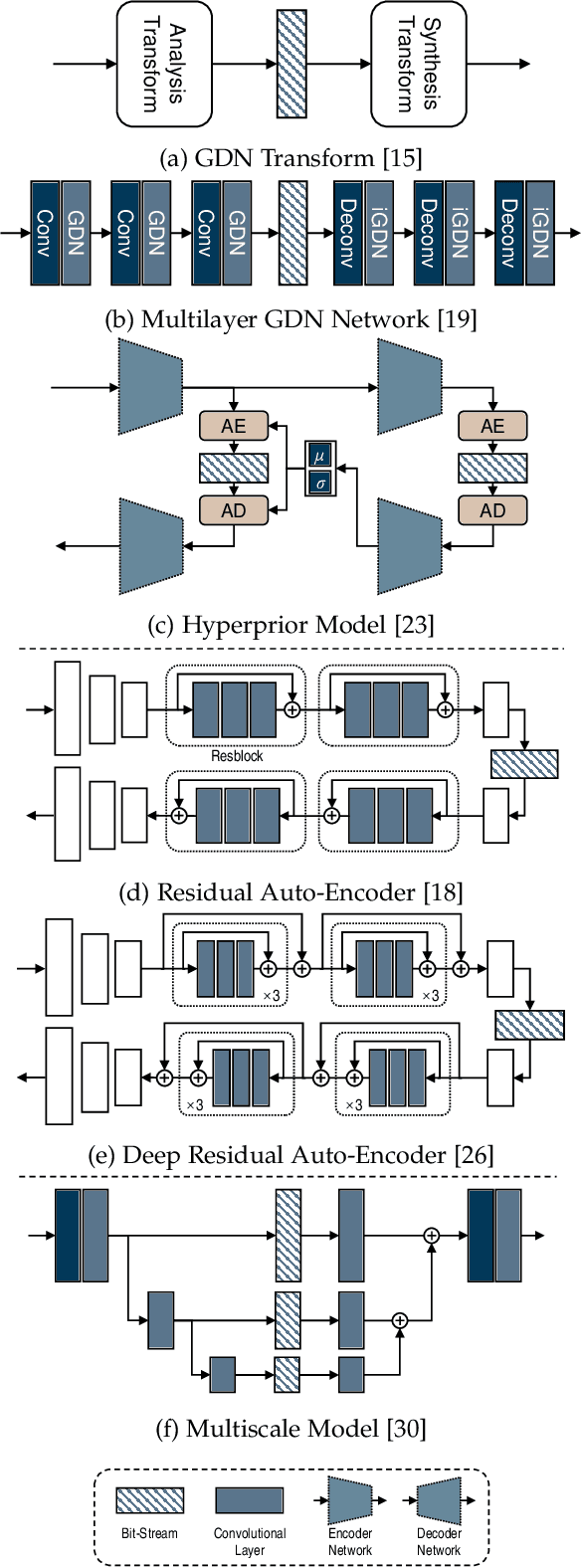
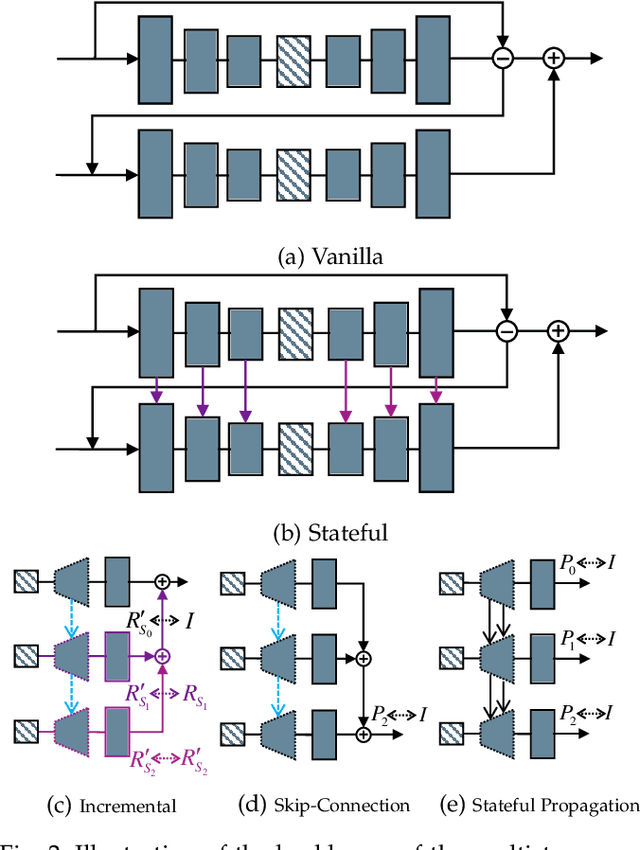
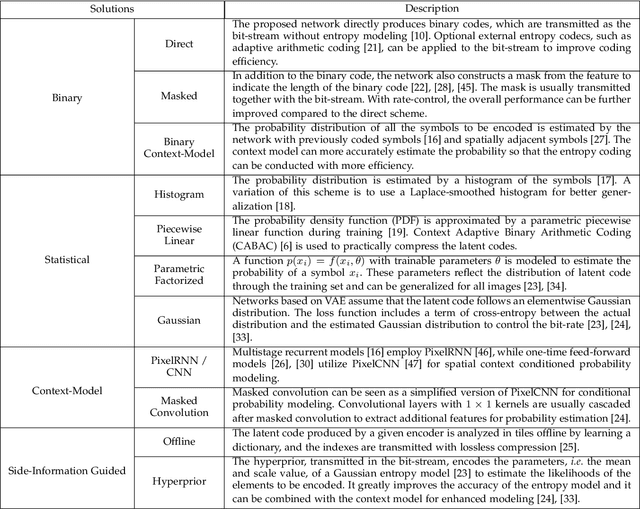
Image compression is one of the most fundamental techniques and commonly used applications in the image and video processing field. Earlier methods built a well-designed pipeline, and efforts were made to improve all modules of the pipeline by handcrafted tuning. Later, tremendous contributions were made, especially when data-driven methods revitalized the domain with their excellent modeling capacities and flexibility in incorporating newly designed modules and constraints. Despite great progress, a systematic benchmark and comprehensive analysis of end-to-end learned image compression methods are lacking. In this paper, we first conduct a comprehensive literature survey of learned image compression methods. The literature is organized based on several aspects to jointly optimize the rate-distortion performance with a neural network, i.e., network architecture, entropy model and rate control. We describe milestones in cutting-edge learned image-compression methods, review a broad range of existing works, and provide insights into their historical development routes. With this survey, the main challenges of image compression methods are revealed, along with opportunities to address the related issues with recent advanced learning methods. This analysis provides an opportunity to take a further step towards higher-efficiency image compression. By introducing a coarse-to-fine hyperprior model for entropy estimation and signal reconstruction, we achieve improved rate-distortion performance, especially on high-resolution images. Extensive benchmark experiments demonstrate the superiority of our model in coding efficiency and the potential for acceleration by large-scale parallel computing devices.
Modality Compensation Network: Cross-Modal Adaptation for Action Recognition
Jan 31, 2020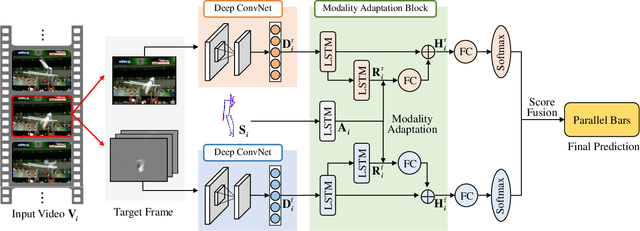
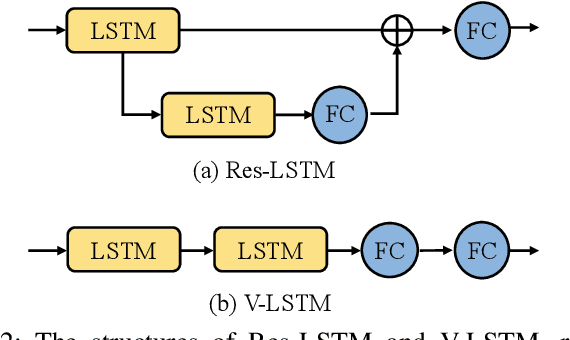
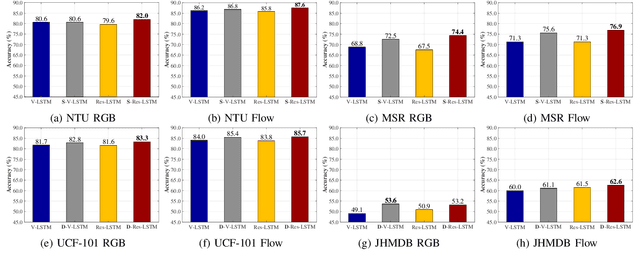
With the prevalence of RGB-D cameras, multi-modal video data have become more available for human action recognition. One main challenge for this task lies in how to effectively leverage their complementary information. In this work, we propose a Modality Compensation Network (MCN) to explore the relationships of different modalities, and boost the representations for human action recognition. We regard RGB/optical flow videos as source modalities, skeletons as auxiliary modality. Our goal is to extract more discriminative features from source modalities, with the help of auxiliary modality. Built on deep Convolutional Neural Networks (CNN) and Long Short Term Memory (LSTM) networks, our model bridges data from source and auxiliary modalities by a modality adaptation block to achieve adaptive representation learning, that the network learns to compensate for the loss of skeletons at test time and even at training time. We explore multiple adaptation schemes to narrow the distance between source and auxiliary modal distributions from different levels, according to the alignment of source and auxiliary data in training. In addition, skeletons are only required in the training phase. Our model is able to improve the recognition performance with source data when testing. Experimental results reveal that MCN outperforms state-of-the-art approaches on four widely-used action recognition benchmarks.
Combining Progressive Rethinking and Collaborative Learning: A Deep Framework for In-Loop Filtering
Jan 21, 2020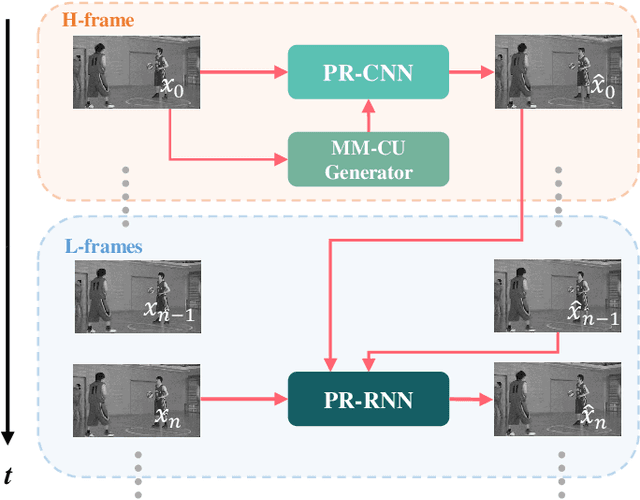
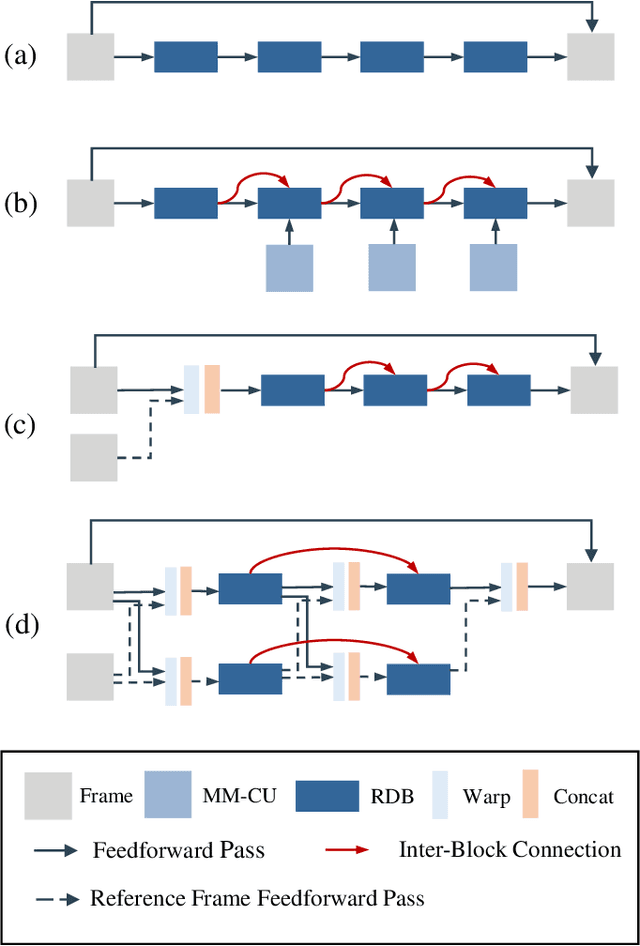
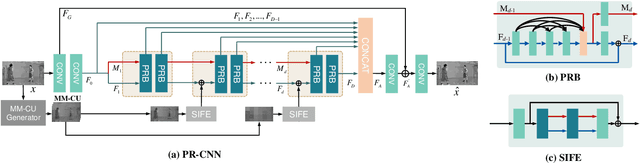
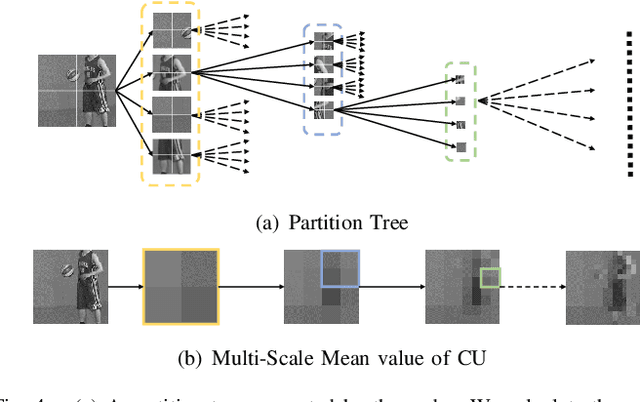
In this paper, we aim to address two critical issues in deep-learning based in-loop filter of modern codecs: 1) how to model spatial and temporal redundancies more effectively in the coding scenario; 2) what kinds of side information (side-info) can be inferred from the codecs to benefit in-loop filter models and how this side-info is injected. For the first issue, we design a deep network with both progressive rethinking and collaborative learning mechanisms to improve quality of the reconstructed intra-frames and inter-frames, respectively. For intra coding, a Progressive Rethinking Block (PRB) and its stacked Progressive Rethinking Network (PRN) are designed to simulate the human decision mechanism for effective spatial modeling. The typical cascaded deep network utilizes a bottleneck module at the end of each block to reduce the dimension size of the feature to generate the summarization of past experiences. Our designed block rethinks progressively, namely introducing an additional inter-block connection to bypass a high-dimensional informative feature across blocks to review the complete past memorized experiences. For inter coding, the model learns collaboratively for temporal modeling. The current reconstructed frame interacts with reference frames (peak quality frame and the nearest adjacent frame) progressively at the feature level. For the second issue, side-info utilization, we extract both intra-frame and interframe side-info for a better context modeling. A coarse-tofine partition map based on HEVC partition trees is built as the intra-frame side-info. Furthermore, the warped features of the reference frames are offered as the inter-frame side-info. Benefiting from our subtle design, under All-Intra (AI), Low-Delay B (LDB), Low-Delay P (LDP) and Random Access (RA) configuration, our PRNs provide 9.0%, 9.0%, 10.6% and 8.0% BD-rate reduction on average respectively.
Video Coding for Machines: A Paradigm of Collaborative Compression and Intelligent Analytics
Jan 13, 2020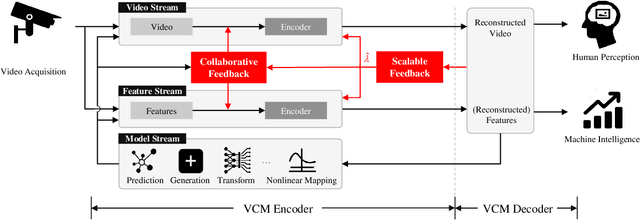
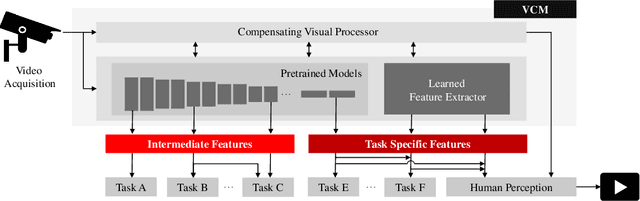

Video coding, which targets to compress and reconstruct the whole frame, and feature compression, which only preserves and transmits the most critical information, stand at two ends of the scale. That is, one is with compactness and efficiency to serve for machine vision, and the other is with full fidelity, bowing to human perception. The recent endeavors in imminent trends of video compression, e.g. deep learning based coding tools and end-to-end image/video coding, and MPEG-7 compact feature descriptor standards, i.e. Compact Descriptors for Visual Search and Compact Descriptors for Video Analysis, promote the sustainable and fast development in their own directions, respectively. In this paper, thanks to booming AI technology, e.g. prediction and generation models, we carry out exploration in the new area, Video Coding for Machines (VCM), arising from the emerging MPEG standardization efforts1. Towards collaborative compression and intelligent analytics, VCM attempts to bridge the gap between feature coding for machine vision and video coding for human vision. Aligning with the rising Analyze then Compress instance Digital Retina, the definition, formulation, and paradigm of VCM are given first. Meanwhile, we systematically review state-of-the-art techniques in video compression and feature compression from the unique perspective of MPEG standardization, which provides the academic and industrial evidence to realize the collaborative compression of video and feature streams in a broad range of AI applications. Finally, we come up with potential VCM solutions, and the preliminary results have demonstrated the performance and efficiency gains. Further direction is discussed as well.
Towards Coding for Human and Machine Vision: A Scalable Image Coding Approach
Jan 10, 2020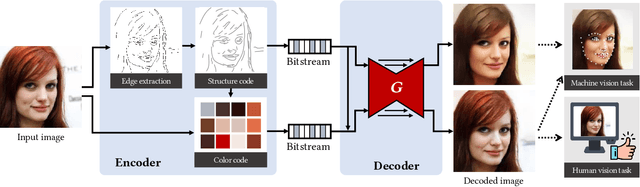

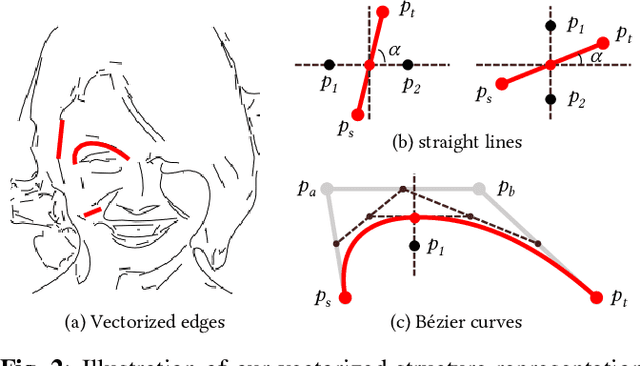

The past decades have witnessed the rapid development of image and video coding techniques in the era of big data. However, the signal fidelity-driven coding pipeline design limits the capability of the existing image/video coding frameworks to fulfill the needs of both machine and human vision. In this paper, we come up with a novel image coding framework by leveraging both the compressive and the generative models, to support machine vision and human perception tasks jointly. Given an input image, the feature analysis is first applied, and then the generative model is employed to perform image reconstruction with features and additional reference pixels, in which compact edge maps are extracted in this work to connect both kinds of vision in a scalable way. The compact edge map serves as the basic layer for machine vision tasks, and the reference pixels act as a sort of enhanced layer to guarantee signal fidelity for human vision. By introducing advanced generative models, we train a flexible network to reconstruct images from compact feature representations and the reference pixels. Experimental results demonstrate the superiority of our framework in both human visual quality and facial landmark detection, which provide useful evidence on the emerging standardization efforts on MPEG VCM (Video Coding for Machine).
An Emerging Coding Paradigm VCM: A Scalable Coding Approach Beyond Feature and Signal
Jan 09, 2020
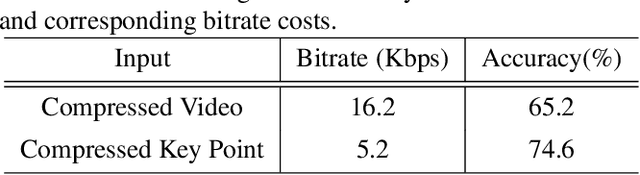
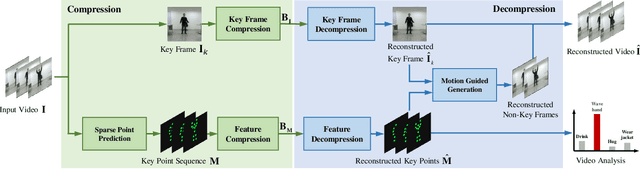

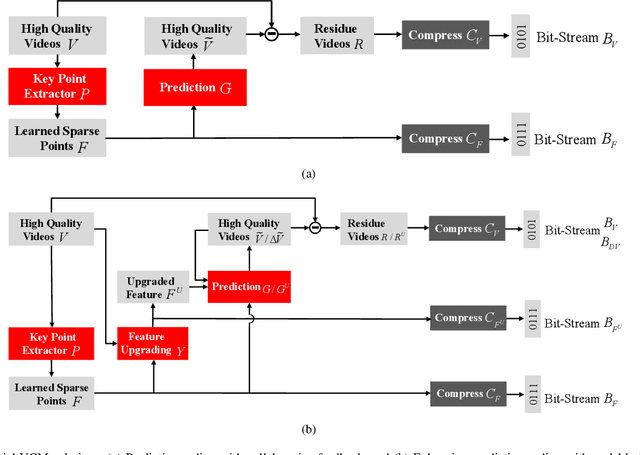
In this paper, we study a new problem arising from the emerging MPEG standardization effort Video Coding for Machine (VCM), which aims to bridge the gap between visual feature compression and classical video coding. VCM is committed to address the requirement of compact signal representation for both machine and human vision in a more or less scalable way. To this end, we make endeavors in leveraging the strength of predictive and generative models to support advanced compression techniques for both machine and human vision tasks simultaneously, in which visual features serve as a bridge to connect signal-level and task-level compact representations in a scalable manner. Specifically, we employ a conditional deep generation network to reconstruct video frames with the guidance of learned motion pattern. By learning to extract sparse motion pattern via a predictive model, the network elegantly leverages the feature representation to generate the appearance of to-be-coded frames via a generative model, relying on the appearance of the coded key frames. Meanwhile, the sparse motion pattern is compact and highly effective for high-level vision tasks, e.g. action recognition. Experimental results demonstrate that our method yields much better reconstruction quality compared with the traditional video codecs (0.0063 gain in SSIM), as well as state-of-the-art action recognition performance over highly compressed videos (9.4% gain in recognition accuracy), which showcases a promising paradigm of coding signal for both human and machine vision.
Deep Plastic Surgery: Robust and Controllable Image Editing with Human-Drawn Sketches
Jan 09, 2020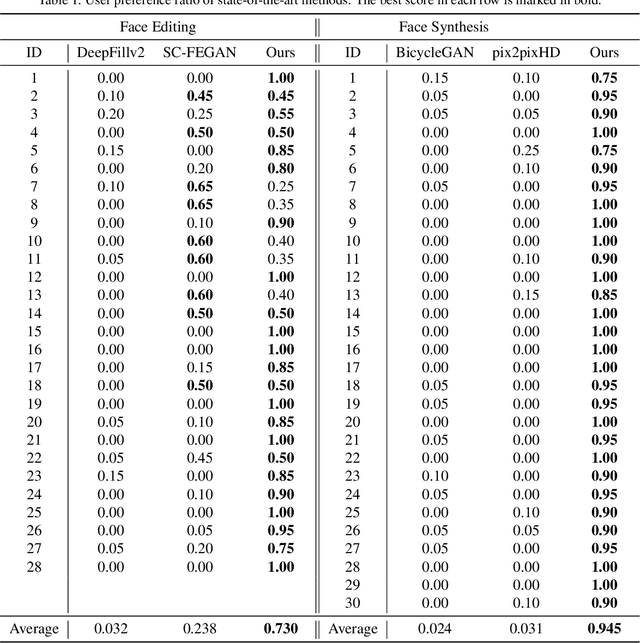
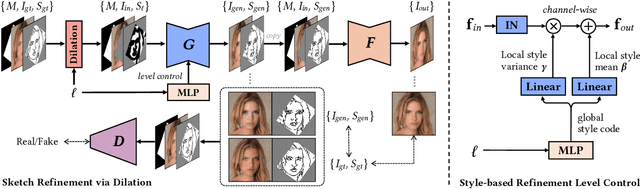
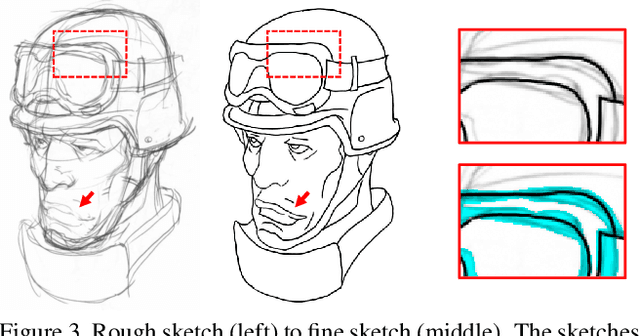

Sketch-based image editing aims to synthesize and modify photos based on the structural information provided by the human-drawn sketches. Since sketches are difficult to collect, previous methods mainly use edge maps instead of sketches to train models (referred to as edge-based models). However, sketches display great structural discrepancy with edge maps, thus failing edge-based models. Moreover, sketches often demonstrate huge variety among different users, demanding even higher generalizability and robustness for the editing model to work. In this paper, we propose Deep Plastic Surgery, a novel, robust and controllable image editing framework that allows users to interactively edit images using hand-drawn sketch inputs. We present a sketch refinement strategy, as inspired by the coarse-to-fine drawing process of the artists, which we show can help our model well adapt to casual and varied sketches without the need for real sketch training data. Our model further provides a refinement level control parameter that enables users to flexibly define how "reliable" the input sketch should be considered for the final output, balancing between sketch faithfulness and output verisimilitude (as the two goals might contradict if the input sketch is drawn poorly). To achieve the multi-level refinement, we introduce a style-based module for level conditioning, which allows adaptive feature representations for different levels in a singe network. Extensive experimental results demonstrate the superiority of our approach in improving the visual quality and user controllablity of image editing over the state-of-the-art methods.