 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Multiscale Learning of Linear Operators
Jun 15, 2026We study the statistical and computational limits of learning bounded linear operators between Sobolev spaces from noisy input-output data. In wavelet coordinates, the problem is recast as an infinite-dimensional matrix regression problem with a heterogeneous two-sided multiscale structure. We establish minimax rates under Sobolev operator-norm loss and construct a finite-resolution blockwise least-squares estimator attaining these rates. The analysis reveals a nonuniform local estimation difficulty across scales, which can be exploited algorithmically: by assigning scale-adaptive sample sizes, the estimator achieves the optimal computational cost among dense least-squares implementations.
ATM: Action-Consistency Transfer Matrix for Diagnosing and Improving Latent World Models
Jun 08, 2026Latent world models are increasingly used for control and goal-conditioned planning, yet assessing whether their learned representations are useful for planning usually requires slow, planner-coupled simulator evaluation with CEM or similar planners. Such evaluation is black-box and model-complexity-dependent: under the same protocol, different world models may require minutes to hours per checkpoint. In this work, we propose ATM, an Action-Consistency Transfer Matrix for diagnosing whether latent transitions preserve action semantics relevant to planning. ATM compares action information in real encoded transitions and model-predicted transitions through lightweight post-hoc probes, producing an interpretable matrix that reveals representation quality, transition-domain inconsistency, and failure modes without simulator rollout. It can also be collapsed into a simple screening score for within-task ranking across checkpoints, variants, and world models. When the true success gap is non-trivial, ATM achieves highly reliable pairwise ranking, while reducing minutes-to-hours CEM evaluation to seconds-level transition analysis, yielding more than 100x speedup in our setup. We further introduce AITS, showing that action-identifiability is not only diagnostic but also a useful training signal for improving downstream planning without changing the planner.
Convergence Rates for Learning Pseudo-Differential Operators
Jan 08, 2026This paper establishes convergence rates for learning elliptic pseudo-differential operators, a fundamental operator class in partial differential equations and mathematical physics. In a wavelet-Galerkin framework, we formulate learning over this class as a structured infinite-dimensional regression problem with multiscale sparsity. Building on this structure, we propose a sparse, data- and computation-efficient estimator, which leverages a novel matrix compression scheme tailored to the learning task and a nested-support strategy to balance approximation and estimation errors. In addition to obtaining convergence rates for the estimator, we show that the learned operator induces an efficient and stable Galerkin solver whose numerical error matches its statistical accuracy. Our results therefore contribute to bringing together operator learning, data-driven solvers, and wavelet methods in scientific computing.
A deep learning framework for geodesics under spherical Wasserstein-Fisher-Rao metric and its application for weighted sample generation
Aug 25, 2022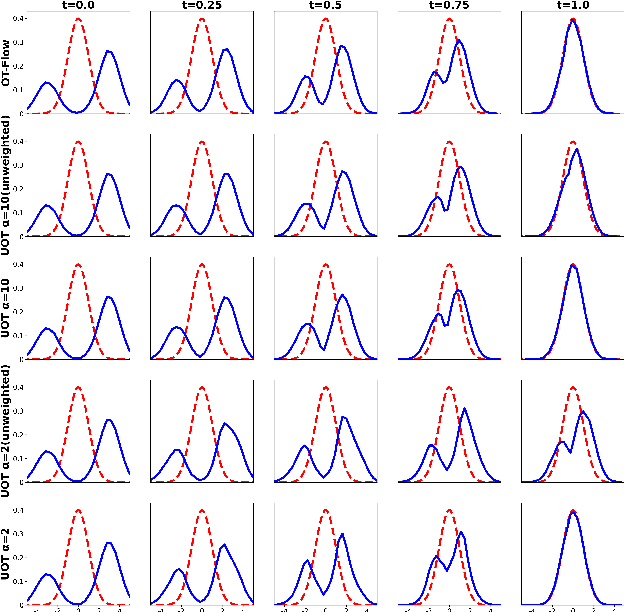
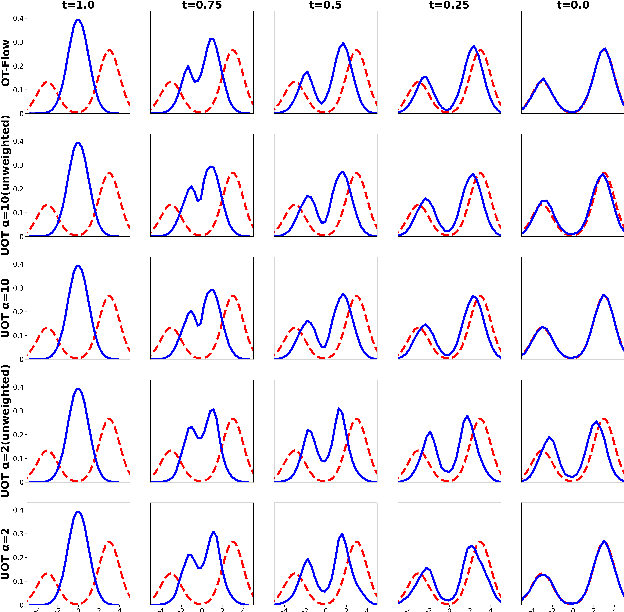
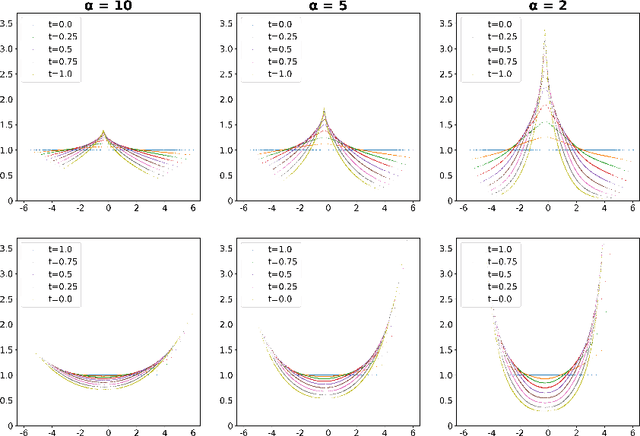
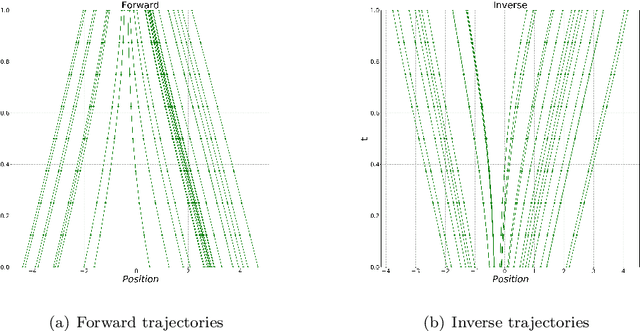
Wasserstein-Fisher-Rao (WFR) distance is a family of metrics to gauge the discrepancy of two Radon measures, which takes into account both transportation and weight change. Spherical WFR distance is a projected version of WFR distance for probability measures so that the space of Radon measures equipped with WFR can be viewed as metric cone over the space of probability measures with spherical WFR. Compared to the case for Wasserstein distance, the understanding of geodesics under the spherical WFR is less clear and still an ongoing research focus. In this paper, we develop a deep learning framework to compute the geodesics under the spherical WFR metric, and the learned geodesics can be adopted to generate weighted samples. Our approach is based on a Benamou-Brenier type dynamic formulation for spherical WFR. To overcome the difficulty in enforcing the boundary constraint brought by the weight change, a Kullback-Leibler (KL) divergence term based on the inverse map is introduced into the cost function. Moreover, a new regularization term using the particle velocity is introduced as a substitute for the Hamilton-Jacobi equation for the potential in dynamic formula. When used for sample generation, our framework can be beneficial for applications with given weighted samples, especially in the Bayesian inference, compared to sample generation with previous flow models.