 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNAS: N-step computation of All Solutions to the footstep planning problem
Jul 17, 2024



How many ways are there to climb a staircase in a given number of steps? Infinitely many, if we focus on the continuous aspect of the problem. A finite, possibly large number if we consider the discrete aspect, i.e. on which surface which effectors are going to step and in what order. We introduce NAS, an algorithm that considers both aspects simultaneously and computes all the possible solutions to such a contact planning problem, under standard assumptions. To our knowledge NAS is the first algorithm to produce a globally optimal policy, efficiently queried in real time for planning the next footsteps of a humanoid robot. Our empirical results (in simulation and on the Talos platform) demonstrate that, despite the theoretical exponential complexity, optimisations reduce the practical complexity of NAS to a manageable bilinear form, maintaining completeness guarantees and enabling efficient GPU parallelisation. NAS is demonstrated in a variety of scenarios for the Talos robot, both in simulation and on the hardware platform. Future work will focus on further reducing computation times and extending the algorithm's applicability beyond gaited locomotion. Our companion video is available at https://youtu.be/Shkf8PyDg4g
Label-free Neural Semantic Image Synthesis
Jul 01, 2024
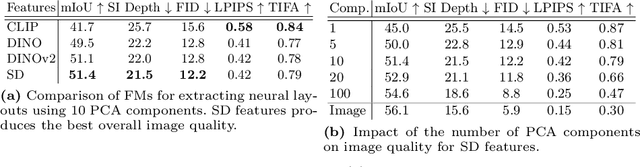
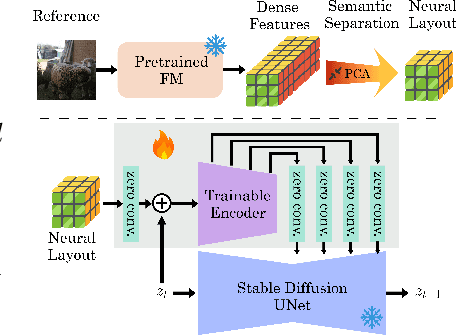
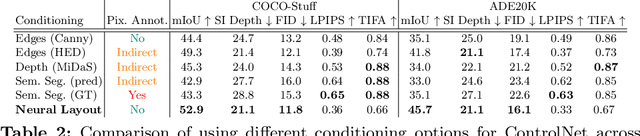
Recent work has shown great progress in integrating spatial conditioning to control large, pre-trained text-to-image diffusion models. Despite these advances, existing methods describe the spatial image content using hand-crafted conditioning inputs, which are either semantically ambiguous (e.g., edges) or require expensive manual annotations (e.g., semantic segmentation). To address these limitations, we propose a new label-free way of conditioning diffusion models to enable fine-grained spatial control. We introduce the concept of neural semantic image synthesis, which uses neural layouts extracted from pre-trained foundation models as conditioning. Neural layouts are advantageous as they provide rich descriptions of the desired image, containing both semantics and detailed geometry of the scene. We experimentally show that images synthesized via neural semantic image synthesis achieve similar or superior pixel-level alignment of semantic classes compared to those created using expensive semantic label maps. At the same time, they capture better semantics, instance separation, and object orientation than other label-free conditioning options, such as edges or depth. Moreover, we show that images generated by neural layout conditioning can effectively augment real data for training various perception tasks.
ClinicalLab: Aligning Agents for Multi-Departmental Clinical Diagnostics in the Real World
Jun 19, 2024



LLMs have achieved significant performance progress in various NLP applications. However, LLMs still struggle to meet the strict requirements for accuracy and reliability in the medical field and face many challenges in clinical applications. Existing clinical diagnostic evaluation benchmarks for evaluating medical agents powered by LLMs have severe limitations. Firstly, most existing medical evaluation benchmarks face the risk of data leakage or contamination. Secondly, existing benchmarks often neglect the characteristics of multiple departments and specializations in modern medical practice. Thirdly, existing evaluation methods are limited to multiple-choice questions, which do not align with the real-world diagnostic scenarios. Lastly, existing evaluation methods lack comprehensive evaluations of end-to-end real clinical scenarios. These limitations in benchmarks in turn obstruct advancements of LLMs and agents for medicine. To address these limitations, we introduce ClinicalLab, a comprehensive clinical diagnosis agent alignment suite. ClinicalLab includes ClinicalBench, an end-to-end multi-departmental clinical diagnostic evaluation benchmark for evaluating medical agents and LLMs. ClinicalBench is based on real cases that cover 24 departments and 150 diseases. ClinicalLab also includes four novel metrics (ClinicalMetrics) for evaluating the effectiveness of LLMs in clinical diagnostic tasks. We evaluate 17 LLMs and find that their performance varies significantly across different departments. Based on these findings, in ClinicalLab, we propose ClinicalAgent, an end-to-end clinical agent that aligns with real-world clinical diagnostic practices. We systematically investigate the performance and applicable scenarios of variants of ClinicalAgent on ClinicalBench. Our findings demonstrate the importance of aligning with modern medical practices in designing medical agents.
Truncated Variance Reduced Value Iteration
May 21, 2024We provide faster randomized algorithms for computing an $\epsilon$-optimal policy in a discounted Markov decision process with $A_{\text{tot}}$-state-action pairs, bounded rewards, and discount factor $\gamma$. We provide an $\tilde{O}(A_{\text{tot}}[(1 - \gamma)^{-3}\epsilon^{-2} + (1 - \gamma)^{-2}])$-time algorithm in the sampling setting, where the probability transition matrix is unknown but accessible through a generative model which can be queried in $\tilde{O}(1)$-time, and an $\tilde{O}(s + (1-\gamma)^{-2})$-time algorithm in the offline setting where the probability transition matrix is known and $s$-sparse. These results improve upon the prior state-of-the-art which either ran in $\tilde{O}(A_{\text{tot}}[(1 - \gamma)^{-3}\epsilon^{-2} + (1 - \gamma)^{-3}])$ time [Sidford, Wang, Wu, Ye 2018] in the sampling setting, $\tilde{O}(s + A_{\text{tot}} (1-\gamma)^{-3})$ time [Sidford, Wang, Wu, Yang, Ye 2018] in the offline setting, or time at least quadratic in the number of states using interior point methods for linear programming. We achieve our results by building upon prior stochastic variance-reduced value iteration methods [Sidford, Wang, Wu, Yang, Ye 2018]. We provide a variant that carefully truncates the progress of its iterates to improve the variance of new variance-reduced sampling procedures that we introduce to implement the steps. Our method is essentially model-free and can be implemented in $\tilde{O}(A_{\text{tot}})$-space when given generative model access. Consequently, our results take a step in closing the sample-complexity gap between model-free and model-based methods.
DNABERT-S: Learning Species-Aware DNA Embedding with Genome Foundation Models
Feb 15, 2024



Effective DNA embedding remains crucial in genomic analysis, particularly in scenarios lacking labeled data for model fine-tuning, despite the significant advancements in genome foundation models. A prime example is metagenomics binning, a critical process in microbiome research that aims to group DNA sequences by their species from a complex mixture of DNA sequences derived from potentially thousands of distinct, often uncharacterized species. To fill the lack of effective DNA embedding models, we introduce DNABERT-S, a genome foundation model that specializes in creating species-aware DNA embeddings. To encourage effective embeddings to error-prone long-read DNA sequences, we introduce Manifold Instance Mixup (MI-Mix), a contrastive objective that mixes the hidden representations of DNA sequences at randomly selected layers and trains the model to recognize and differentiate these mixed proportions at the output layer. We further enhance it with the proposed Curriculum Contrastive Learning (C$^2$LR) strategy. Empirical results on 18 diverse datasets showed DNABERT-S's remarkable performance. It outperforms the top baseline's performance in 10-shot species classification with just a 2-shot training while doubling the Adjusted Rand Index (ARI) in species clustering and substantially increasing the number of correctly identified species in metagenomics binning. The code, data, and pre-trained model are publicly available at https://github.com/Zhihan1996/DNABERT_S.
MPRE: Multi-perspective Patient Representation Extractor for Disease Prediction
Jan 01, 2024Patient representation learning based on electronic health records (EHR) is a critical task for disease prediction. This task aims to effectively extract useful information on dynamic features. Although various existing works have achieved remarkable progress, the model performance can be further improved by fully extracting the trends, variations, and the correlation between the trends and variations in dynamic features. In addition, sparse visit records limit the performance of deep learning models. To address these issues, we propose the Multi-perspective Patient Representation Extractor (MPRE) for disease prediction. Specifically, we propose Frequency Transformation Module (FTM) to extract the trend and variation information of dynamic features in the time-frequency domain, which can enhance the feature representation. In the 2D Multi-Extraction Network (2D MEN), we form the 2D temporal tensor based on trend and variation. Then, the correlations between trend and variation are captured by the proposed dilated operation. Moreover, we propose the First-Order Difference Attention Mechanism (FODAM) to calculate the contributions of differences in adjacent variations to the disease diagnosis adaptively. To evaluate the performance of MPRE and baseline methods, we conduct extensive experiments on two real-world public datasets. The experiment results show that MPRE outperforms state-of-the-art baseline methods in terms of AUROC and AUPRC.
3D Pose Estimation of Two Interacting Hands from a Monocular Event Camera
Dec 21, 2023



3D hand tracking from a monocular video is a very challenging problem due to hand interactions, occlusions, left-right hand ambiguity, and fast motion. Most existing methods rely on RGB inputs, which have severe limitations under low-light conditions and suffer from motion blur. In contrast, event cameras capture local brightness changes instead of full image frames and do not suffer from the described effects. Unfortunately, existing image-based techniques cannot be directly applied to events due to significant differences in the data modalities. In response to these challenges, this paper introduces the first framework for 3D tracking of two fast-moving and interacting hands from a single monocular event camera. Our approach tackles the left-right hand ambiguity with a novel semi-supervised feature-wise attention mechanism and integrates an intersection loss to fix hand collisions. To facilitate advances in this research domain, we release a new synthetic large-scale dataset of two interacting hands, Ev2Hands-S, and a new real benchmark with real event streams and ground-truth 3D annotations, Ev2Hands-R. Our approach outperforms existing methods in terms of the 3D reconstruction accuracy and generalises to real data under severe light conditions.
* 17 pages, 12 figures, 7 tables; project page: https://4dqv.mpi-inf.mpg.de/Ev2Hands/
AfriMTE and AfriCOMET: Empowering COMET to Embrace Under-resourced African Languages
Nov 16, 2023



Despite the progress we have recorded in scaling multilingual machine translation (MT) models and evaluation data to several under-resourced African languages, it is difficult to measure accurately the progress we have made on these languages because evaluation is often performed on n-gram matching metrics like BLEU that often have worse correlation with human judgments. Embedding-based metrics such as COMET correlate better; however, lack of evaluation data with human ratings for under-resourced languages, complexity of annotation guidelines like Multidimensional Quality Metrics (MQM), and limited language coverage of multilingual encoders have hampered their applicability to African languages. In this paper, we address these challenges by creating high-quality human evaluation data with a simplified MQM guideline for error-span annotation and direct assessment (DA) scoring for 13 typologically diverse African languages. Furthermore, we develop AfriCOMET, a COMET evaluation metric for African languages by leveraging DA training data from high-resource languages and African-centric multilingual encoder (AfroXLM-Roberta) to create the state-of-the-art evaluation metric for African languages MT with respect to Spearman-rank correlation with human judgments (+0.406).
Prompt Optimisation with Random Sampling
Nov 16, 2023



Using the generative nature of a language model to generate task-relevant separators has shown competitive results compared to human-curated prompts like "TL;DR". We demonstrate that even randomly chosen tokens from the vocabulary as separators can achieve near-state-of-the-art performance. We analyse this phenomenon in detail using three different random generation strategies, establishing that the language space is rich with potential good separators, regardless of the underlying language model size. These observations challenge the common assumption that an effective prompt should be human-readable or task-relevant. Experimental results show that using random separators leads to an average 16% relative improvement across nine text classification tasks on seven language models, compared to human-curated separators, and is on par with automatic prompt searching methods.
Synslator: An Interactive Machine Translation Tool with Online Learning
Oct 08, 2023



Interactive machine translation (IMT) has emerged as a progression of the computer-aided translation paradigm, where the machine translation system and the human translator collaborate to produce high-quality translations. This paper introduces Synslator, a user-friendly computer-aided translation (CAT) tool that not only supports IMT, but is adept at online learning with real-time translation memories. To accommodate various deployment environments for CAT services, Synslator integrates two different neural translation models to handle translation memories for online learning. Additionally, the system employs a language model to enhance the fluency of translations in an interactive mode. In evaluation, we have confirmed the effectiveness of online learning through the translation models, and have observed a 13% increase in post-editing efficiency with the interactive functionalities of Synslator. A tutorial video is available at:https://youtu.be/K0vRsb2lTt8.