 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreaming Video Instruction Tuning
Dec 24, 2025



We present Streamo, a real-time streaming video LLM that serves as a general-purpose interactive assistant. Unlike existing online video models that focus narrowly on question answering or captioning, Streamo performs a broad spectrum of streaming video tasks, including real-time narration, action understanding, event captioning, temporal event grounding, and time-sensitive question answering. To develop such versatility, we construct Streamo-Instruct-465K, a large-scale instruction-following dataset tailored for streaming video understanding. The dataset covers diverse temporal contexts and multi-task supervision, enabling unified training across heterogeneous streaming tasks. After training end-to-end on the instruction-following dataset through a streamlined pipeline, Streamo exhibits strong temporal reasoning, responsive interaction, and broad generalization across a variety of streaming benchmarks. Extensive experiments show that Streamo bridges the gap between offline video perception models and real-time multimodal assistants, making a step toward unified, intelligent video understanding in continuous video streams.
Measuring Epistemic Humility in Multimodal Large Language Models
Sep 11, 2025Hallucinations in multimodal large language models (MLLMs) -- where the model generates content inconsistent with the input image -- pose significant risks in real-world applications, from misinformation in visual question answering to unsafe errors in decision-making. Existing benchmarks primarily test recognition accuracy, i.e., evaluating whether models can select the correct answer among distractors. This overlooks an equally critical capability for trustworthy AI: recognizing when none of the provided options are correct, a behavior reflecting epistemic humility. We present HumbleBench, a new hallucination benchmark designed to evaluate MLLMs' ability to reject plausible but incorrect answers across three hallucination types: object, relation, and attribute. Built from a panoptic scene graph dataset, we leverage fine-grained scene graph annotations to extract ground-truth entities and relations, and prompt GPT-4-Turbo to generate multiple-choice questions, followed by a rigorous manual filtering process. Each question includes a "None of the above" option, requiring models not only to recognize correct visual information but also to identify when no provided answer is valid. We evaluate a variety of state-of-the-art MLLMs -- including both general-purpose and specialized reasoning models -- on HumbleBench and share valuable findings and insights with the community. By incorporating explicit false-option rejection, HumbleBench fills a key gap in current evaluation suites, providing a more realistic measure of MLLM reliability in safety-critical settings. Our code and dataset are released publicly and can be accessed at https://github.com/maifoundations/HumbleBench.
Bootstrapping Grounded Chain-of-Thought in Multimodal LLMs for Data-Efficient Model Adaptation
Jul 03, 2025Multimodal Large Language Models (MLLMs) have demonstrated remarkable capabilities in interpreting images using natural language. However, without using large-scale datasets for retraining, these models are difficult to adapt to specialized vision tasks, e.g., chart understanding. This problem is caused by a mismatch between pre-training and downstream datasets: pre-training datasets primarily concentrate on scenes and objects but contain limited information about specialized, non-object images, such as charts and tables. In this paper, we share an interesting finding that training an MLLM with Chain-of-Thought (CoT) reasoning data can facilitate model adaptation in specialized vision tasks, especially under data-limited regimes. However, we identify a critical issue within CoT data distilled from pre-trained MLLMs, i.e., the data often contains multiple factual errors in the reasoning steps. To address the problem, we propose Grounded Chain-of-Thought (GCoT), a simple bootstrapping-based approach that aims to inject grounding information (i.e., bounding boxes) into CoT data, essentially making the reasoning steps more faithful to input images. We evaluate our approach on five specialized vision tasks, which cover a variety of visual formats including charts, tables, receipts, and reports. The results demonstrate that under data-limited regimes our approach significantly improves upon fine-tuning and distillation.
Visionary-R1: Mitigating Shortcuts in Visual Reasoning with Reinforcement Learning
May 20, 2025Learning general-purpose reasoning capabilities has long been a challenging problem in AI. Recent research in large language models (LLMs), such as DeepSeek-R1, has shown that reinforcement learning techniques like GRPO can enable pre-trained LLMs to develop reasoning capabilities using simple question-answer pairs. In this paper, we aim to train visual language models (VLMs) to perform reasoning on image data through reinforcement learning and visual question-answer pairs, without any explicit chain-of-thought (CoT) supervision. Our findings indicate that simply applying reinforcement learning to a VLM -- by prompting the model to produce a reasoning chain before providing an answer -- can lead the model to develop shortcuts from easy questions, thereby reducing its ability to generalize across unseen data distributions. We argue that the key to mitigating shortcut learning is to encourage the model to interpret images prior to reasoning. Therefore, we train the model to adhere to a caption-reason-answer output format: initially generating a detailed caption for an image, followed by constructing an extensive reasoning chain. When trained on 273K CoT-free visual question-answer pairs and using only reinforcement learning, our model, named Visionary-R1, outperforms strong multimodal models, such as GPT-4o, Claude3.5-Sonnet, and Gemini-1.5-Pro, on multiple visual reasoning benchmarks.
Attention Disturbance and Dual-Path Constraint Network for Occluded Person Re-Identification
Mar 20, 2023



Occluded person re-identification (Re-ID) aims to address the potential occlusion problem when matching occluded or holistic pedestrians from different camera views. Many methods use the background as artificial occlusion and rely on attention networks to exclude noisy interference. However, the significant discrepancy between simple background occlusion and realistic occlusion can negatively impact the generalization of the network.To address this issue, we propose a novel transformer-based Attention Disturbance and Dual-Path Constraint Network (ADP) to enhance the generalization of attention networks. Firstly, to imitate real-world obstacles, we introduce an Attention Disturbance Mask (ADM) module that generates an offensive noise, which can distract attention like a realistic occluder, as a more complex form of occlusion.Secondly, to fully exploit these complex occluded images, we develop a Dual-Path Constraint Module (DPC) that can obtain preferable supervision information from holistic images through dual-path interaction. With our proposed method, the network can effectively circumvent a wide variety of occlusions using the basic ViT baseline. Comprehensive experimental evaluations conducted on person re-ID benchmarks demonstrate the superiority of ADP over state-of-the-art methods.
CycleTrans: Learning Neutral yet Discriminative Features for Visible-Infrared Person Re-Identification
Aug 21, 2022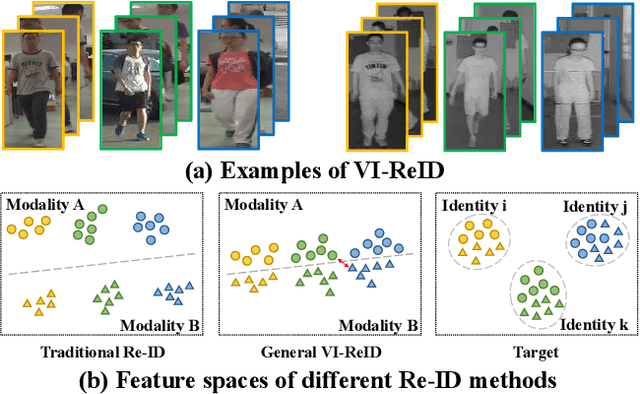
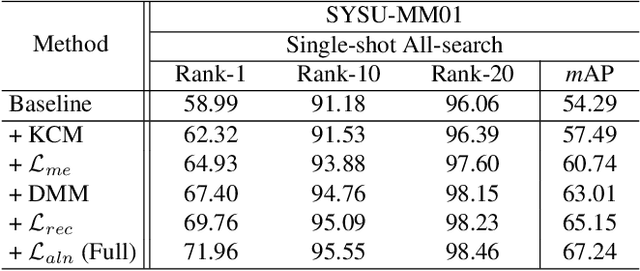
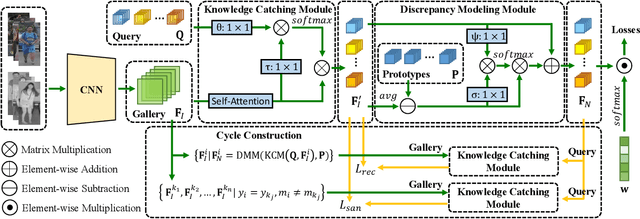
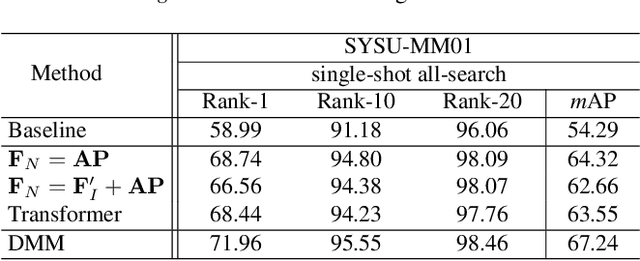
Visible-infrared person re-identification (VI-ReID) is a task of matching the same individuals across the visible and infrared modalities. Its main challenge lies in the modality gap caused by cameras operating on different spectra. Existing VI-ReID methods mainly focus on learning general features across modalities, often at the expense of feature discriminability. To address this issue, we present a novel cycle-construction-based network for neutral yet discriminative feature learning, termed CycleTrans. Specifically, CycleTrans uses a lightweight Knowledge Capturing Module (KCM) to capture rich semantics from the modality-relevant feature maps according to pseudo queries. Afterwards, a Discrepancy Modeling Module (DMM) is deployed to transform these features into neutral ones according to the modality-irrelevant prototypes. To ensure feature discriminability, another two KCMs are further deployed for feature cycle constructions. With cycle construction, our method can learn effective neutral features for visible and infrared images while preserving their salient semantics. Extensive experiments on SYSU-MM01 and RegDB datasets validate the merits of CycleTrans against a flurry of state-of-the-art methods, +4.57% on rank-1 in SYSU-MM01 and +2.2% on rank-1 in RegDB.