 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBookWorld: From Novels to Interactive Agent Societies for Creative Story Generation
Apr 20, 2025Recent advances in large language models (LLMs) have enabled social simulation through multi-agent systems. Prior efforts focus on agent societies created from scratch, assigning agents with newly defined personas. However, simulating established fictional worlds and characters remain largely underexplored, despite its significant practical value. In this paper, we introduce BookWorld, a comprehensive system for constructing and simulating book-based multi-agent societies. BookWorld's design covers comprehensive real-world intricacies, including diverse and dynamic characters, fictional worldviews, geographical constraints and changes, e.t.c. BookWorld enables diverse applications including story generation, interactive games and social simulation, offering novel ways to extend and explore beloved fictional works. Through extensive experiments, we demonstrate that BookWorld generates creative, high-quality stories while maintaining fidelity to the source books, surpassing previous methods with a win rate of 75.36%. The code of this paper can be found at the project page: https://bookworld2025.github.io/.
PowerAttention: Exponentially Scaling of Receptive Fields for Effective Sparse Attention
Mar 05, 2025Large Language Models (LLMs) face efficiency bottlenecks due to the quadratic complexity of the attention mechanism when processing long contexts. Sparse attention methods offer a promising solution, but existing approaches often suffer from incomplete effective context and/or require complex implementation of pipeline. We present a comprehensive analysis of sparse attention for autoregressive LLMs from the respective of receptive field, recognize the suboptimal nature of existing methods for expanding the receptive field, and introduce PowerAttention, a novel sparse attention design that facilitates effective and complete context extension through the theoretical analysis. PowerAttention achieves exponential receptive field growth in $d$-layer LLMs, allowing each output token to attend to $2^d$ tokens, ensuring completeness and continuity of the receptive field. Experiments demonstrate that PowerAttention outperforms existing static sparse attention methods by $5\sim 40\%$, especially on tasks demanding long-range dependencies like Passkey Retrieval and RULER, while maintaining a comparable time complexity to sliding window attention. Efficiency evaluations further highlight PowerAttention's superior speedup in both prefilling and decoding phases compared with dynamic sparse attentions and full attention ($3.0\times$ faster on 128K context), making it a highly effective and user-friendly solution for processing long sequences in LLMs.
Order Doesn't Matter, But Reasoning Does: Training LLMs with Order-Centric Augmentation
Feb 27, 2025



Logical reasoning is essential for large language models (LLMs) to ensure accurate and coherent inference. However, LLMs struggle with reasoning order variations and fail to generalize across logically equivalent transformations. LLMs often rely on fixed sequential patterns rather than true logical understanding. To address this issue, we introduce an order-centric data augmentation framework based on commutativity in logical reasoning. We first randomly shuffle independent premises to introduce condition order augmentation. For reasoning steps, we construct a directed acyclic graph (DAG) to model dependencies between steps, which allows us to identify valid reorderings of steps while preserving logical correctness. By leveraging order-centric augmentations, models can develop a more flexible and generalized reasoning process. Finally, we conduct extensive experiments across multiple logical reasoning benchmarks, demonstrating that our method significantly enhances LLMs' reasoning performance and adaptability to diverse logical structures. We release our codes and augmented data in https://anonymous.4open.science/r/Order-Centric-Data-Augmentation-822C/.
Order Matters: Investigate the Position Bias in Multi-constraint Instruction Following
Feb 24, 2025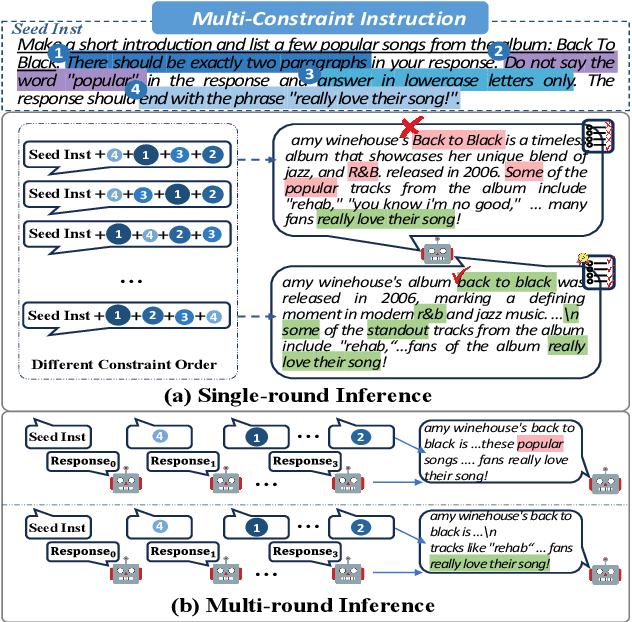
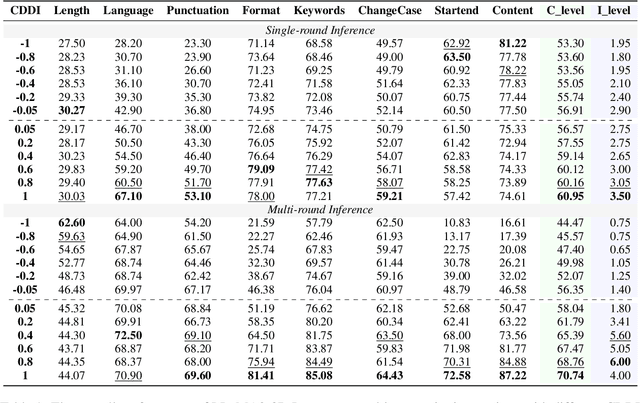
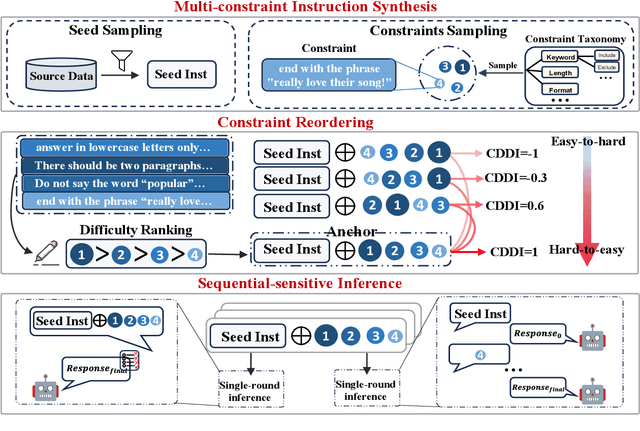

Real-world instructions with multiple constraints pose a significant challenge to existing large language models (LLMs). An observation is that the LLMs exhibit dramatic performance fluctuation when disturbing the order of the incorporated constraints. Yet, none of the existing works has systematically investigated this position bias problem in the field of multi-constraint instruction following. To bridge this gap, we design a probing task where we quantitatively measure the difficulty distribution of the constraints by a novel Difficulty Distribution Index (CDDI). Through the experimental results, we find that LLMs are more performant when presented with the constraints in a ``hard-to-easy'' order. This preference can be generalized to LLMs with different architecture or different sizes of parameters. Additionally, we conduct an explanation study, providing an intuitive insight into the correlation between the LLM's attention and constraint orders. Our code and dataset are publicly available at https://github.com/meowpass/PBIF.
CDS: Data Synthesis Method Guided by Cognitive Diagnosis Theory
Jan 13, 2025



Large Language Models (LLMs) have demonstrated outstanding capabilities across various domains, but the increasing complexity of new challenges demands enhanced performance and adaptability. Traditional benchmarks, although comprehensive, often lack the granularity needed for detailed capability analysis. This study introduces the Cognitive Diagnostic Synthesis (CDS) method, which employs Cognitive Diagnosis Theory (CDT) for precise evaluation and targeted enhancement of LLMs. By decomposing complex tasks into discrete knowledge points, CDS accurately identifies and synthesizes data targeting model weaknesses, thereby enhancing the model's performance. This framework proposes a comprehensive pipeline driven by knowledge point evaluation, synthesis, data augmentation, and filtering, which significantly improves the model's mathematical and coding capabilities, achieving up to an 11.12% improvement in optimal scenarios.
Step-by-Step Mastery: Enhancing Soft Constraint Following Ability of Large Language Models
Jan 09, 2025It is crucial for large language models (LLMs) to follow instructions that involve multiple constraints. However, soft constraints are semantically related and difficult to verify through automated methods. These constraints remain a significant challenge for LLMs. To enhance the ability of LLMs to follow soft constraints, we initially design a pipeline to obtain high-quality outputs automatically. Additionally, to fully utilize the acquired data, we introduce a training paradigm based on curriculum learning. We experimentally evaluate the effectiveness of our methods in improving LLMs' soft constraint following ability and analyze the factors driving the improvements. The datasets and code are publicly available at https://github.com/Rainier-rq/FollowSoftConstraints.
MultiLingPoT: Enhancing Mathematical Reasoning with Multilingual Program Fine-tuning
Dec 17, 2024Program-of-Thought (PoT), which aims to use programming language instead of natural language as an intermediate step in reasoning, is an important way for LLMs to solve mathematical problems. Since different programming languages excel in different areas, it is natural to use the most suitable language for solving specific problems. However, current PoT research only focuses on single language PoT, ignoring the differences between different programming languages. Therefore, this paper proposes an multilingual program reasoning method, MultiLingPoT. This method allows the model to answer questions using multiple programming languages by fine-tuning on multilingual data. Additionally, prior and posterior hybrid methods are used to help the model select the most suitable language for each problem. Our experimental results show that the training of MultiLingPoT improves each program's mathematical reasoning by about 2.5\%. Moreover, with proper mixing, the performance of MultiLingPoT can be further improved, achieving a 6\% increase compared to the single-language PoT with the data augmentation.Resources of this paper can be found at https://github.com/Nianqi-Li/MultiLingPoT.
QUILL: Quotation Generation Enhancement of Large Language Models
Nov 06, 2024



While Large language models (LLMs) have become excellent writing assistants, they still struggle with quotation generation. This is because they either hallucinate when providing factual quotations or fail to provide quotes that exceed human expectations. To bridge the gap, we systematically study how to evaluate and improve LLMs' performance in quotation generation tasks. We first establish a holistic and automatic evaluation system for quotation generation task, which consists of five criteria each with corresponding automatic metric. To improve the LLMs' quotation generation abilities, we construct a bilingual knowledge base that is broad in scope and rich in dimensions, containing up to 32,022 quotes. Moreover, guided by our critiria, we further design a quotation-specific metric to rerank the retrieved quotations from the knowledge base. Extensive experiments show that our metrics strongly correlate with human preferences. Existing LLMs struggle to generate desired quotes, but our quotation knowledge base and reranking metric help narrow this gap. Our dataset and code are publicly available at https://github.com/GraceXiaoo/QUILL.
EDGE: Enhanced Grounded GUI Understanding with Enriched Multi-Granularity Synthetic Data
Oct 25, 2024Autonomous agents operating on the graphical user interfaces (GUIs) of various applications hold immense practical value. Unlike the large language model (LLM)-based methods which rely on structured texts and customized backends, the approaches using large vision-language models (LVLMs) are more intuitive and adaptable as they can visually perceive and directly interact with screens, making them indispensable in general scenarios without text metadata and tailored backends. Given the lack of high-quality training data for GUI-related tasks in existing work, this paper aims to enhance the GUI understanding and interacting capabilities of LVLMs through a data-driven approach. We propose EDGE, a general data synthesis framework that automatically generates large-scale, multi-granularity training data from webpages across the Web. Evaluation results on various GUI and agent benchmarks demonstrate that the model trained with the dataset generated through EDGE exhibits superior webpage understanding capabilities, which can then be easily transferred to previously unseen desktop and mobile environments. Our approach significantly reduces the dependence on manual annotations, empowering researchers to harness the vast public resources available on the Web to advance their work. Our source code, the dataset and the model are available at https://anonymous.4open.science/r/EDGE-1CDB.
Think Thrice Before You Act: Progressive Thought Refinement in Large Language Models
Oct 17, 2024



Recent advancements in large language models (LLMs) have demonstrated that progressive refinement, rather than providing a single answer, results in more accurate and thoughtful outputs. However, existing methods often rely heavily on supervision signals to evaluate previous responses, making it difficult to assess output quality in more open-ended scenarios effectively. Additionally, these methods are typically designed for specific tasks, which limits their generalization to new domains. To address these limitations, we propose Progressive Thought Refinement (PTR), a framework that enables LLMs to refine their responses progressively. PTR operates in two phases: (1) Thought data construction stage: We propose a weak and strong model collaborative selection strategy to build a high-quality progressive refinement dataset to ensure logical consistency from thought to answers, and the answers are gradually refined in each round. (2) Thought-Mask Fine-Tuning Phase: We design a training structure to mask the "thought" and adjust loss weights to encourage LLMs to refine prior thought, teaching them to implicitly understand "how to improve" rather than "what is correct." Experimental results show that PTR significantly enhances LLM performance across ten diverse tasks (avg. from 49.6% to 53.5%) without task-specific fine-tuning. Notably, in more open-ended tasks, LLMs also demonstrate substantial improvements in the quality of responses beyond mere accuracy, suggesting that PTR truly teaches LLMs to self-improve over time.