 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDefense Against Model Stealing Based on Account-Aware Distribution Discrepancy
Mar 16, 2025



Malicious users attempt to replicate commercial models functionally at low cost by training a clone model with query responses. It is challenging to timely prevent such model-stealing attacks to achieve strong protection and maintain utility. In this paper, we propose a novel non-parametric detector called Account-aware Distribution Discrepancy (ADD) to recognize queries from malicious users by leveraging account-wise local dependency. We formulate each class as a Multivariate Normal distribution (MVN) in the feature space and measure the malicious score as the sum of weighted class-wise distribution discrepancy. The ADD detector is combined with random-based prediction poisoning to yield a plug-and-play defense module named D-ADD for image classification models. Results of extensive experimental studies show that D-ADD achieves strong defense against different types of attacks with little interference in serving benign users for both soft and hard-label settings.
Conditional Image Synthesis with Diffusion Models: A Survey
Sep 28, 2024



Conditional image synthesis based on user-specified requirements is a key component in creating complex visual content. In recent years, diffusion-based generative modeling has become a highly effective way for conditional image synthesis, leading to exponential growth in the literature. However, the complexity of diffusion-based modeling, the wide range of image synthesis tasks, and the diversity of conditioning mechanisms present significant challenges for researchers to keep up with rapid developments and understand the core concepts on this topic. In this survey, we categorize existing works based on how conditions are integrated into the two fundamental components of diffusion-based modeling, i.e., the denoising network and the sampling process. We specifically highlight the underlying principles, advantages, and potential challenges of various conditioning approaches in the training, re-purposing, and specialization stages to construct a desired denoising network. We also summarize six mainstream conditioning mechanisms in the essential sampling process. All discussions are centered around popular applications. Finally, we pinpoint some critical yet still open problems to be solved in the future and suggest some possible solutions. Our reviewed works are itemized at https://github.com/zju-pi/Awesome-Conditional-Diffusion-Models.
A Geometric Perspective on Diffusion Models
May 31, 2023Recent years have witnessed significant progress in developing efficient training and fast sampling approaches for diffusion models. A recent remarkable advancement is the use of stochastic differential equations (SDEs) to describe data perturbation and generative modeling in a unified mathematical framework. In this paper, we reveal several intriguing geometric structures of diffusion models and contribute a simple yet powerful interpretation to their sampling dynamics. Through carefully inspecting a popular variance-exploding SDE and its marginal-preserving ordinary differential equation (ODE) for sampling, we discover that the data distribution and the noise distribution are smoothly connected with an explicit, quasi-linear sampling trajectory, and another implicit denoising trajectory, which even converges faster in terms of visual quality. We also establish a theoretical relationship between the optimal ODE-based sampling and the classic mean-shift (mode-seeking) algorithm, with which we can characterize the asymptotic behavior of diffusion models and identify the score deviation. These new geometric observations enable us to improve previous sampling algorithms, re-examine latent interpolation, as well as re-explain the working principles of distillation-based fast sampling techniques.
Knowledge Distillation with the Reused Teacher Classifier
Mar 26, 2022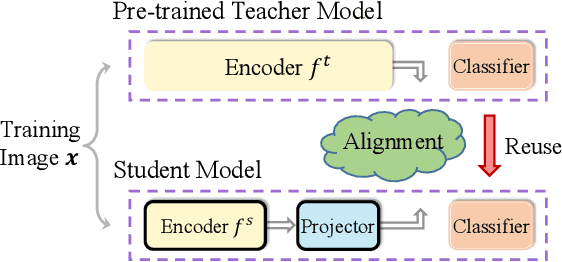
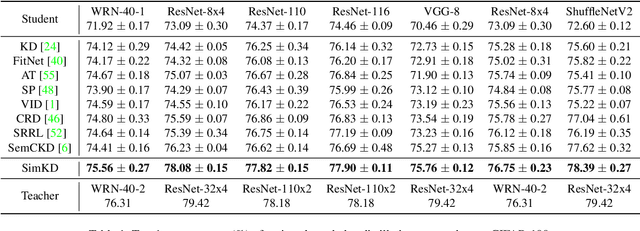

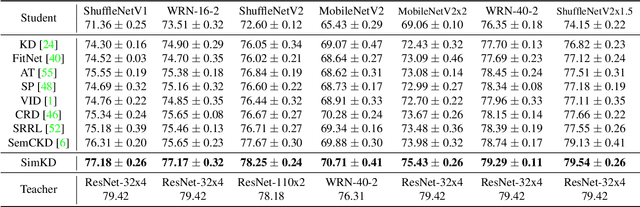
Knowledge distillation aims to compress a powerful yet cumbersome teacher model into a lightweight student model without much sacrifice of performance. For this purpose, various approaches have been proposed over the past few years, generally with elaborately designed knowledge representations, which in turn increase the difficulty of model development and interpretation. In contrast, we empirically show that a simple knowledge distillation technique is enough to significantly narrow down the teacher-student performance gap. We directly reuse the discriminative classifier from the pre-trained teacher model for student inference and train a student encoder through feature alignment with a single $\ell_2$ loss. In this way, the student model is able to achieve exactly the same performance as the teacher model provided that their extracted features are perfectly aligned. An additional projector is developed to help the student encoder match with the teacher classifier, which renders our technique applicable to various teacher and student architectures. Extensive experiments demonstrate that our technique achieves state-of-the-art results at the modest cost of compression ratio due to the added projector.
Cross-Layer Distillation with Semantic Calibration
Dec 06, 2020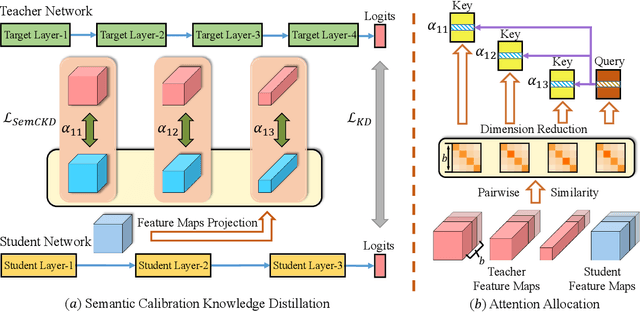
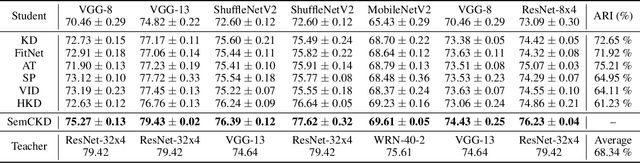
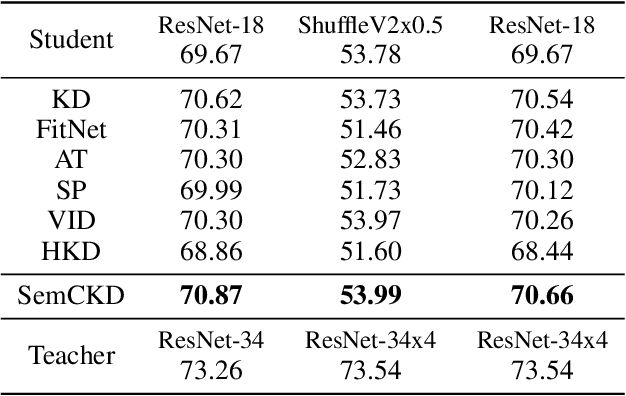
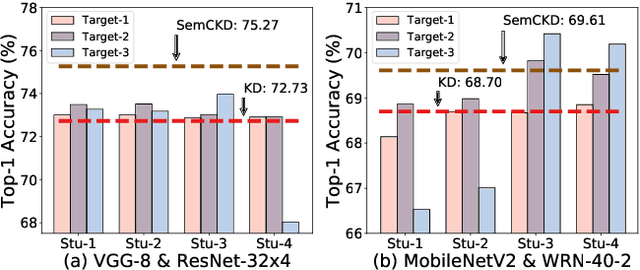
Recently proposed knowledge distillation approaches based on feature-map transfer validate that intermediate layers of a teacher model can serve as effective targets for training a student model to obtain better generalization ability. Existing studies mainly focus on particular representation forms for knowledge transfer between manually specified pairs of teacher-student intermediate layers. However, semantics of intermediate layers may vary in different networks and manual association of layers might lead to negative regularization caused by semantic mismatch between certain teacher-student layer pairs. To address this problem, we propose Semantic Calibration for Cross-layer Knowledge Distillation (SemCKD), which automatically assigns proper target layers of the teacher model for each student layer with an attention mechanism. With a learned attention distribution, each student layer distills knowledge contained in multiple layers rather than a single fixed intermediate layer from the teacher model for appropriate cross-layer supervision in training. Consistent improvements over state-of-the-art approaches are observed in extensive experiments with various network architectures for teacher and student models, demonstrating the effectiveness and flexibility of the proposed attention based soft layer association mechanism for cross-layer distillation.
Online Knowledge Distillation with Diverse Peers
Dec 05, 2019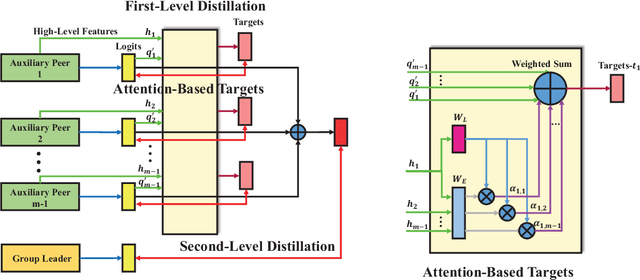


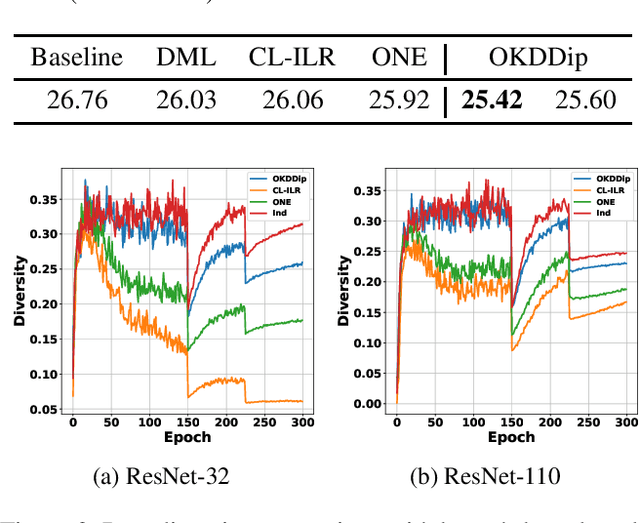
Distillation is an effective knowledge-transfer technique that uses predicted distributions of a powerful teacher model as soft targets to train a less-parameterized student model. A pre-trained high capacity teacher, however, is not always available. Recently proposed online variants use the aggregated intermediate predictions of multiple student models as targets to train each student model. Although group-derived targets give a good recipe for teacher-free distillation, group members are homogenized quickly with simple aggregation functions, leading to early saturated solutions. In this work, we propose Online Knowledge Distillation with Diverse peers (OKDDip), which performs two-level distillation during training with multiple auxiliary peers and one group leader. In the first-level distillation, each auxiliary peer holds an individual set of aggregation weights generated with an attention-based mechanism to derive its own targets from predictions of other auxiliary peers. Learning from distinct target distributions helps to boost peer diversity for effectiveness of group-based distillation. The second-level distillation is performed to transfer the knowledge in the ensemble of auxiliary peers further to the group leader, i.e., the model used for inference. Experimental results show that the proposed framework consistently gives better performance than state-of-the-art approaches without sacrificing training or inference complexity, demonstrating the effectiveness of the proposed two-level distillation framework.
Classification and its applications for drug-target interaction identification
Mar 12, 2015
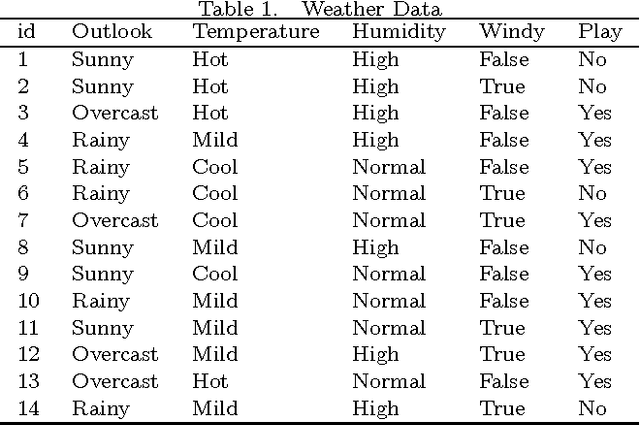
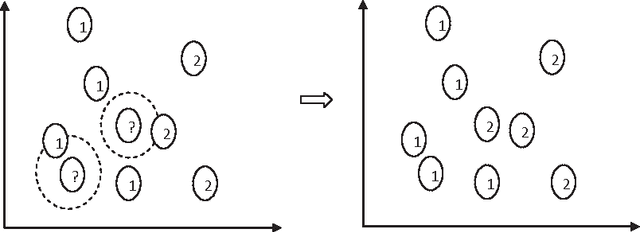

Classification is one of the most popular and widely used supervised learning tasks, which categorizes objects into predefined classes based on known knowledge. Classification has been an important research topic in machine learning and data mining. Different classification methods have been proposed and applied to deal with various real-world problems. Unlike unsupervised learning such as clustering, a classifier is typically trained with labeled data before being used to make prediction, and usually achieves higher accuracy than unsupervised one. In this paper, we first define classification and then review several representative methods. After that, we study in details the application of classification to a critical problem in drug discovery, i.e., drug-target prediction, due to the challenges in predicting possible interactions between drugs and targets.