 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Representing Mixed-Integer Linear Programs by Graph Neural Networks
Oct 19, 2022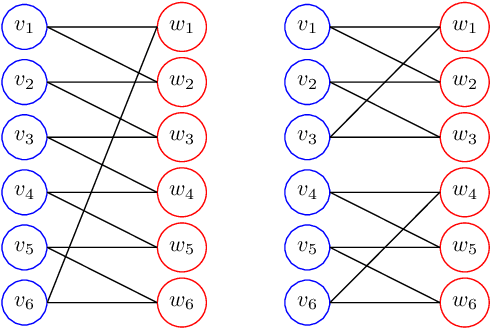
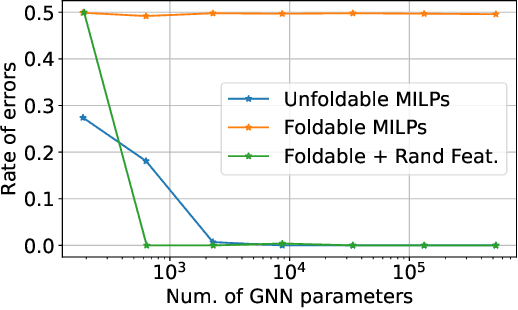
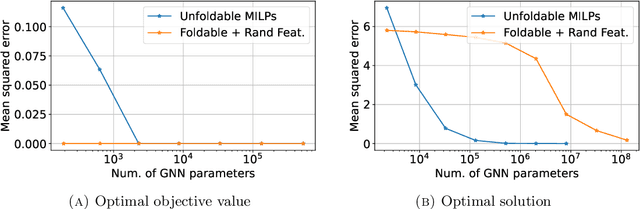
While Mixed-integer linear programming (MILP) is NP-hard in general, practical MILP has received roughly 100--fold speedup in the past twenty years. Still, many classes of MILPs quickly become unsolvable as their sizes increase, motivating researchers to seek new acceleration techniques for MILPs. With deep learning, they have obtained strong empirical results, and many results were obtained by applying graph neural networks (GNNs) to making decisions in various stages of MILP solution processes. This work discovers a fundamental limitation: there exist feasible and infeasible MILPs that all GNNs will, however, treat equally, indicating GNN's lacking power to express general MILPs. Then, we show that, by restricting the MILPs to unfoldable ones or by adding random features, there exist GNNs that can reliably predict MILP feasibility, optimal objective values, and optimal solutions up to prescribed precision. We conducted small-scale numerical experiments to validate our theoretical findings.
Human Joint Kinematics Diffusion-Refinement for Stochastic Motion Prediction
Oct 12, 2022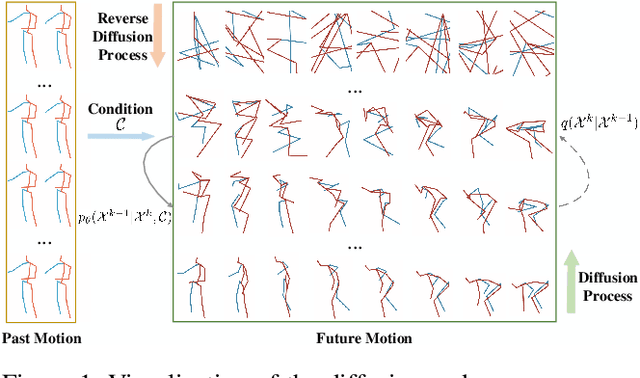
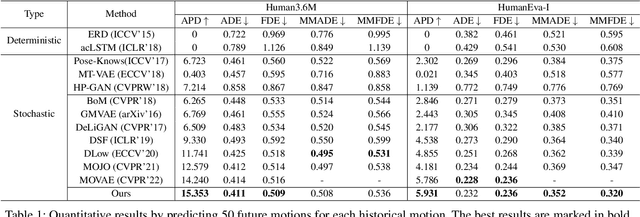
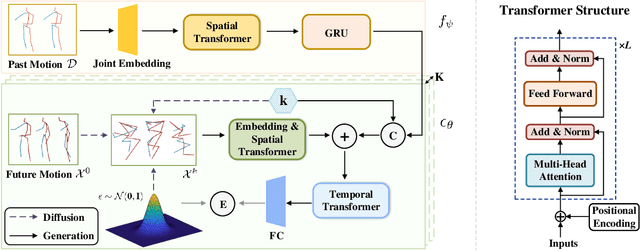

Stochastic human motion prediction aims to forecast multiple plausible future motions given a single pose sequence from the past. Most previous works focus on designing elaborate losses to improve the accuracy, while the diversity is typically characterized by randomly sampling a set of latent variables from the latent prior, which is then decoded into possible motions. This joint training of sampling and decoding, however, suffers from posterior collapse as the learned latent variables tend to be ignored by a strong decoder, leading to limited diversity. Alternatively, inspired by the diffusion process in nonequilibrium thermodynamics, we propose MotionDiff, a diffusion probabilistic model to treat the kinematics of human joints as heated particles, which will diffuse from original states to a noise distribution. This process offers a natural way to obtain the "whitened" latents without any trainable parameters, and human motion prediction can be regarded as the reverse diffusion process that converts the noise distribution into realistic future motions conditioned on the observed sequence. Specifically, MotionDiff consists of two parts: a spatial-temporal transformer-based diffusion network to generate diverse yet plausible motions, and a graph convolutional network to further refine the outputs. Experimental results on two datasets demonstrate that our model yields the competitive performance in terms of both accuracy and diversity.
Convergence of score-based generative modeling for general data distributions
Oct 03, 2022Score-based generative modeling (SGM) has grown to be a hugely successful method for learning to generate samples from complex data distributions such as that of images and audio. It is based on evolving an SDE that transforms white noise into a sample from the learned distribution, using estimates of the score function, or gradient log-pdf. Previous convergence analyses for these methods have suffered either from strong assumptions on the data distribution or exponential dependencies, and hence fail to give efficient guarantees for the multimodal and non-smooth distributions that arise in practice and for which good empirical performance is observed. We consider a popular kind of SGM -- denoising diffusion models -- and give polynomial convergence guarantees for general data distributions, with no assumptions related to functional inequalities or smoothness. Assuming $L^2$-accurate score estimates, we obtain Wasserstein distance guarantees for any distribution of bounded support or sufficiently decaying tails, as well as TV guarantees for distributions with further smoothness assumptions.
On Representing Linear Programs by Graph Neural Networks
Sep 25, 2022
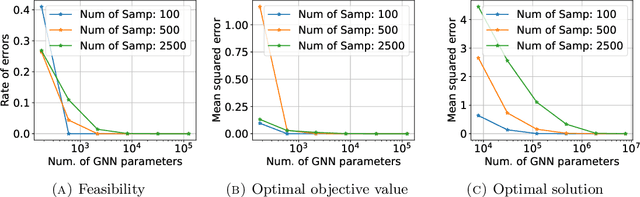
Learning to optimize is a rapidly growing area that aims to solve optimization problems or improve existing optimization algorithms using machine learning (ML). In particular, the graph neural network (GNN) is considered a suitable ML model for optimization problems whose variables and constraints are permutation--invariant, for example, the linear program (LP). While the literature has reported encouraging numerical results, this paper establishes the theoretical foundation of applying GNNs to solving LPs. Given any size limit of LPs, we construct a GNN that maps different LPs to different outputs. We show that properly built GNNs can reliably predict feasibility, boundedness, and an optimal solution for each LP in a broad class. Our proofs are based upon the recently--discovered connections between the Weisfeiler--Lehman isomorphism test and the GNN. To validate our results, we train a simple GNN and present its accuracy in mapping LPs to their feasibilities and solutions.
A deep learning framework for geodesics under spherical Wasserstein-Fisher-Rao metric and its application for weighted sample generation
Aug 25, 2022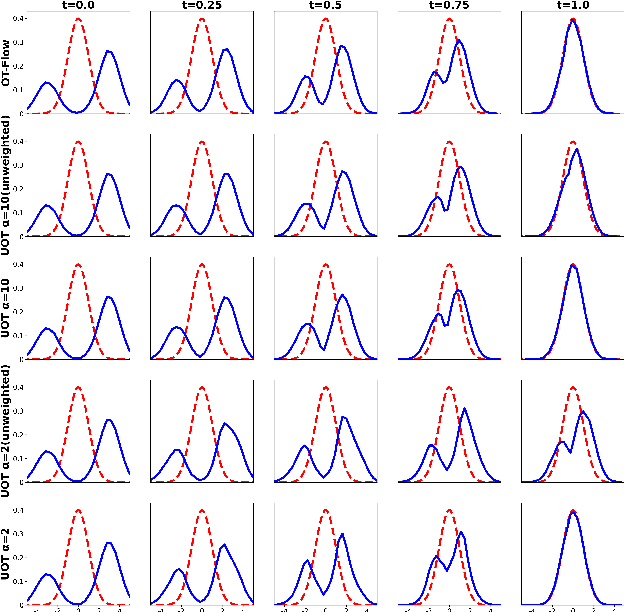
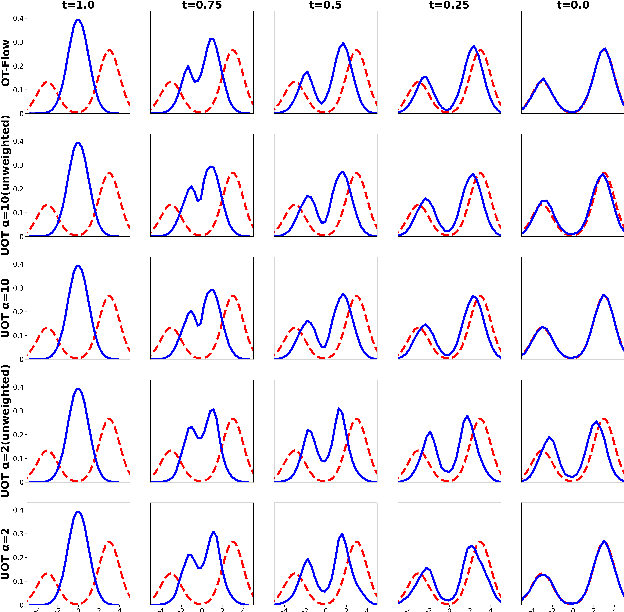
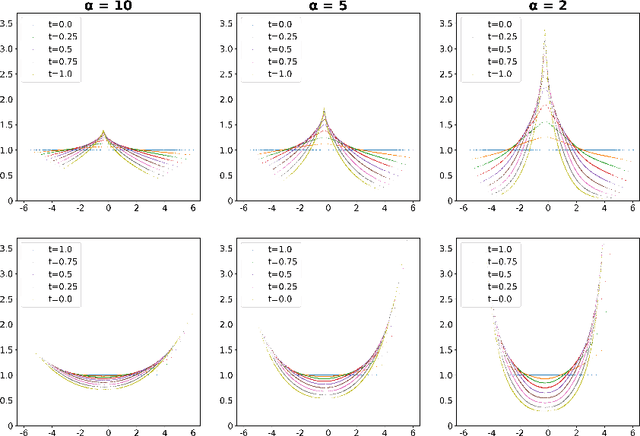
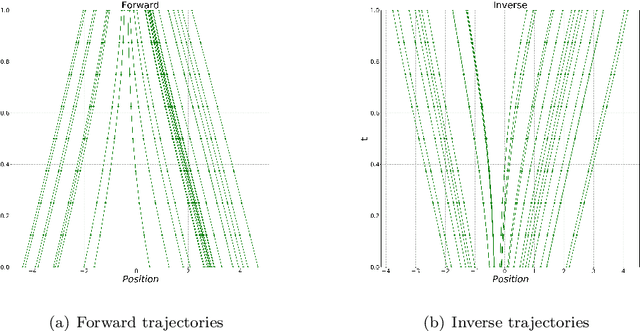
Wasserstein-Fisher-Rao (WFR) distance is a family of metrics to gauge the discrepancy of two Radon measures, which takes into account both transportation and weight change. Spherical WFR distance is a projected version of WFR distance for probability measures so that the space of Radon measures equipped with WFR can be viewed as metric cone over the space of probability measures with spherical WFR. Compared to the case for Wasserstein distance, the understanding of geodesics under the spherical WFR is less clear and still an ongoing research focus. In this paper, we develop a deep learning framework to compute the geodesics under the spherical WFR metric, and the learned geodesics can be adopted to generate weighted samples. Our approach is based on a Benamou-Brenier type dynamic formulation for spherical WFR. To overcome the difficulty in enforcing the boundary constraint brought by the weight change, a Kullback-Leibler (KL) divergence term based on the inverse map is introduced into the cost function. Moreover, a new regularization term using the particle velocity is introduced as a substitute for the Hamilton-Jacobi equation for the potential in dynamic formula. When used for sample generation, our framework can be beneficial for applications with given weighted samples, especially in the Bayesian inference, compared to sample generation with previous flow models.
MonoPCNS: Monocular 3D Object Detection via Point Cloud Network Simulation
Aug 19, 2022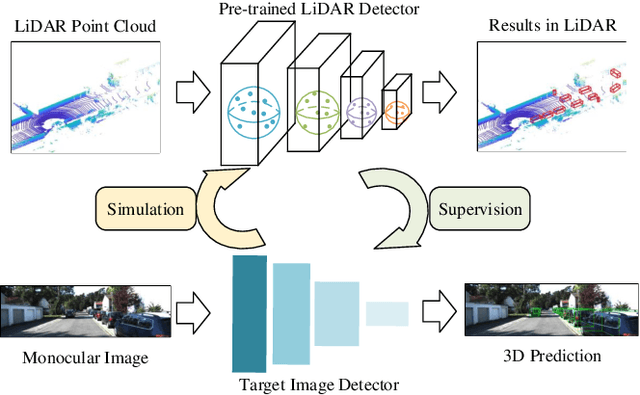
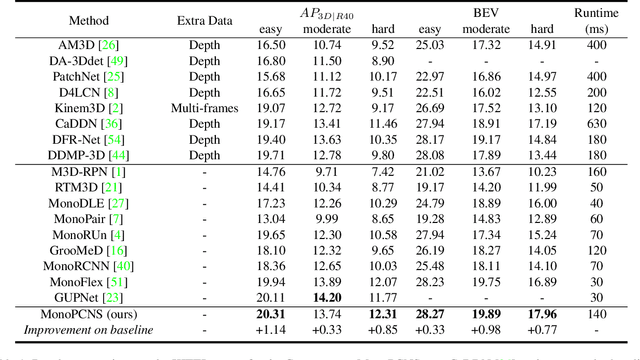
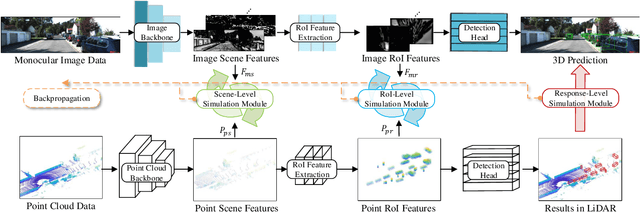
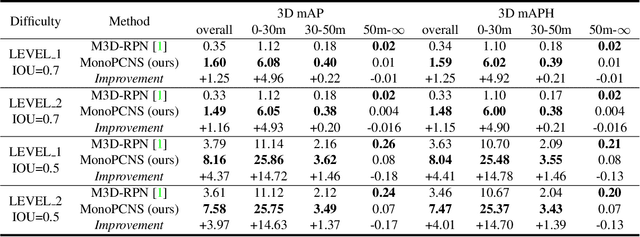
Monocular 3D object detection is a fundamental but very important task to many applications including autonomous driving, robotic grasping and augmented reality. Existing leading methods tend to estimate the depth of the input image first, and detect the 3D object based on point cloud. This routine suffers from the inherent gap between depth estimation and object detection. Besides, the prediction error accumulation would also affect the performance. In this paper, a novel method named MonoPCNS is proposed. The insight behind introducing MonoPCNS is that we propose to simulate the feature learning behavior of a point cloud based detector for monocular detector during the training period. Hence, during inference period, the learned features and prediction would be similar to the point cloud based detector as possible. To achieve it, we propose one scene-level simulation module, one RoI-level simulation module and one response-level simulation module, which are progressively used for the detector's full feature learning and prediction pipeline. We apply our method to the famous M3D-RPN detector and CaDDN detector, conducting extensive experiments on KITTI and Waymo Open dataset. Results show that our method consistently improves the performance of different monocular detectors for a large margin without changing their network architectures. Our method finally achieves state-of-the-art performance.
Overlooked Poses Actually Make Sense: Distilling Privileged Knowledge for Human Motion Prediction
Aug 02, 2022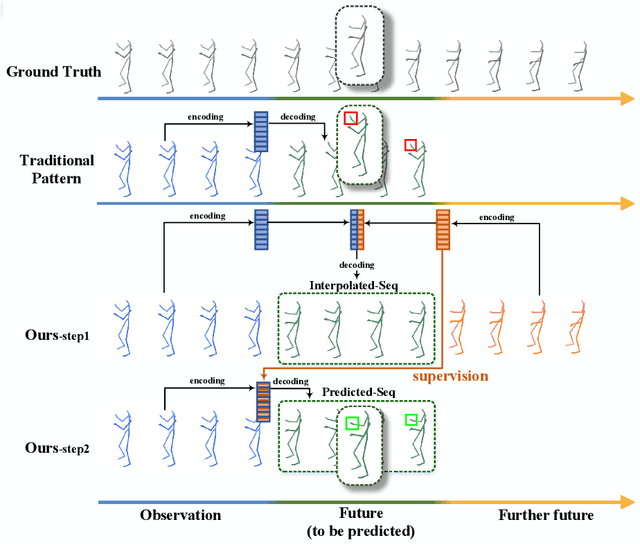
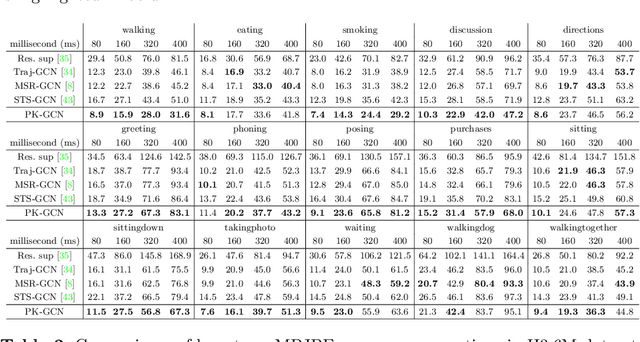
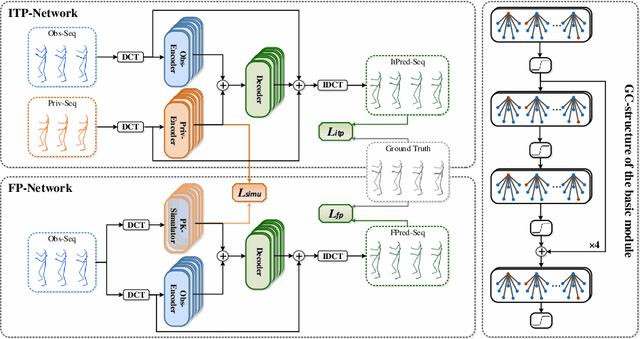
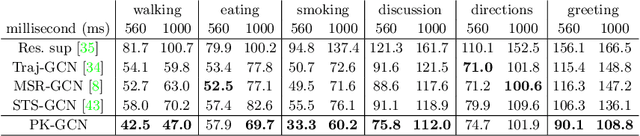
Previous works on human motion prediction follow the pattern of building a mapping relation between the sequence observed and the one to be predicted. However, due to the inherent complexity of multivariate time series data, it still remains a challenge to find the extrapolation relation between motion sequences. In this paper, we present a new prediction pattern, which introduces previously overlooked human poses, to implement the prediction task from the view of interpolation. These poses exist after the predicted sequence, and form the privileged sequence. To be specific, we first propose an InTerPolation learning Network (ITP-Network) that encodes both the observed sequence and the privileged sequence to interpolate the in-between predicted sequence, wherein the embedded Privileged-sequence-Encoder (Priv-Encoder) learns the privileged knowledge (PK) simultaneously. Then, we propose a Final Prediction Network (FP-Network) for which the privileged sequence is not observable, but is equipped with a novel PK-Simulator that distills PK learned from the previous network. This simulator takes as input the observed sequence, but approximates the behavior of Priv-Encoder, enabling FP-Network to imitate the interpolation process. Extensive experimental results demonstrate that our prediction pattern achieves state-of-the-art performance on benchmarked H3.6M, CMU-Mocap and 3DPW datasets in both short-term and long-term predictions.
Convergence for score-based generative modeling with polynomial complexity
Jun 13, 2022Score-based generative modeling (SGM) is a highly successful approach for learning a probability distribution from data and generating further samples. We prove the first polynomial convergence guarantees for the core mechanic behind SGM: drawing samples from a probability density $p$ given a score estimate (an estimate of $\nabla \ln p$) that is accurate in $L^2(p)$. Compared to previous works, we do not incur error that grows exponentially in time or that suffers from a curse of dimensionality. Our guarantee works for any smooth distribution and depends polynomially on its log-Sobolev constant. Using our guarantee, we give a theoretical analysis of score-based generative modeling, which transforms white-noise input into samples from a learned data distribution given score estimates at different noise scales. Our analysis gives theoretical grounding to the observation that an annealed procedure is required in practice to generate good samples, as our proof depends essentially on using annealing to obtain a warm start at each step. Moreover, we show that a predictor-corrector algorithm gives better convergence than using either portion alone.
Single Time-scale Actor-critic Method to Solve the Linear Quadratic Regulator with Convergence Guarantees
Jan 31, 2022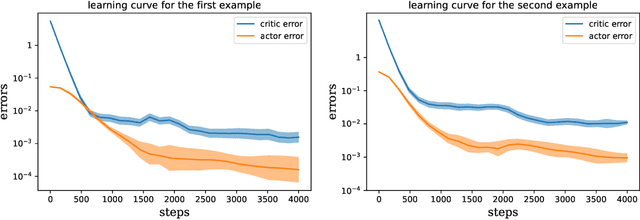
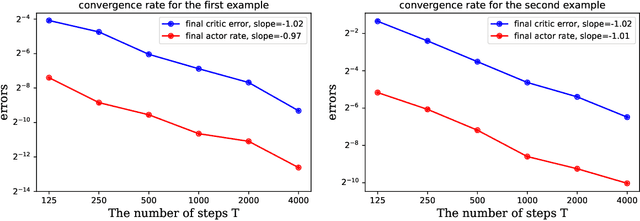
We propose a single time-scale actor-critic algorithm to solve the linear quadratic regulator (LQR) problem. A least squares temporal difference (LSTD) method is applied to the critic and a natural policy gradient method is used for the actor. We give a proof of convergence with sample complexity $\mO(\ve^{-1} \log(\ve^{-1})^2)$. The method in the proof is applicable to general single time-scale bilevel optimization problem. We also numerically validate our theoretical results on the convergence.
A Regularity Theory for Static Schrödinger Equations on $\mathbb{R}^d$ in Spectral Barron Spaces
Jan 25, 2022Spectral Barron spaces have received considerable interest recently as it is the natural function space for approximation theory of two-layer neural networks with a dimension-free convergence rate. In this paper we study the regularity of solutions to the whole-space static Schr\"odinger equation in spectral Barron spaces. We prove that if the source of the equation lies in the spectral Barron space $\mathcal{B}^s(\mathbb{R}^d)$ and the potential function admitting a non-negative lower bound decomposes as a positive constant plus a function in $\mathcal{B}^s(\mathbb{R}^d)$, then the solution lies in the spectral Barron space $\mathcal{B}^{s+2}(\mathbb{R}^d)$.