 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage-to-Image Translation: Methods and Applications
Jan 21, 2021

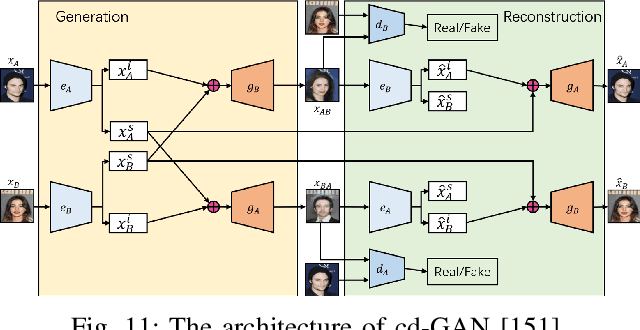
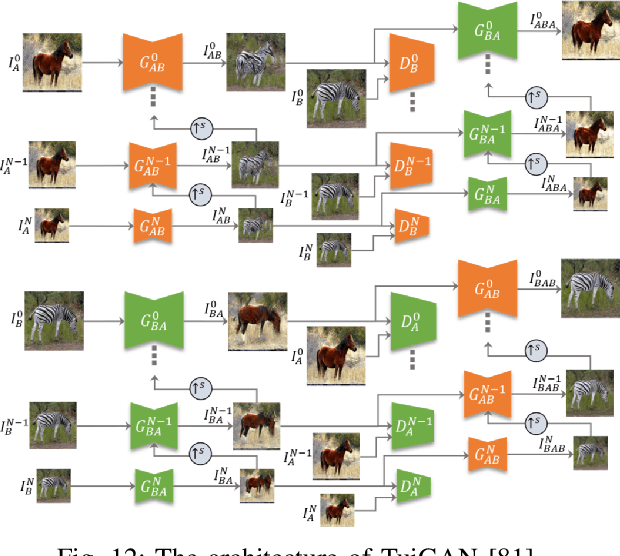
Image-to-image translation (I2I) aims to transfer images from a source domain to a target domain while preserving the content representations. I2I has drawn increasing attention and made tremendous progress in recent years because of its wide range of applications in many computer vision and image processing problems, such as image synthesis, segmentation, style transfer, restoration, and pose estimation. In this paper, we provide an overview of the I2I works developed in recent years. We will analyze the key techniques of the existing I2I works and clarify the main progress the community has made. Additionally, we will elaborate on the effect of I2I on the research and industry community and point out remaining challenges in related fields.
LIRA: Lifelong Image Restoration from Unknown Blended Distortions
Aug 19, 2020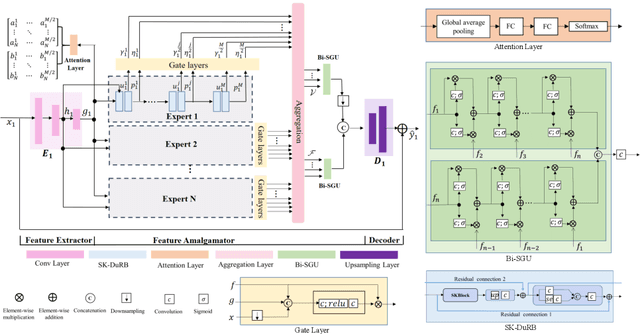
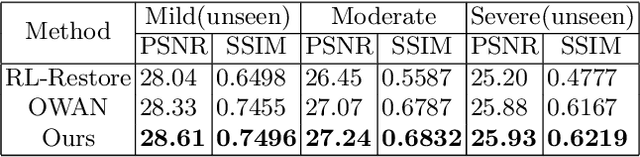
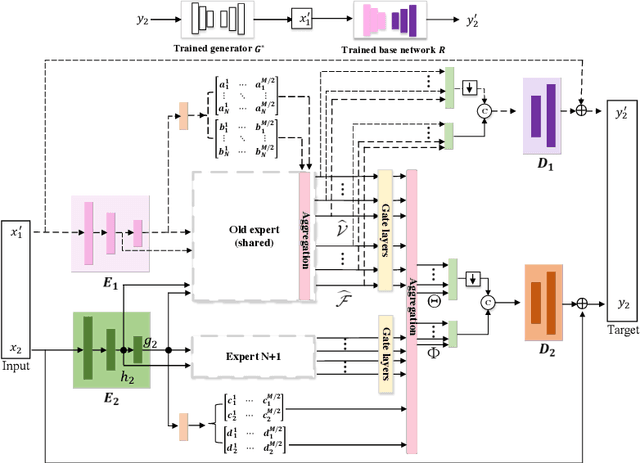
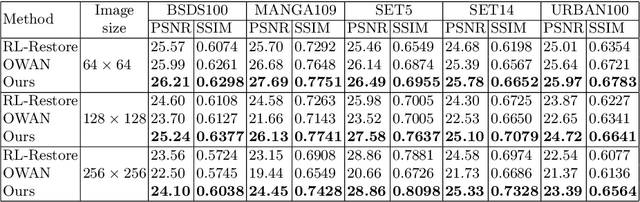
Most existing image restoration networks are designed in a disposable way and catastrophically forget previously learned distortions when trained on a new distortion removal task. To alleviate this problem, we raise the novel lifelong image restoration problem for blended distortions. We first design a base fork-join model in which multiple pre-trained expert models specializing in individual distortion removal task work cooperatively and adaptively to handle blended distortions. When the input is degraded by a new distortion, inspired by adult neurogenesis in human memory system, we develop a neural growing strategy where the previously trained model can incorporate a new expert branch and continually accumulate new knowledge without interfering with learned knowledge. Experimental results show that the proposed approach can not only achieve state-of-the-art performance on blended distortions removal tasks in both PSNR/SSIM metrics, but also maintain old expertise while learning new restoration tasks.
Learning Disentangled Feature Representation for Hybrid-distorted Image Restoration
Jul 22, 2020
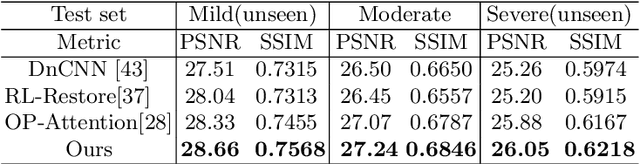
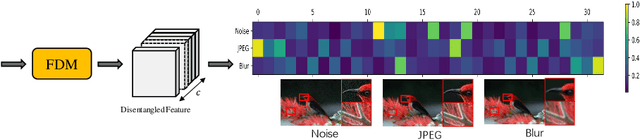

Hybrid-distorted image restoration (HD-IR) is dedicated to restore real distorted image that is degraded by multiple distortions. Existing HD-IR approaches usually ignore the inherent interference among hybrid distortions which compromises the restoration performance. To decompose such interference, we introduce the concept of Disentangled Feature Learning to achieve the feature-level divide-and-conquer of hybrid distortions. Specifically, we propose the feature disentanglement module (FDM) to distribute feature representations of different distortions into different channels by revising gain-control-based normalization. We also propose a feature aggregation module (FAM) with channel-wise attention to adaptively filter out the distortion representations and aggregate useful content information from different channels for the construction of raw image. The effectiveness of the proposed scheme is verified by visualizing the correlation matrix of features and channel responses of different distortions. Extensive experimental results also prove superior performance of our approach compared with the latest HD-IR schemes.
TuiGAN: Learning Versatile Image-to-Image Translation with Two Unpaired Images
Apr 09, 2020

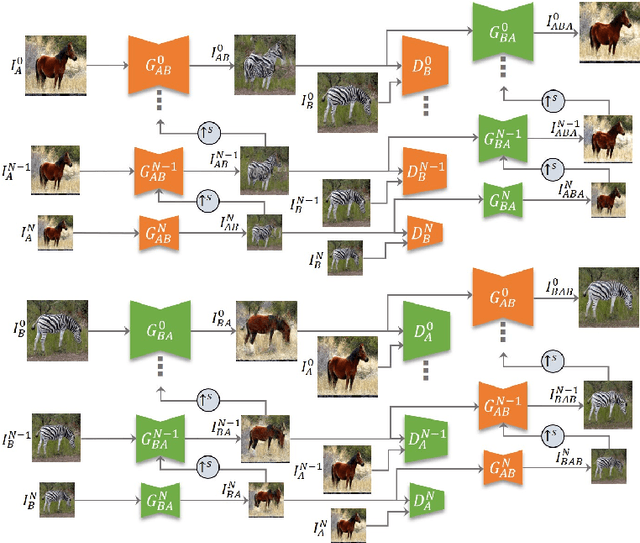
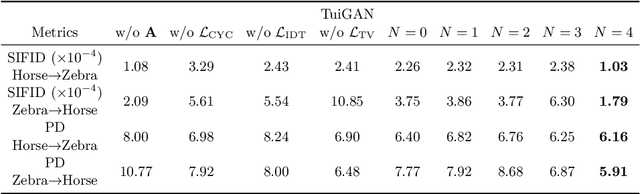
An unsupervised image-to-image translation (UI2I) task deals with learning a mapping between two domains without paired images. While existing UI2I methods usually require numerous unpaired images from different domains for training, there are many scenarios where training data is quite limited. In this paper, we argue that even if each domain contains a single image, UI2I can still be achieved. To this end, we propose TuiGAN, a generative model that is trained on only two unpaired images and amounts to one-shot unsupervised learning. With TuiGAN, an image is translated in a coarse-to-fine manner where the generated image is gradually refined from global structures to local details. We conduct extensive experiments to verify that our versatile method can outperform strong baselines on a wide variety of UI2I tasks. Moreover, TuiGAN is capable of achieving comparable performance with the state-of-the-art UI2I models trained with sufficient data.
ZstGAN: An Adversarial Approach for Unsupervised Zero-Shot Image-to-Image Translation
Jun 01, 2019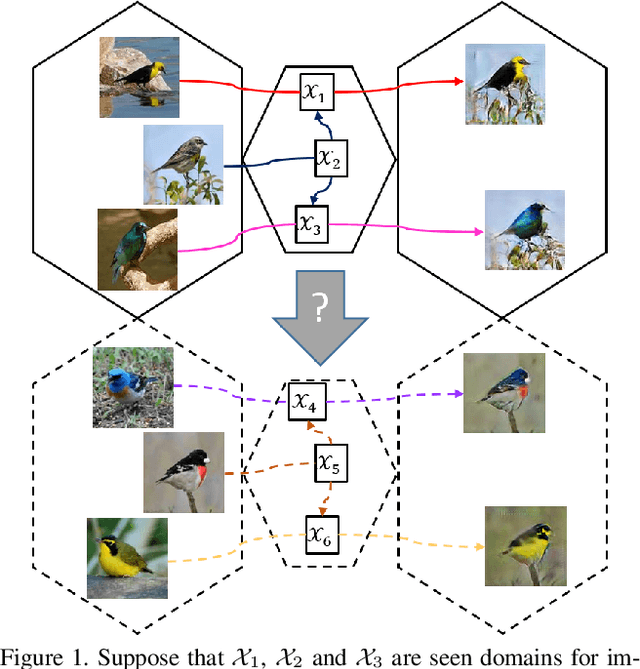
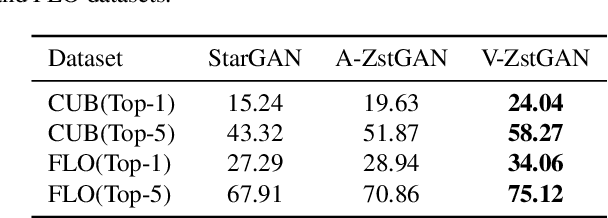
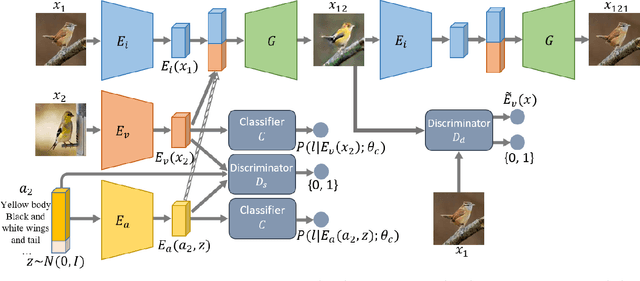
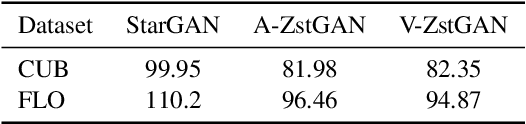
Image-to-image translation models have shown remarkable ability on transferring images among different domains. Most of existing work follows the setting that the source domain and target domain keep the same at training and inference phases, which cannot be generalized to the scenarios for translating an image from an unseen domain to an another unseen domain. In this work, we propose the Unsupervised Zero-Shot Image-to-image Translation (UZSIT) problem, which aims to learn a model that can transfer translation knowledge from seen domains to unseen domains. Accordingly, we propose a framework called ZstGAN: By introducing an adversarial training scheme, ZstGAN learns to model each domain with domain-specific feature distribution that is semantically consistent on vision and attribute modalities. Then the domain-invariant features are disentangled with an shared encoder for image generation. We carry out extensive experiments on CUB and FLO datasets, and the results demonstrate the effectiveness of proposed method on UZSIT task. Moreover, ZstGAN shows significant accuracy improvements over state-of-the-art zero-shot learning methods on CUB and FLO.
Learning to Transfer: Unsupervised Meta Domain Translation
Jun 01, 2019
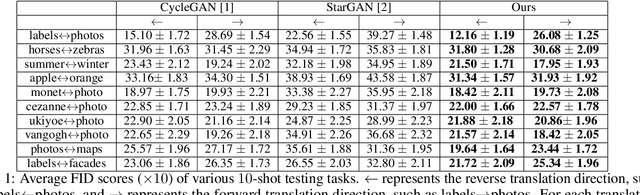
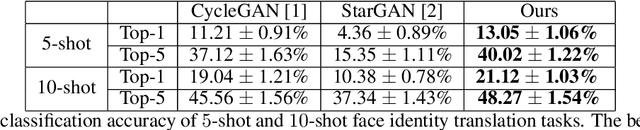
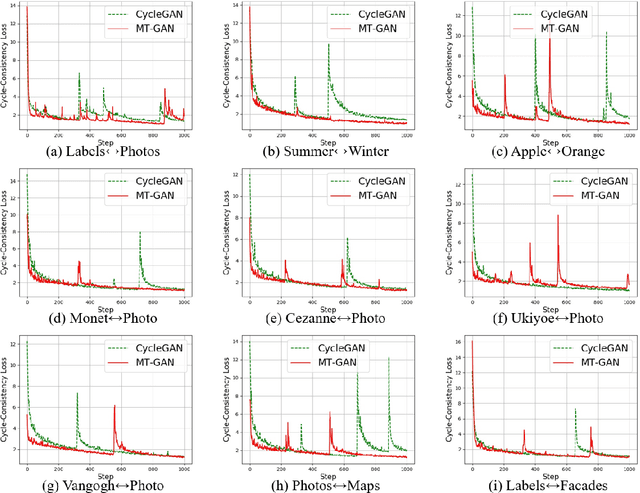
Unsupervised domain translation has recently achieved impressive performance with rapidly developed generative adversarial network (GAN) and availability of sufficient training data. However, existing domain translation frameworks form in a disposable way where the learning experiences are ignored. In this work, we take this research direction toward unsupervised meta domain translation problem. We propose a meta translation model called MT-GAN to find parameter initialization of a conditional GAN, which can quickly adapt for a new domain translation task with limited training samples. In the meta-training procedure, MT-GAN is explicitly fine-tuned with a primary translation task and a synthesized dual translation task. Then we design a meta-optimization objective to require the fine-tuned MT-GAN to produce good generalization performance. We demonstrate effectiveness of our model on ten diverse two-domain translation tasks and multiple face identity translation tasks. We show that our proposed approach significantly outperforms the existing domain translation methods when using no more than $10$ training samples in each image domain.
Image-to-Image Translation with Multi-Path Consistency Regularization
May 29, 2019

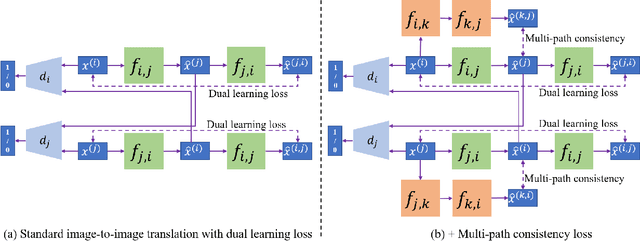

Image translation across different domains has attracted much attention in both machine learning and computer vision communities. Taking the translation from source domain $\mathcal{D}_s$ to target domain $\mathcal{D}_t$ as an example, existing algorithms mainly rely on two kinds of loss for training: One is the discrimination loss, which is used to differentiate images generated by the models and natural images; the other is the reconstruction loss, which measures the difference between an original image and the reconstructed version through $\mathcal{D}_s\to\mathcal{D}_t\to\mathcal{D}_s$ translation. In this work, we introduce a new kind of loss, multi-path consistency loss, which evaluates the differences between direct translation $\mathcal{D}_s\to\mathcal{D}_t$ and indirect translation $\mathcal{D}_s\to\mathcal{D}_a\to\mathcal{D}_t$ with $\mathcal{D}_a$ as an auxiliary domain, to regularize training. For multi-domain translation (at least, three) which focuses on building translation models between any two domains, at each training iteration, we randomly select three domains, set them respectively as the source, auxiliary and target domains, build the multi-path consistency loss and optimize the network. For two-domain translation, we need to introduce an additional auxiliary domain and construct the multi-path consistency loss. We conduct various experiments to demonstrate the effectiveness of our proposed methods, including face-to-face translation, paint-to-photo translation, and de-raining/de-noising translation.
Exploring Explicit Domain Supervision for Latent Space Disentanglement in Unpaired Image-to-Image Translation
Mar 26, 2019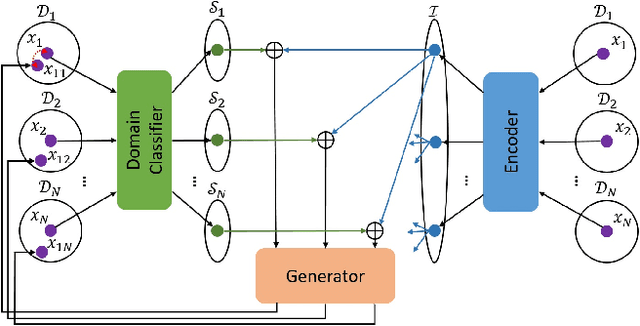
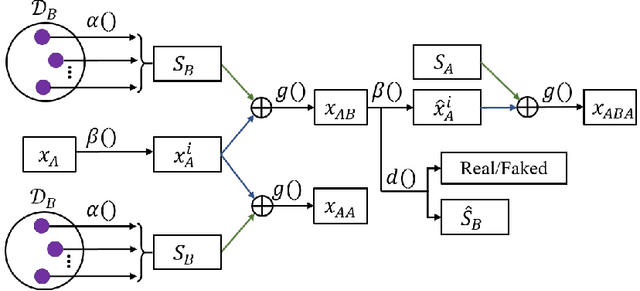

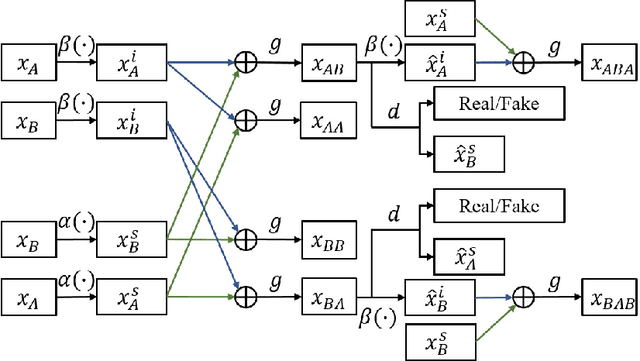
Image-to-image translation tasks have been widely investigated with Generative Adversarial Networks (GANs). However, existing approaches are mostly designed in an unsupervised manner while little attention has been paid to domain information within unpaired data. In this paper, we treat domain information as explicit supervision and design an unpaired image-to-image translation framework, Domain-supervised GAN (DosGAN), which takes the first step towards the exploration of explicit domain supervision. In contrast to representing domain characteristics using different generators in CycleGAN or multiple domain codes in StarGAN, we pre-train a classification network to explicitly classify the domain of an image. After pre-training, this network is used to extract the domain-specific features of each image by using the output of its second-to-last layer. Such features, together with the domain-independent features extracted by another encoder (shared across different domains), are used to generate an image in the target domain. Extensive experiments on multiple hair color translation, multiple identity translation, multiple season translation and conditional edges-to-shoes/handbags demonstrate the effectiveness of our method. In addition, we can transfer the domain-specific feature extractor obtained on the Facescrub dataset with domain supervision information to unseen domains, such as faces in the CelebA dataset. We also succeed in achieving conditional translation with any two images in CelebA, while previous models like StarGAN cannot handle this task.
Sequential Gating Ensemble Network for Noise Robust Multi-Scale Face Restoration
Dec 19, 2018
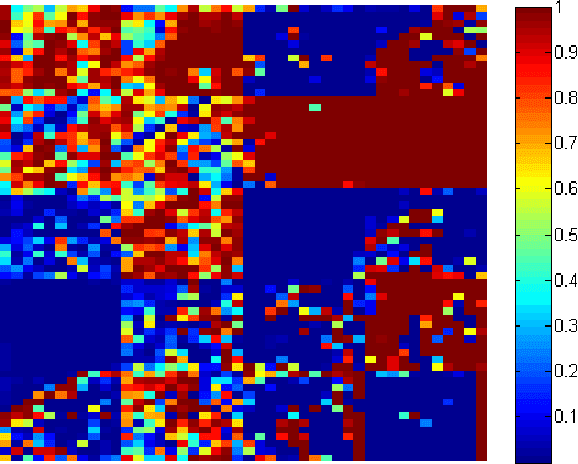
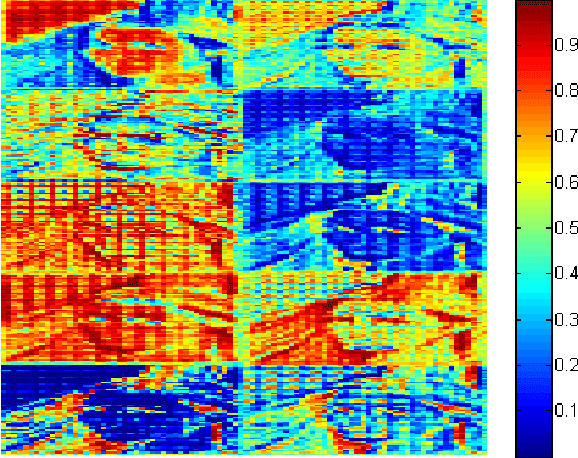
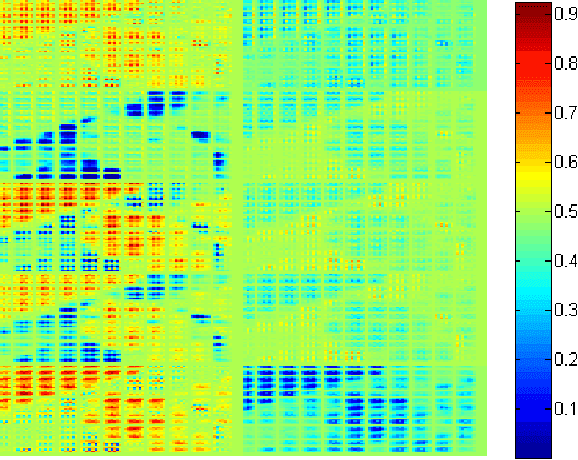
Face restoration from low resolution and noise is important for applications of face analysis recognition. However, most existing face restoration models omit the multiple scale issues in face restoration problem, which is still not well-solved in research area. In this paper, we propose a Sequential Gating Ensemble Network (SGEN) for multi-scale noise robust face restoration issue. To endow the network with multi-scale representation ability, we first employ the principle of ensemble learning for SGEN network architecture designing. The SGEN aggregates multi-level base-encoders and base-decoders into the network, which enables the network to contain multiple scales of receptive field. Instead of combining these base-en/decoders directly with non-sequential operations, the SGEN takes base-en/decoders from different levels as sequential data. Specifically, it is visualized that SGEN learns to sequentially extract high level information from base-encoders in bottom-up manner and restore low level information from base-decoders in top-down manner. Besides, we propose to realize bottom-up and top-down information combination and selection with Sequential Gating Unit (SGU). The SGU sequentially takes information from two different levels as inputs and decides the output based on one active input. Experiment results on benchmark dataset demonstrate that our SGEN is more effective at multi-scale human face restoration with more image details and less noise than state-of-the-art image restoration models. Further utilizing adversarial training scheme, SGEN also produces more visually preferred results than other models under subjective evaluation.
Unsupervised Single Image Deraining with Self-supervised Constraints
Nov 21, 2018
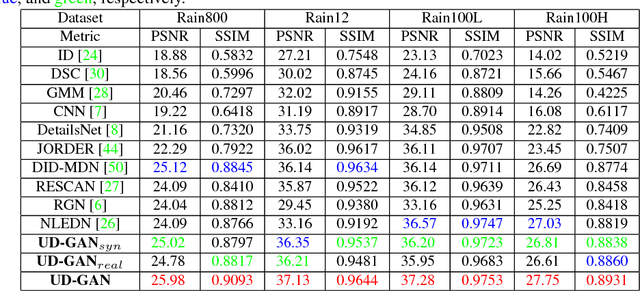

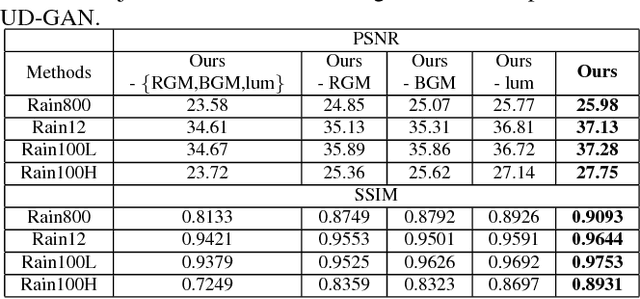
Most existing single image deraining methods require learning supervised models from a large set of paired synthetic training data, which limits their generality, scalability and practicality in real-world multimedia applications. Besides, due to lack of labeled-supervised constraints, directly applying existing unsupervised frameworks to the image deraining task will suffer from low-quality recovery. Therefore, we propose an Unsupervised Deraining Generative Adversarial Network (UD-GAN) to tackle above problems by introducing self-supervised constraints from the intrinsic statistics of unpaired rainy and clean images. Specifically, we firstly design two collaboratively optimized modules, namely Rain Guidance Module (RGM) and Background Guidance Module (BGM), to take full advantage of rainy image characteristics: The RGM is designed to discriminate real rainy images from fake rainy images which are created based on outputs of the generator with BGM. Simultaneously, the BGM exploits a hierarchical Gaussian-Blur gradient error to ensure background consistency between rainy input and de-rained output. Secondly, a novel luminance-adjusting adversarial loss is integrated into the clean image discriminator considering the built-in luminance difference between real clean images and derained images. Comprehensive experiment results on various benchmarking datasets and different training settings show that UD-GAN outperforms existing image deraining methods in both quantitative and qualitative comparisons.