 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniPCB: A Unified Vision-Language Benchmark for Open-Ended PCB Quality Inspection
Jan 27, 2026Multimodal Large Language Models (MLLMs) show promise for general industrial quality inspection, but fall short in complex scenarios, such as Printed Circuit Board (PCB) inspection. PCB inspection poses unique challenges due to densely packed components, complex wiring structures, and subtle defect patterns that require specialized domain expertise. However, a high-quality, unified vision-language benchmark for quantitatively evaluating MLLMs across PCB inspection tasks remains absent, stemming not only from limited data availability but also from fragmented datasets and inconsistent standardization. To fill this gap, we propose UniPCB, the first unified vision-language benchmark for open-ended PCB quality inspection. UniPCB is built via a systematic pipeline that curates and standardizes data from disparate sources across three annotated scenarios. Furthermore, we introduce PCB-GPT, an MLLM trained on a new instruction dataset generated by this pipeline, utilizing a novel progressive curriculum that mimics the learning process of human experts. Evaluations on the UniPCB benchmark show that while existing MLLMs falter on domain-specific tasks, PCB-GPT establishes a new baseline. Notably, it more than doubles the performance on fine-grained defect localization compared to the strongest competitors, with significant advantages in localization and analysis. We will release the instruction data, benchmark, and model to facilitate future research.
Developing a cardiovascular disease risk factor annotated corpus of Chinese electronic medical records
Mar 03, 2017
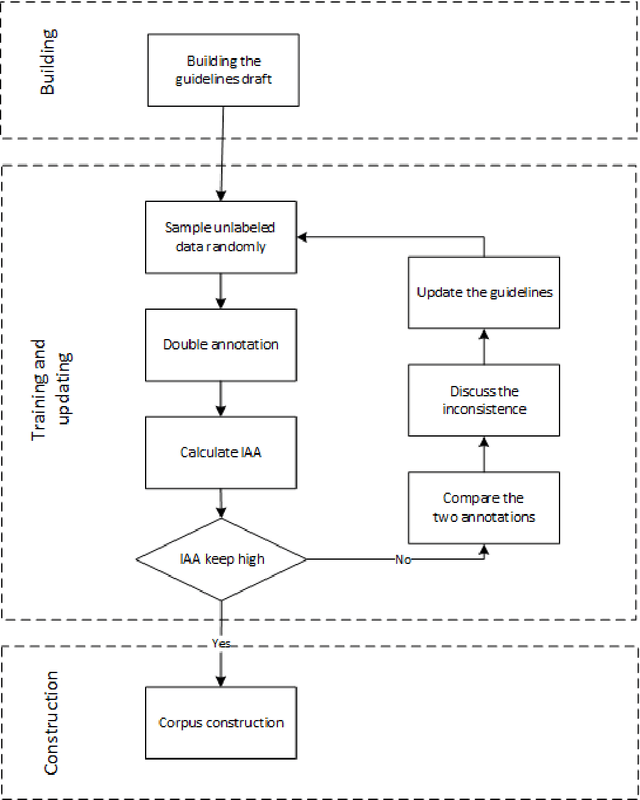
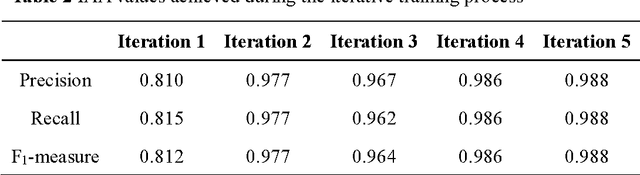
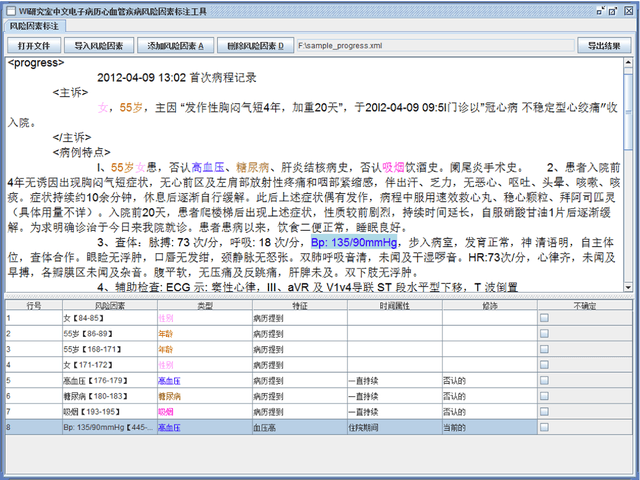
Cardiovascular disease (CVD) has become the leading cause of death in China, and most of the cases can be prevented by controlling risk factors. The goal of this study was to build a corpus of CVD risk factor annotations based on Chinese electronic medical records (CEMRs). This corpus is intended to be used to develop a risk factor information extraction system that, in turn, can be applied as a foundation for the further study of the progress of risk factors and CVD. We designed a light annotation task to capture CVD risk factors with indicators, temporal attributes and assertions that were explicitly or implicitly displayed in the records. The task included: 1) preparing data; 2) creating guidelines for capturing annotations (these were created with the help of clinicians); 3) proposing an annotation method including building the guidelines draft, training the annotators and updating the guidelines, and corpus construction. Then, a risk factor annotated corpus based on de-identified discharge summaries and progress notes from 600 patients was developed. Built with the help of clinicians, this corpus has an inter-annotator agreement (IAA) F1-measure of 0.968, indicating a high reliability. To the best of our knowledge, this is the first annotated corpus concerning CVD risk factors in CEMRs and the guidelines for capturing CVD risk factor annotations from CEMRs were proposed. The obtained document-level annotations can be applied in future studies to monitor risk factors and CVD over the long term.
Building a comprehensive syntactic and semantic corpus of Chinese clinical texts
Nov 08, 2016
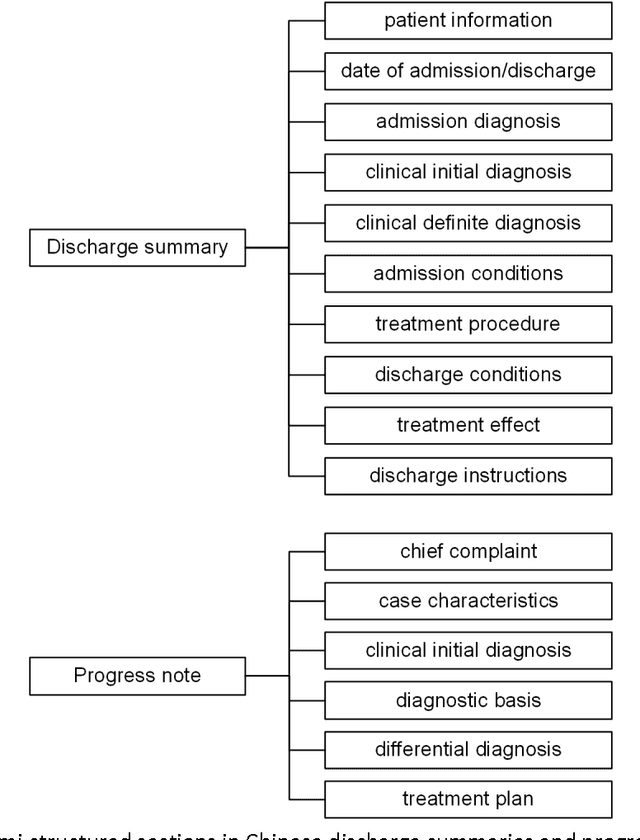
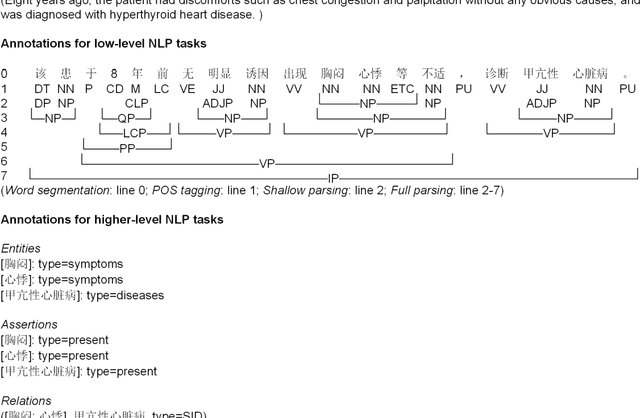
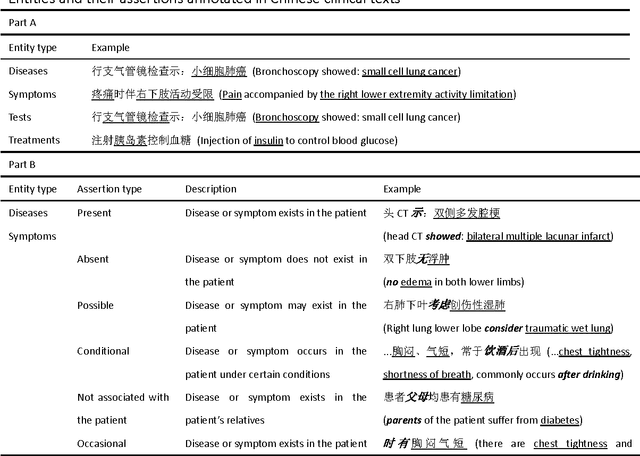
Objective: To build a comprehensive corpus covering syntactic and semantic annotations of Chinese clinical texts with corresponding annotation guidelines and methods as well as to develop tools trained on the annotated corpus, which supplies baselines for research on Chinese texts in the clinical domain. Materials and methods: An iterative annotation method was proposed to train annotators and to develop annotation guidelines. Then, by using annotation quality assurance measures, a comprehensive corpus was built, containing annotations of part-of-speech (POS) tags, syntactic tags, entities, assertions, and relations. Inter-annotator agreement (IAA) was calculated to evaluate the annotation quality and a Chinese clinical text processing and information extraction system (CCTPIES) was developed based on our annotated corpus. Results: The syntactic corpus consists of 138 Chinese clinical documents with 47,424 tokens and 2553 full parsing trees, while the semantic corpus includes 992 documents that annotated 39,511 entities with their assertions and 7695 relations. IAA evaluation shows that this comprehensive corpus is of good quality, and the system modules are effective. Discussion: The annotated corpus makes a considerable contribution to natural language processing (NLP) research into Chinese texts in the clinical domain. However, this corpus has a number of limitations. Some additional types of clinical text should be introduced to improve corpus coverage and active learning methods should be utilized to promote annotation efficiency. Conclusions: In this study, several annotation guidelines and an annotation method for Chinese clinical texts were proposed, and a comprehensive corpus with its NLP modules were constructed, providing a foundation for further study of applying NLP techniques to Chinese texts in the clinical domain.