 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWASE: Learning When to Attend for Speaker Extraction in Cocktail Party Environments
Jun 13, 2021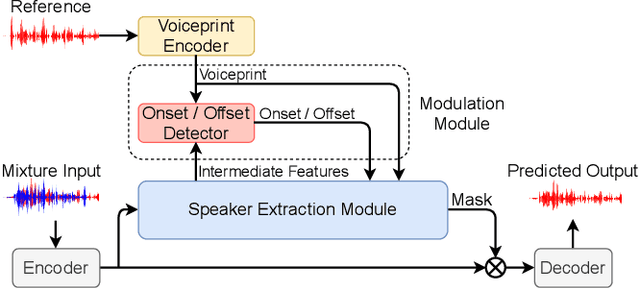
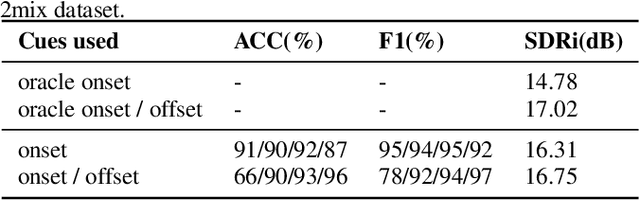
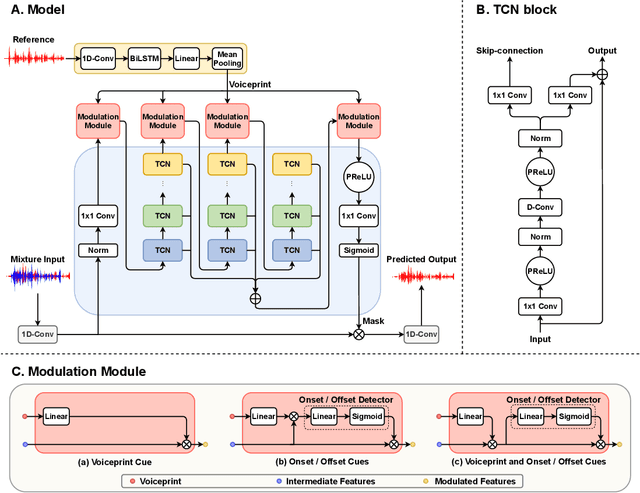
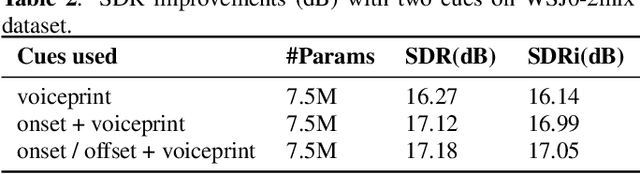
In the speaker extraction problem, it is found that additional information from the target speaker contributes to the tracking and extraction of the target speaker, which includes voiceprint, lip movement, facial expression, and spatial information. However, no one cares for the cue of sound onset, which has been emphasized in the auditory scene analysis and psychology. Inspired by it, we explicitly modeled the onset cue and verified the effectiveness in the speaker extraction task. We further extended to the onset/offset cues and got performance improvement. From the perspective of tasks, our onset/offset-based model completes the composite task, a complementary combination of speaker extraction and speaker-dependent voice activity detection. We also combined voiceprint with onset/offset cues. Voiceprint models voice characteristics of the target while onset/offset models the start/end information of the speech. From the perspective of auditory scene analysis, the combination of two perception cues can promote the integrity of the auditory object. The experiment results are also close to state-of-the-art performance, using nearly half of the parameters. We hope that this work will inspire communities of speech processing and psychology, and contribute to communication between them. Our code will be available in https://github.com/aispeech-lab/wase/.
One-pass Stochastic Gradient Descent in Overparametrized Two-layer Neural Networks
May 01, 2021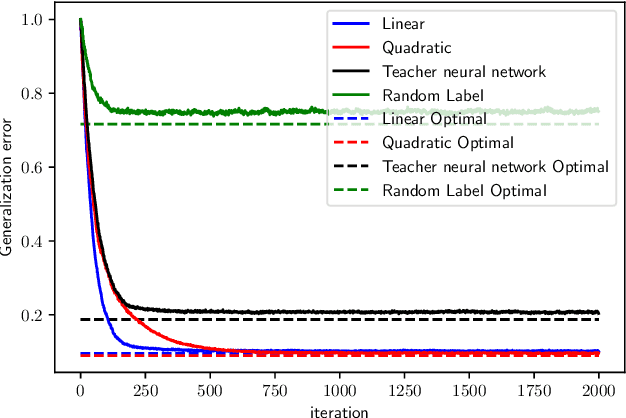
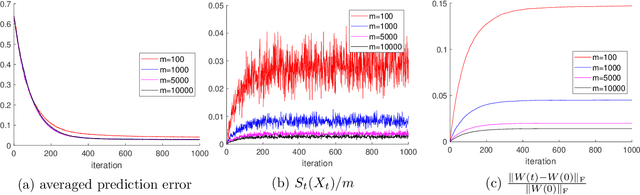
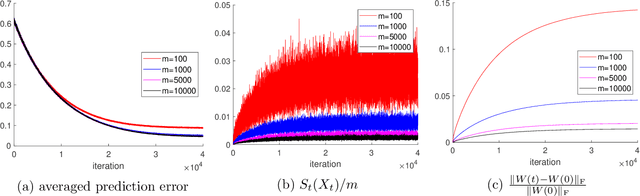
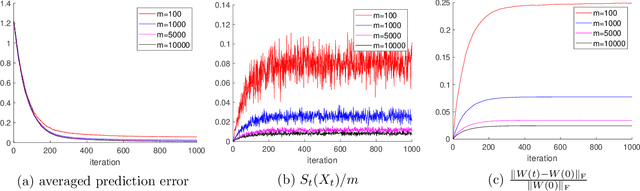
There has been a recent surge of interest in understanding the convergence of gradient descent (GD) and stochastic gradient descent (SGD) in overparameterized neural networks. Most previous works assume that the training data is provided a priori in a batch, while less attention has been paid to the important setting where the training data arrives in a stream. In this paper, we study the streaming data setup and show that with overparamterization and random initialization, the prediction error of two-layer neural networks under one-pass SGD converges in expectation. The convergence rate depends on the eigen-decomposition of the integral operator associated with the so-called neural tangent kernel (NTK). A key step of our analysis is to show a random kernel function converges to the NTK with high probability using the VC dimension and McDiarmid's inequality.
MIMO Self-attentive RNN Beamformer for Multi-speaker Speech Separation
Apr 26, 2021
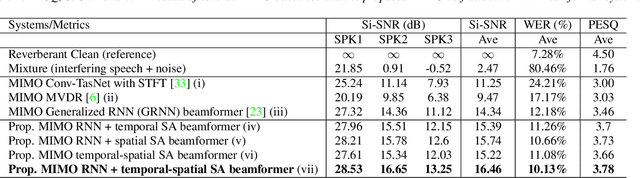

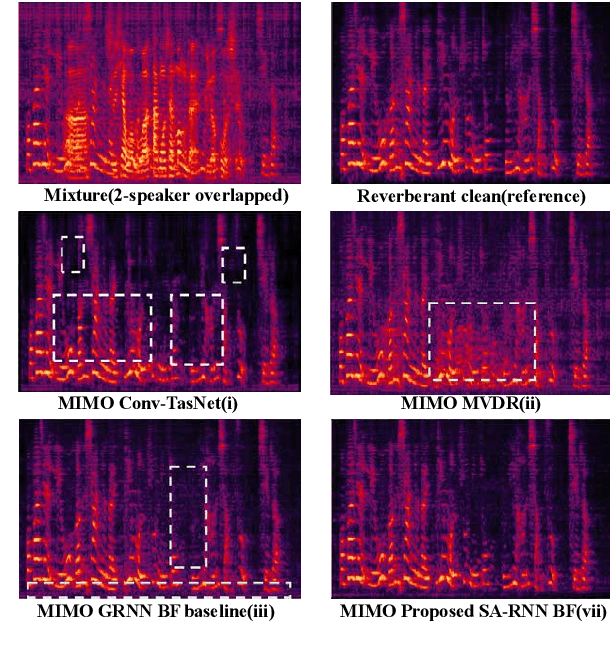
Recently, our proposed recurrent neural network (RNN) based all deep learning minimum variance distortionless response (ADL-MVDR) beamformer method yielded superior performance over the conventional MVDR by replacing the matrix inversion and eigenvalue decomposition with two recurrent neural networks. In this work, we present a self-attentive RNN beamformer to further improve our previous RNN-based beamformer by leveraging on the powerful modeling capability of self-attention. Temporal-spatial self-attention module is proposed to better learn the beamforming weights from the speech and noise spatial covariance matrices. The temporal self-attention module could help RNN to learn global statistics of covariance matrices. The spatial self-attention module is designed to attend on the cross-channel correlation in the covariance matrices. Furthermore, a multi-channel input with multi-speaker directional features and multi-speaker speech separation outputs (MIMO) model is developed to improve the inference efficiency. The evaluations demonstrate that our proposed MIMO self-attentive RNN beamformer improves both the automatic speech recognition (ASR) accuracy and the perceptual estimation of speech quality (PESQ) against prior arts.
The planted matching problem: Sharp threshold and infinite-order phase transition
Mar 17, 2021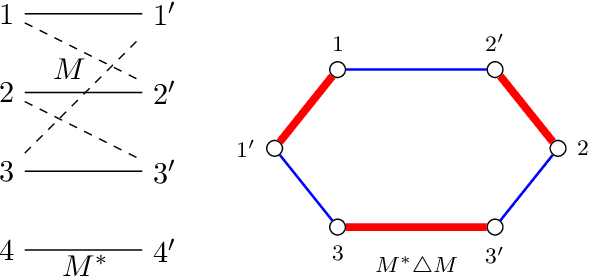
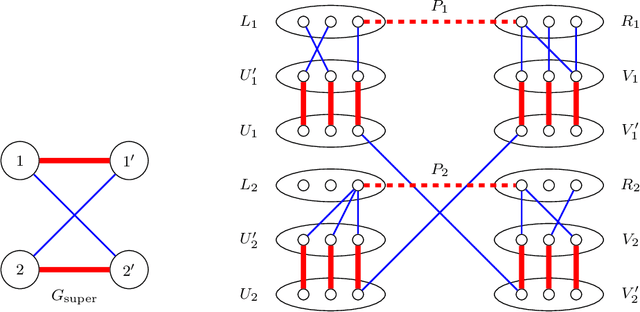
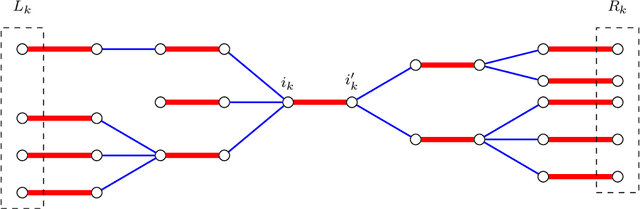
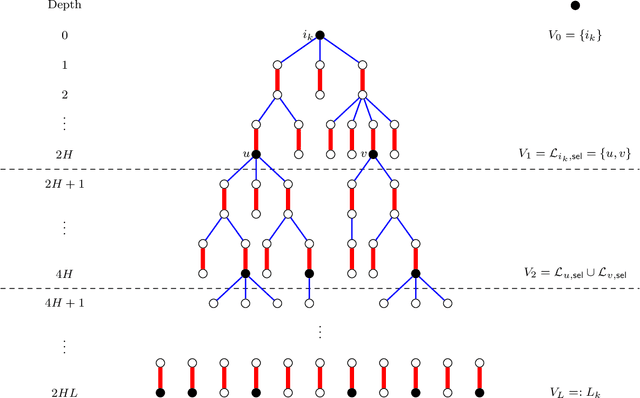
We study the problem of reconstructing a perfect matching $M^*$ hidden in a randomly weighted $n\times n$ bipartite graph. The edge set includes every node pair in $M^*$ and each of the $n(n-1)$ node pairs not in $M^*$ independently with probability $d/n$. The weight of each edge $e$ is independently drawn from the distribution $\mathcal{P}$ if $e \in M^*$ and from $\mathcal{Q}$ if $e \notin M^*$. We show that if $\sqrt{d} B(\mathcal{P},\mathcal{Q}) \le 1$, where $B(\mathcal{P},\mathcal{Q})$ stands for the Bhattacharyya coefficient, the reconstruction error (average fraction of misclassified edges) of the maximum likelihood estimator of $M^*$ converges to $0$ as $n\to \infty$. Conversely, if $\sqrt{d} B(\mathcal{P},\mathcal{Q}) \ge 1+\epsilon$ for an arbitrarily small constant $\epsilon>0$, the reconstruction error for any estimator is shown to be bounded away from $0$ under both the sparse and dense model, resolving the conjecture in [Moharrami et al. 2019, Semerjian et al. 2020]. Furthermore, in the special case of complete exponentially weighted graph with $d=n$, $\mathcal{P}=\exp(\lambda)$, and $\mathcal{Q}=\exp(1/n)$, for which the sharp threshold simplifies to $\lambda=4$, we prove that when $\lambda \le 4-\epsilon$, the optimal reconstruction error is $\exp\left( - \Theta(1/\sqrt{\epsilon}) \right)$, confirming the conjectured infinite-order phase transition in [Semerjian et al. 2020].
Learner-Private Online Convex Optimization
Feb 23, 2021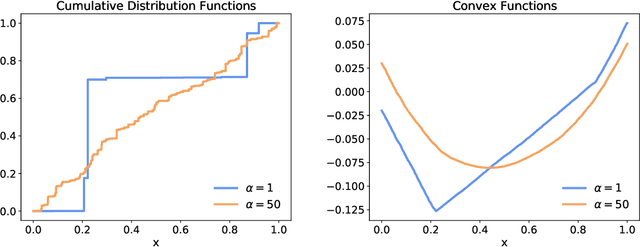


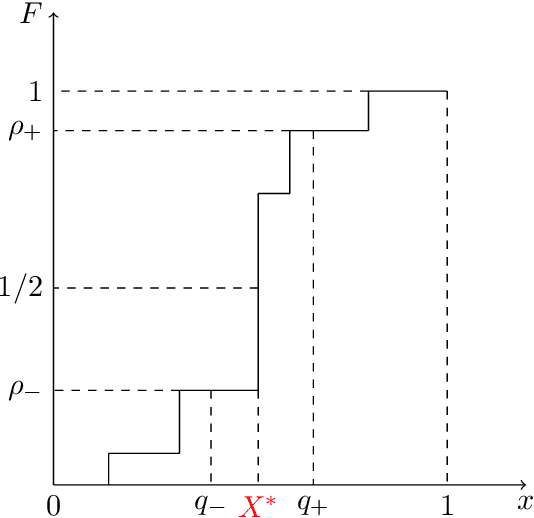
Online convex optimization is a framework where a learner sequentially queries an external data source in order to arrive at the optimal solution of a convex function. The paradigm has gained significant popularity recently thanks to its scalability in large-scale optimization and machine learning. The repeated interactions, however, expose the learner to privacy risks from eavesdropping adversary that observe the submitted queries. In this paper, we study how to optimally obfuscate the learner's queries in first-order online convex optimization, so that their learned optimal value is provably difficult to estimate for the eavesdropping adversary. We consider two formulations of learner privacy: a Bayesian formulation in which the convex function is drawn randomly, and a minimax formulation in which the function is fixed and the adversary's probability of error is measured with respect to a minimax criterion. We show that, if the learner wants to ensure the probability of accurate prediction by the adversary be kept below $1/L$, then the overhead in query complexity is additive in $L$ in the minimax formulation, but multiplicative in $L$ in the Bayesian formulation. Compared to existing learner-private sequential learning models with binary feedback, our results apply to the significantly richer family of general convex functions with full-gradient feedback. Our proofs are largely enabled by tools from the theory of Dirichlet processes, as well as more sophisticated lines of analysis aimed at measuring the amount of information leakage under a full-gradient oracle.
The Power of $D$-hops in Matching Power-Law Graphs
Feb 23, 2021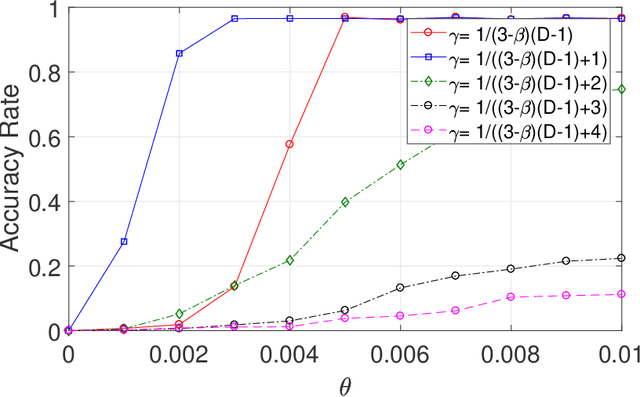
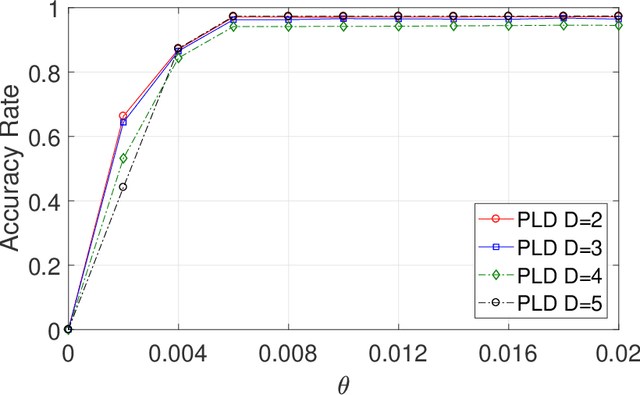
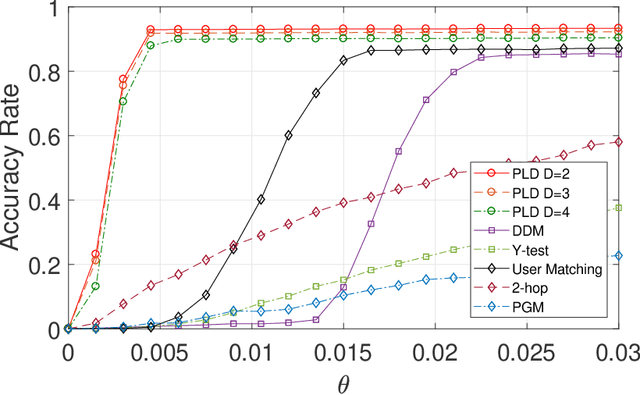
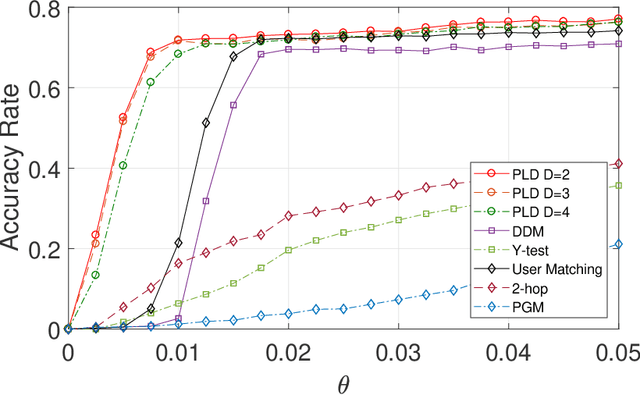
This paper studies seeded graph matching for power-law graphs. Assume that two edge-correlated graphs are independently edge-sampled from a common parent graph with a power-law degree distribution. A set of correctly matched vertex-pairs is chosen at random and revealed as initial seeds. Our goal is to use the seeds to recover the remaining latent vertex correspondence between the two graphs. Departing from the existing approaches that focus on the use of high-degree seeds in $1$-hop neighborhoods, we develop an efficient algorithm that exploits the low-degree seeds in suitably-defined $D$-hop neighborhoods. Specifically, we first match a set of vertex-pairs with appropriate degrees (which we refer to as the first slice) based on the number of low-degree seeds in their $D$-hop neighborhoods. This significantly reduces the number of initial seeds needed to trigger a cascading process to match the rest of the graphs. Under the Chung-Lu random graph model with $n$ vertices, max degree $\Theta(\sqrt{n})$, and the power-law exponent $2<\beta<3$, we show that as soon as $D> \frac{4-\beta}{3-\beta}$, by optimally choosing the first slice, with high probability our algorithm can correctly match a constant fraction of the true pairs without any error, provided with only $\Omega((\log n)^{4-\beta})$ initial seeds. Our result achieves an exponential reduction in the seed size requirement, as the best previously known result requires $n^{1/2+\epsilon}$ seeds (for any small constant $\epsilon>0$). Performance evaluation with synthetic and real data further corroborates the improved performance of our algorithm.
Speaker and Direction Inferred Dual-channel Speech Separation
Feb 08, 2021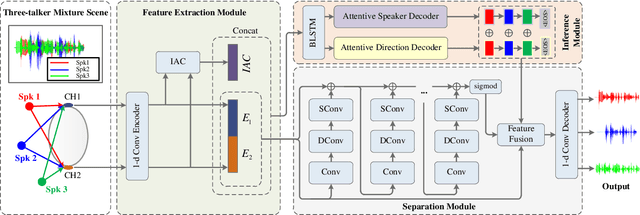
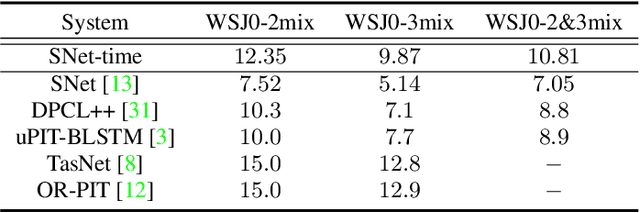
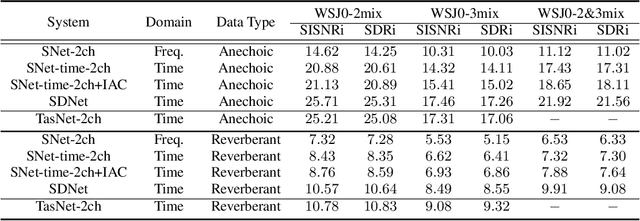
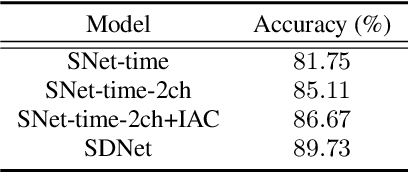
Most speech separation methods, trying to separate all channel sources simultaneously, are still far from having enough general- ization capabilities for real scenarios where the number of input sounds is usually uncertain and even dynamic. In this work, we employ ideas from auditory attention with two ears and propose a speaker and direction inferred speech separation network (dubbed SDNet) to solve the cocktail party problem. Specifically, our SDNet first parses out the respective perceptual representations with their speaker and direction characteristics from the mixture of the scene in a sequential manner. Then, the perceptual representations are utilized to attend to each corresponding speech. Our model gener- ates more precise perceptual representations with the help of spatial features and successfully deals with the problem of the unknown number of sources and the selection of outputs. The experiments on standard fully-overlapped speech separation benchmarks, WSJ0- 2mix, WSJ0-3mix, and WSJ0-2&3mix, show the effectiveness, and our method achieves SDR improvements of 25.31 dB, 17.26 dB, and 21.56 dB under anechoic settings. Our codes will be released at https://github.com/aispeech-lab/SDNet.
Settling the Sharp Reconstruction Thresholds of Random Graph Matching
Jan 29, 2021This paper studies the problem of recovering the hidden vertex correspondence between two edge-correlated random graphs. We focus on the Gaussian model where the two graphs are complete graphs with correlated Gaussian weights and the Erd\H{o}s-R\'enyi model where the two graphs are subsampled from a common parent Erd\H{o}s-R\'enyi graph $\mathcal{G}(n,p)$. For dense graphs with $p=n^{-o(1)}$, we prove that there exists a sharp threshold, above which one can correctly match all but a vanishing fraction of vertices and below which correctly matching any positive fraction is impossible, a phenomenon known as the "all-or-nothing" phase transition. Even more strikingly, in the Gaussian setting, above the threshold all vertices can be exactly matched with high probability. In contrast, for sparse Erd\H{o}s-R\'enyi graphs with $p=n^{-\Theta(1)}$, we show that the all-or-nothing phenomenon no longer holds and we determine the thresholds up to a constant factor. Along the way, we also derive the sharp threshold for exact recovery, sharpening the existing results in Erd\H{o}s-R\'enyi graphs. The proof of the negative results builds upon a tight characterization of the mutual information based on the truncated second-moment computation and an "area theorem" that relates the mutual information to the integral of the reconstruction error. The positive results follows from a tight analysis of the maximum likelihood estimator that takes into account the cycle structure of the induced permutation on the edges.
Audio-visual Speech Separation with Adversarially Disentangled Visual Representation
Nov 29, 2020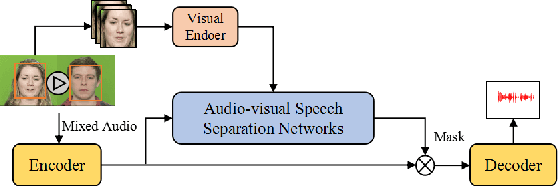
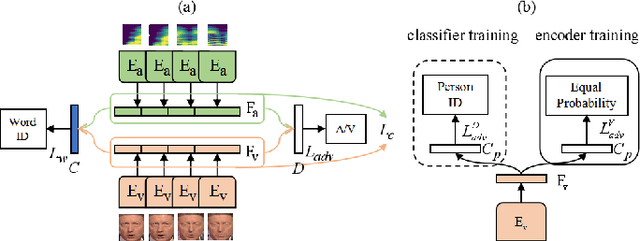
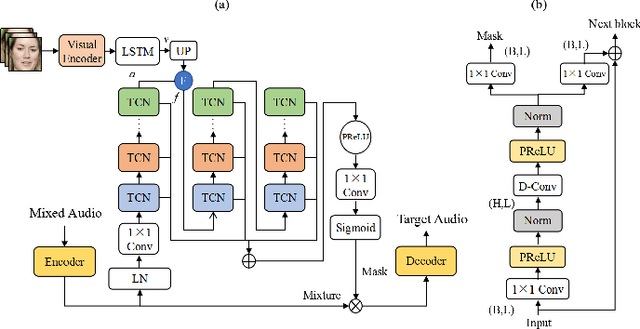
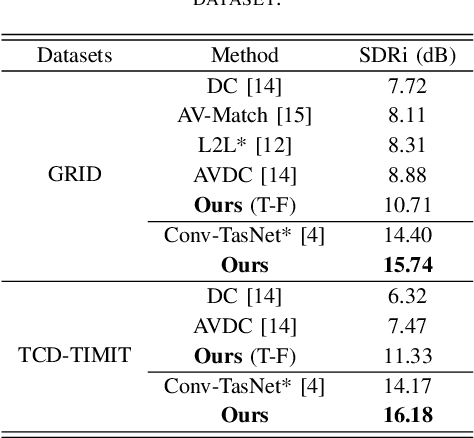
Speech separation aims to separate individual voice from an audio mixture of multiple simultaneous talkers. Although audio-only approaches achieve satisfactory performance, they build on a strategy to handle the predefined conditions, limiting their application in the complex auditory scene. Towards the cocktail party problem, we propose a novel audio-visual speech separation model. In our model, we use the face detector to detect the number of speakers in the scene and use visual information to avoid the permutation problem. To improve our model's generalization ability to unknown speakers, we extract speech-related visual features from visual inputs explicitly by the adversarially disentangled method, and use this feature to assist speech separation. Besides, the time-domain approach is adopted, which could avoid the phase reconstruction problem existing in the time-frequency domain models. To compare our model's performance with other models, we create two benchmark datasets of 2-speaker mixture from GRID and TCDTIMIT audio-visual datasets. Through a series of experiments, our proposed model is shown to outperform the state-of-the-art audio-only model and three audio-visual models.
Testing correlation of unlabeled random graphs
Aug 23, 2020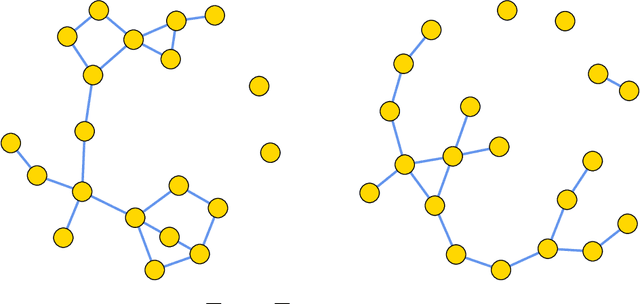
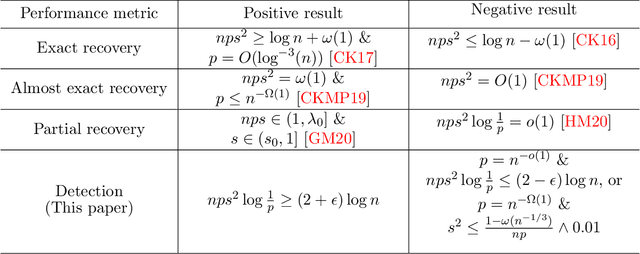
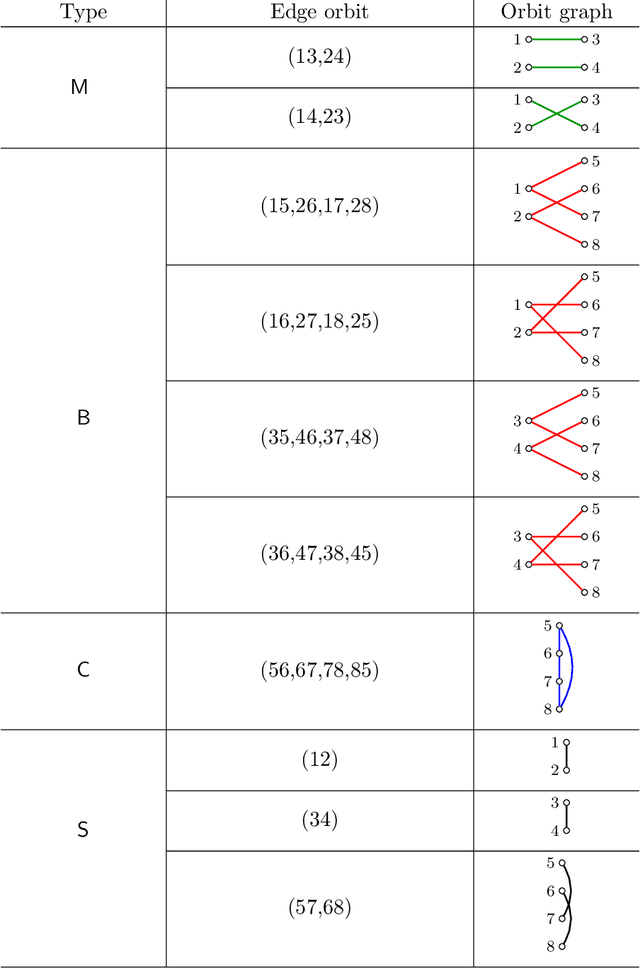
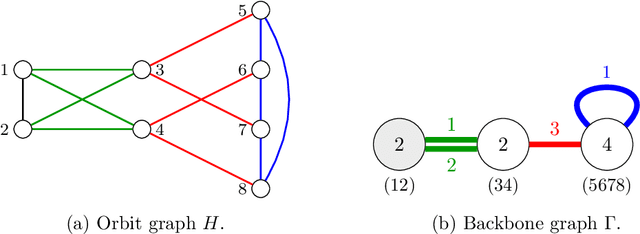
We study the problem of detecting the edge correlation between two random graphs with $n$ unlabeled nodes. This is formalized as a hypothesis testing problem, where under the null hypothesis, the two graphs are independently generated; under the alternative, the two graphs are edge-correlated under some latent node correspondence, but have the same marginal distributions as the null. For both Gaussian-weighted complete graphs and dense Erd\H{o}s-R\'enyi graphs (with edge probability $n^{-o(1)}$), we determine the sharp threshold at which the optimal testing error probability exhibits a phase transition from zero to one as $n\to \infty$. For sparse Erd\H{o}s-R\'enyi graphs with edge probability $n^{-\Omega(1)}$, we determine the threshold within a constant factor. The proof of the impossibility results is an application of the conditional second-moment method, where we bound the truncated second moment of the likelihood ratio by carefully conditioning on the typical behavior of the intersection graph (consisting of edges in both observed graphs) and taking into account the cycle structure of the induced random permutation on the edges. Notably, in the sparse regime, this is accomplished by leveraging the pseudoforest structure of subcritical Erd\H{o}s-R\'enyi graphs and a careful enumeration of subpseudoforests that can be assembled from short orbits of the edge permutation.