 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual-Seeker: Towards Visual-Native Multimodal Agentic Search via Active Visual Reasoning
Jun 13, 2026Multimodal large language models (MLLMs) have demonstrated impressive capabilities in many visual tasks, but they often struggle with factual grounding when confronted with complex, open-world scenarios. While recent multimodal deep search agents attempt to address this issue by utilizing external tools, the visual-native search paradigm remains underexplored. Existing methods primarily rely on simple images with explicit semantics and text-only evidence trajectories, limiting the agent's ability to perform multi-hop, cross-modal reasoning and search. To address these limitations, we propose Visual-Seeker, a visual-native multimodal deep search agent via active visual reasoning. Rather than treating vision as a static input, our agent actively attends to fine-grained visual details, dynamically harvests visual evidence throughout the search process. To unlock its visual-native potential, we design an active visual reasoning data pipeline and synthesize 5K high-quality multimodal trajectories for model training. Extensive experiments demonstrate the state-of-the-art performance across five challenging multimodal search benchmarks, even surpassing several proprietary models, validating robust visual-native reasoning and search in real-world web environments. The code and data can be accessed at: https://github.com/ZhengboZhang/Visual-Seeker.
Supervised and Semi-Supervised Deep Neural Networks for CSI-Based Authentication
Jul 25, 2018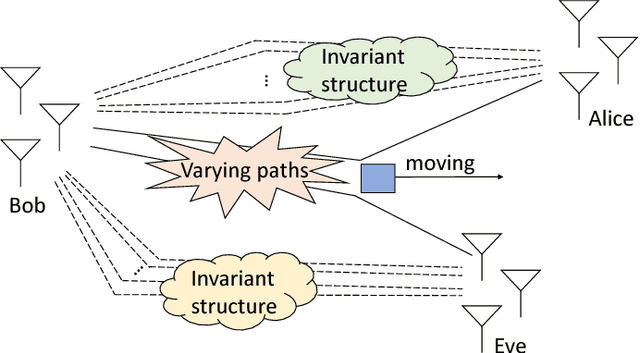
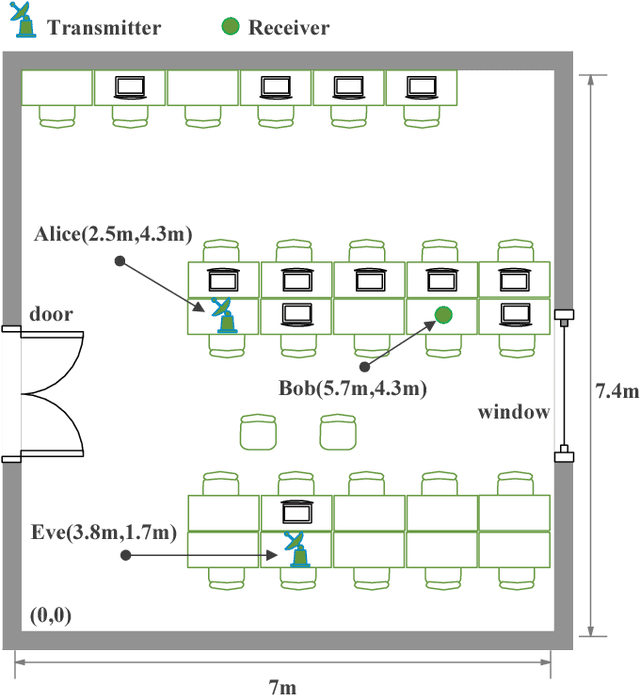
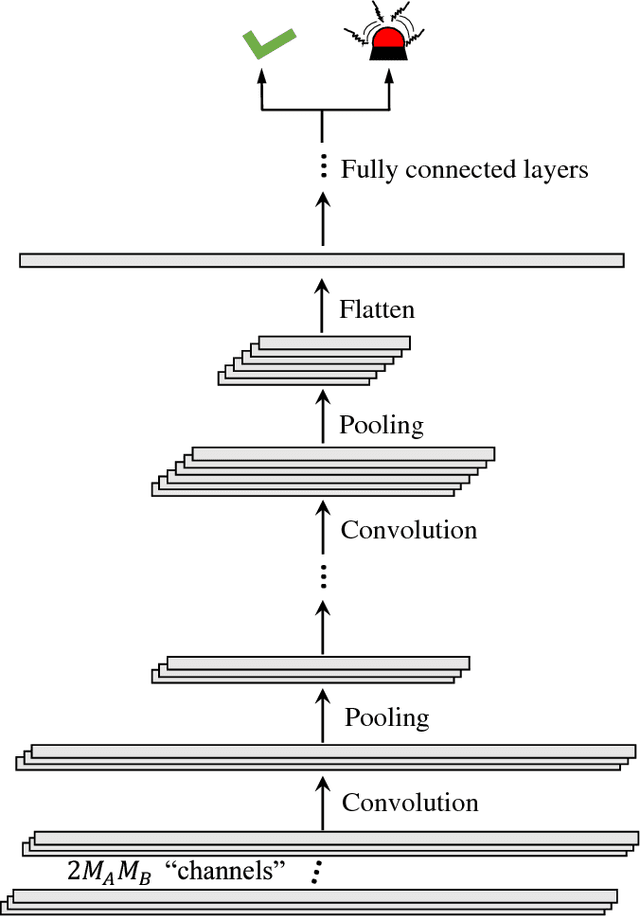
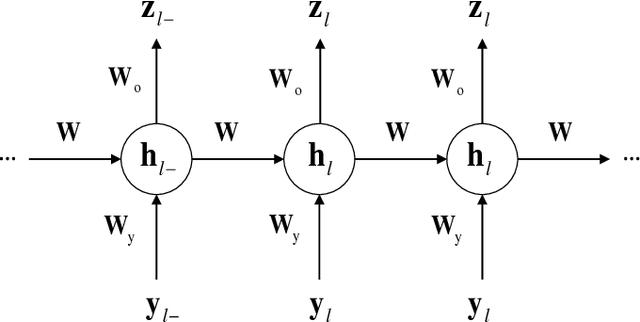
From the viewpoint of physical-layer authentication, spoofing attacks can be foiled by checking channel state information (CSI). Existing CSI-based authentication algorithms mostly require a deep knowledge of the channel to deliver decent performance. In this paper, we investigate CSI-based authenticators that can spare the effort to predetermine channel properties by utilizing deep neural networks (DNNs). We first propose a convolutional neural network (CNN)-enabled authenticator that is able to extract the local features in CSI. Next, we employ the recurrent neural network (RNN) to capture the dependencies between different frequencies in CSI. In addition, we propose to use the convolutional recurrent neural network (CRNN)---a combination of the CNN and the RNN---to learn local and contextual information in CSI for user authentication. To effectively train these DNNs, one needs a large amount of labeled channel records. However, it is often expensive to label large channel observations in the presence of a spoofer. In view of this, we further study a case in which only a small part of the the channel observations are labeled. To handle it, we extend these DNNs-enabled approaches into semi-supervised ones. This extension is based on a semi-supervised learning technique that employs both the labeled and unlabeled data to train a DNN. To be specific, our semi-supervised method begins by generating pseudo labels for the unlabeled channel samples through implementing the K-means algorithm in a semi-supervised manner. Subsequently, both the labeled and pseudo labeled data are exploited to pre-train a DNN, which is then fine-tuned based on the labeled channel records.