 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time Cell Sorting with Scalable In Situ FPGA-Accelerated Deep Learning
Mar 16, 2025Precise cell classification is essential in biomedical diagnostics and therapeutic monitoring, particularly for identifying diverse cell types involved in various diseases. Traditional cell classification methods such as flow cytometry depend on molecular labeling which is often costly, time-intensive, and can alter cell integrity. To overcome these limitations, we present a label-free machine learning framework for cell classification, designed for real-time sorting applications using bright-field microscopy images. This approach leverages a teacher-student model architecture enhanced by knowledge distillation, achieving high efficiency and scalability across different cell types. Demonstrated through a use case of classifying lymphocyte subsets, our framework accurately classifies T4, T8, and B cell types with a dataset of 80,000 preprocessed images, accessible via an open-source Python package for easy adaptation. Our teacher model attained 98\% accuracy in differentiating T4 cells from B cells and 93\% accuracy in zero-shot classification between T8 and B cells. Remarkably, our student model operates with only 0.02\% of the teacher model's parameters, enabling field-programmable gate array (FPGA) deployment. Our FPGA-accelerated student model achieves an ultra-low inference latency of just 14.5~$\mu$s and a complete cell detection-to-sorting trigger time of 24.7~$\mu$s, delivering 12x and 40x improvements over the previous state-of-the-art real-time cell analysis algorithm in inference and total latency, respectively, while preserving accuracy comparable to the teacher model. This framework provides a scalable, cost-effective solution for lymphocyte classification, as well as a new SOTA real-time cell sorting implementation for rapid identification of subsets using in situ deep learning on off-the-shelf computing hardware.
DeepSuM: Deep Sufficient Modality Learning Framework
Mar 03, 2025



Multimodal learning has become a pivotal approach in developing robust learning models with applications spanning multimedia, robotics, large language models, and healthcare. The efficiency of multimodal systems is a critical concern, given the varying costs and resource demands of different modalities. This underscores the necessity for effective modality selection to balance performance gains against resource expenditures. In this study, we propose a novel framework for modality selection that independently learns the representation of each modality. This approach allows for the assessment of each modality's significance within its unique representation space, enabling the development of tailored encoders and facilitating the joint analysis of modalities with distinct characteristics. Our framework aims to enhance the efficiency and effectiveness of multimodal learning by optimizing modality integration and selection.
Transfer Learning through Enhanced Sufficient Representation: Enriching Source Domain Knowledge with Target Data
Feb 22, 2025



Transfer learning is an important approach for addressing the challenges posed by limited data availability in various applications. It accomplishes this by transferring knowledge from well-established source domains to a less familiar target domain. However, traditional transfer learning methods often face difficulties due to rigid model assumptions and the need for a high degree of similarity between source and target domain models. In this paper, we introduce a novel method for transfer learning called Transfer learning through Enhanced Sufficient Representation (TESR). Our approach begins by estimating a sufficient and invariant representation from the source domains. This representation is then enhanced with an independent component derived from the target data, ensuring that it is sufficient for the target domain and adaptable to its specific characteristics. A notable advantage of TESR is that it does not rely on assuming similar model structures across different tasks. For example, the source domain models can be regression models, while the target domain task can be classification. This flexibility makes TESR applicable to a wide range of supervised learning problems. We explore the theoretical properties of TESR and validate its performance through simulation studies and real-world data applications, demonstrating its effectiveness in finite sample settings.
Robot Deformable Object Manipulation via NMPC-generated Demonstrations in Deep Reinforcement Learning
Feb 17, 2025In this work, we conducted research on deformable object manipulation by robots based on demonstration-enhanced reinforcement learning (RL). To improve the learning efficiency of RL, we enhanced the utilization of demonstration data from multiple aspects and proposed the HGCR-DDPG algorithm. It uses a novel high-dimensional fuzzy approach for grasping-point selection, a refined behavior-cloning method to enhance data-driven learning in Rainbow-DDPG, and a sequential policy-learning strategy. Compared to the baseline algorithm (Rainbow-DDPG), our proposed HGCR-DDPG achieved 2.01 times the global average reward and reduced the global average standard deviation to 45% of that of the baseline algorithm. To reduce the human labor cost of demonstration collection, we proposed a low-cost demonstration collection method based on Nonlinear Model Predictive Control (NMPC). Simulation experiment results show that demonstrations collected through NMPC can be used to train HGCR-DDPG, achieving comparable results to those obtained with human demonstrations. To validate the feasibility of our proposed methods in real-world environments, we conducted physical experiments involving deformable object manipulation. We manipulated fabric to perform three tasks: diagonal folding, central axis folding, and flattening. The experimental results demonstrate that our proposed method achieved success rates of 83.3%, 80%, and 100% for these three tasks, respectively, validating the effectiveness of our approach. Compared to current large-model approaches for robot manipulation, the proposed algorithm is lightweight, requires fewer computational resources, and offers task-specific customization and efficient adaptability for specific tasks.
A Survey on Large Language Model-based Agents for Statistics and Data Science
Dec 18, 2024



In recent years, data science agents powered by Large Language Models (LLMs), known as "data agents," have shown significant potential to transform the traditional data analysis paradigm. This survey provides an overview of the evolution, capabilities, and applications of LLM-based data agents, highlighting their role in simplifying complex data tasks and lowering the entry barrier for users without related expertise. We explore current trends in the design of LLM-based frameworks, detailing essential features such as planning, reasoning, reflection, multi-agent collaboration, user interface, knowledge integration, and system design, which enable agents to address data-centric problems with minimal human intervention. Furthermore, we analyze several case studies to demonstrate the practical applications of various data agents in real-world scenarios. Finally, we identify key challenges and propose future research directions to advance the development of data agents into intelligent statistical analysis software.
Embedded Machine Learning for Solar PV Power Regulation in a Remote Microgrid
Dec 02, 2024



This paper presents a machine-learning study for solar inverter power regulation in a remote microgrid. Machine learning models for active and reactive power control are respectively trained using an ensemble learning method. Then, unlike conventional schemes that make inferences on a central server in the far-end control center, the proposed scheme deploys the trained models on an embedded edge-computing device near the inverter to reduce the communication delay. Experiments on a real embedded device achieve matched results as on the desktop PC, with about 0.1ms time cost for each inference input.
Transforming the Hybrid Cloud for Emerging AI Workloads
Nov 20, 2024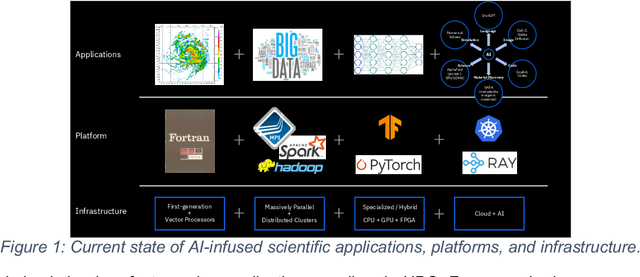
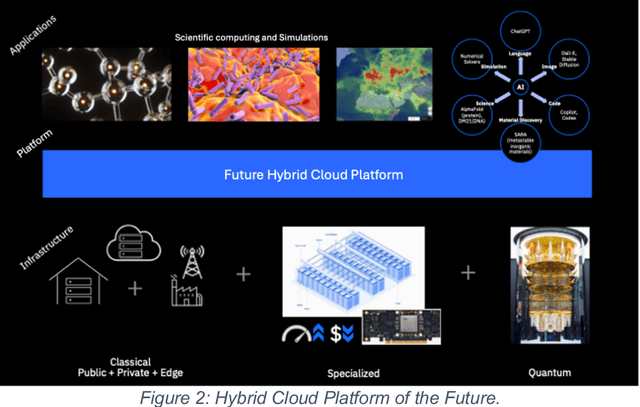
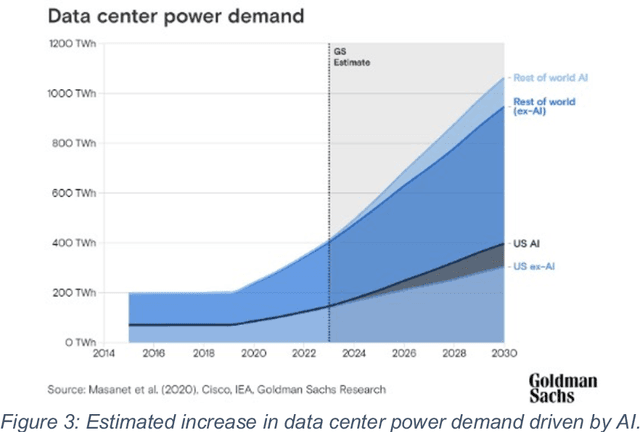
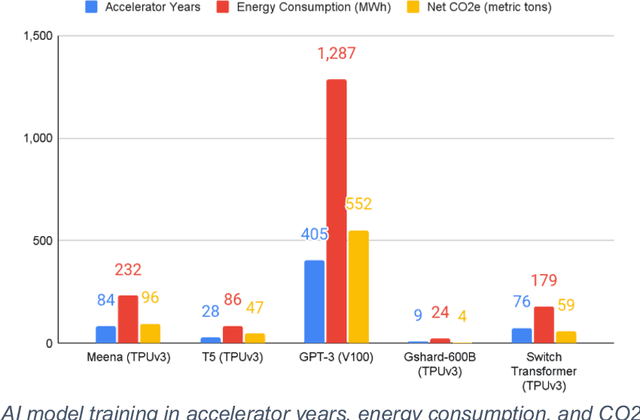
This white paper, developed through close collaboration between IBM Research and UIUC researchers within the IIDAI Institute, envisions transforming hybrid cloud systems to meet the growing complexity of AI workloads through innovative, full-stack co-design approaches, emphasizing usability, manageability, affordability, adaptability, efficiency, and scalability. By integrating cutting-edge technologies such as generative and agentic AI, cross-layer automation and optimization, unified control plane, and composable and adaptive system architecture, the proposed framework addresses critical challenges in energy efficiency, performance, and cost-effectiveness. Incorporating quantum computing as it matures will enable quantum-accelerated simulations for materials science, climate modeling, and other high-impact domains. Collaborative efforts between academia and industry are central to this vision, driving advancements in foundation models for material design and climate solutions, scalable multimodal data processing, and enhanced physics-based AI emulators for applications like weather forecasting and carbon sequestration. Research priorities include advancing AI agentic systems, LLM as an Abstraction (LLMaaA), AI model optimization and unified abstractions across heterogeneous infrastructure, end-to-end edge-cloud transformation, efficient programming model, middleware and platform, secure infrastructure, application-adaptive cloud systems, and new quantum-classical collaborative workflows. These ideas and solutions encompass both theoretical and practical research questions, requiring coordinated input and support from the research community. This joint initiative aims to establish hybrid clouds as secure, efficient, and sustainable platforms, fostering breakthroughs in AI-driven applications and scientific discovery across academia, industry, and society.
OwMatch: Conditional Self-Labeling with Consistency for Open-World Semi-Supervised Learning
Nov 04, 2024



Semi-supervised learning (SSL) offers a robust framework for harnessing the potential of unannotated data. Traditionally, SSL mandates that all classes possess labeled instances. However, the emergence of open-world SSL (OwSSL) introduces a more practical challenge, wherein unlabeled data may encompass samples from unseen classes. This scenario leads to misclassification of unseen classes as known ones, consequently undermining classification accuracy. To overcome this challenge, this study revisits two methodologies from self-supervised and semi-supervised learning, self-labeling and consistency, tailoring them to address the OwSSL problem. Specifically, we propose an effective framework called OwMatch, combining conditional self-labeling and open-world hierarchical thresholding. Theoretically, we analyze the estimation of class distribution on unlabeled data through rigorous statistical analysis, thus demonstrating that OwMatch can ensure the unbiasedness of the self-label assignment estimator with reliability. Comprehensive empirical analyses demonstrate that our method yields substantial performance enhancements across both known and unknown classes in comparison to previous studies. Code is available at https://github.com/niusj03/OwMatch.
IncEventGS: Pose-Free Gaussian Splatting from a Single Event Camera
Oct 10, 2024



Implicit neural representation and explicit 3D Gaussian Splatting (3D-GS) for novel view synthesis have achieved remarkable progress with frame-based camera (e.g. RGB and RGB-D cameras) recently. Compared to frame-based camera, a novel type of bio-inspired visual sensor, i.e. event camera, has demonstrated advantages in high temporal resolution, high dynamic range, low power consumption and low latency. Due to its unique asynchronous and irregular data capturing process, limited work has been proposed to apply neural representation or 3D Gaussian splatting for an event camera. In this work, we present IncEventGS, an incremental 3D Gaussian Splatting reconstruction algorithm with a single event camera. To recover the 3D scene representation incrementally, we exploit the tracking and mapping paradigm of conventional SLAM pipelines for IncEventGS. Given the incoming event stream, the tracker firstly estimates an initial camera motion based on prior reconstructed 3D-GS scene representation. The mapper then jointly refines both the 3D scene representation and camera motion based on the previously estimated motion trajectory from the tracker. The experimental results demonstrate that IncEventGS delivers superior performance compared to prior NeRF-based methods and other related baselines, even we do not have the ground-truth camera poses. Furthermore, our method can also deliver better performance compared to state-of-the-art event visual odometry methods in terms of camera motion estimation. Code is publicly available at: https://github.com/wu-cvgl/IncEventGS.
Scaling Deep Learning Computation over the Inter-Core Connected Intelligence Processor
Aug 09, 2024As AI chips incorporate numerous parallelized cores to scale deep learning (DL) computing, inter-core communication is enabled recently by employing high-bandwidth and low-latency interconnect links on the chip (e.g., Graphcore IPU). It allows each core to directly access the fast scratchpad memory in other cores, which enables new parallel computing paradigms. However, without proper support for the scalable inter-core connections in current DL compilers, it is hard for developers to exploit the benefits of this new architecture. We present T10, the first DL compiler to exploit the inter-core communication bandwidth and distributed on-chip memory on AI chips. To formulate the computation and communication patterns of tensor operators in this new architecture, T10 introduces a distributed tensor abstraction rTensor. T10 maps a DNN model to execution plans with a generalized compute-shift pattern, by partitioning DNN computation into sub-operators and mapping them to cores, so that the cores can exchange data following predictable patterns. T10 makes globally optimized trade-offs between on-chip memory consumption and inter-core communication overhead, selects the best execution plan from a vast optimization space, and alleviates unnecessary inter-core communications. Our evaluation with a real inter-core connected AI chip, the Graphcore IPU, shows up to 3.3$\times$ performance improvement, and scalability support for larger models, compared to state-of-the-art DL compilers and vendor libraries.