 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiversity Empowers Intelligence: Integrating Expertise of Software Engineering Agents
Aug 13, 2024Large language model (LLM) agents have shown great potential in solving real-world software engineering (SWE) problems. The most advanced open-source SWE agent can resolve over 27% of real GitHub issues in SWE-Bench Lite. However, these sophisticated agent frameworks exhibit varying strengths, excelling in certain tasks while underperforming in others. To fully harness the diversity of these agents, we propose DEI (Diversity Empowered Intelligence), a framework that leverages their unique expertise. DEI functions as a meta-module atop existing SWE agent frameworks, managing agent collectives for enhanced problem-solving. Experimental results show that a DEI-guided committee of agents is able to surpass the best individual agent's performance by a large margin. For instance, a group of open-source SWE agents, with a maximum individual resolve rate of 27.3% on SWE-Bench Lite, can achieve a 34.3% resolve rate with DEI, making a 25% improvement and beating most closed-source solutions. Our best-performing group excels with a 55% resolve rate, securing the highest ranking on SWE-Bench Lite. Our findings contribute to the growing body of research on collaborative AI systems and their potential to solve complex software engineering challenges.
Unlocking Anticipatory Text Generation: A Constrained Approach for Faithful Decoding with Large Language Models
Dec 11, 2023



Large Language Models (LLMs) have demonstrated a powerful ability for text generation. However, achieving optimal results with a given prompt or instruction can be challenging, especially for billion-sized models. Additionally, undesired behaviors such as toxicity or hallucinations can manifest. While much larger models (e.g., ChatGPT) may demonstrate strength in mitigating these issues, there is still no guarantee of complete prevention. In this work, we propose formalizing text generation as a future-constrained generation problem to minimize undesirable behaviors and enforce faithfulness to instructions. The estimation of future constraint satisfaction, accomplished using LLMs, guides the text generation process. Our extensive experiments demonstrate the effectiveness of the proposed approach across three distinct text generation tasks: keyword-constrained generation (Lin et al., 2020), toxicity reduction (Gehman et al., 2020), and factual correctness in question-answering (Gao et al., 2023).
A Long Way to Go: Investigating Length Correlations in RLHF
Oct 05, 2023



Great successes have been reported using Reinforcement Learning from Human Feedback (RLHF) to align large language models. Open-source preference datasets and reward models have enabled wider experimentation beyond generic chat settings, particularly to make systems more "helpful" for tasks like web question answering, summarization, and multi-turn dialogue. When optimizing for helpfulness, RLHF has been consistently observed to drive models to produce longer outputs. This paper demonstrates that optimizing for response length is a significant factor behind RLHF's reported improvements in these settings. First, we study the relationship between reward and length for reward models trained on three open-source preference datasets for helpfulness. Here, length correlates strongly with reward, and improvements in reward score are driven in large part by shifting the distribution over output lengths. We then explore interventions during both RL and reward model learning to see if we can achieve the same downstream improvements as RLHF without increasing length. While our interventions mitigate length increases, they aren't uniformly effective across settings. Furthermore, we find that even running RLHF with a reward based solely on length can reproduce most of the downstream improvements over the initial policy model, showing that reward models in these settings have a long way to go.
EEL: Efficiently Encoding Lattices for Reranking
Jun 01, 2023



Standard decoding approaches for conditional text generation tasks typically search for an output hypothesis with high model probability, but this may not yield the best hypothesis according to human judgments of quality. Reranking to optimize for "downstream" metrics can better optimize for quality, but many metrics of interest are computed with pre-trained language models, which are slow to apply to large numbers of hypotheses. We explore an approach for reranking hypotheses by using Transformers to efficiently encode lattices of generated outputs, a method we call EEL. With a single Transformer pass over the entire lattice, we can approximately compute a contextualized representation of each token as if it were only part of a single hypothesis in isolation. We combine this approach with a new class of token-factored rerankers (TFRs) that allow for efficient extraction of high reranker-scoring hypotheses from the lattice. Empirically, our approach incurs minimal degradation error compared to the exponentially slower approach of encoding each hypothesis individually. When applying EEL with TFRs across three text generation tasks, our results show both substantial speedup compared to naive reranking and often better performance on downstream metrics than comparable approaches.
Language Model Self-improvement by Reinforcement Learning Contemplation
May 23, 2023



Large Language Models (LLMs) have exhibited remarkable performance across various natural language processing (NLP) tasks. However, fine-tuning these models often necessitates substantial supervision, which can be expensive and time-consuming to obtain. This paper introduces a novel unsupervised method called LanguageModel Self-Improvement by Reinforcement Learning Contemplation (SIRLC) that improves LLMs without reliance on external labels. Our approach is grounded in the observation that it is simpler for language models to assess text quality than to generate text. Building on this insight, SIRLC assigns LLMs dual roles as both student and teacher. As a student, the LLM generates answers to unlabeled questions, while as a teacher, it evaluates the generated text and assigns scores accordingly. The model parameters are updated using reinforcement learning to maximize the evaluation score. We demonstrate that SIRLC can be applied to various NLP tasks, such as reasoning problems, text generation, and machine translation. Our experiments show that SIRLC effectively improves LLM performance without external supervision, resulting in a 5.6% increase in answering accuracy for reasoning tasks and a rise in BERTScore from 0.82 to 0.86 for translation tasks. Furthermore, SIRLC can be applied to models of different sizes, showcasing its broad applicability.
Best-$k$ Search Algorithm for Neural Text Generation
Nov 22, 2022



Modern natural language generation paradigms require a good decoding strategy to obtain quality sequences out of the model. Beam search yields high-quality but low diversity outputs; stochastic approaches suffer from high variance and sometimes low quality, but the outputs tend to be more natural and creative. In this work, we propose a deterministic search algorithm balancing both quality and diversity. We first investigate the vanilla best-first search (BFS) algorithm and then propose the Best-$k$ Search algorithm. Inspired by BFS, we greedily expand the top $k$ nodes, instead of only the first node, to boost efficiency and diversity. Upweighting recently discovered nodes accompanied by heap pruning ensures the completeness of the search procedure. Experiments on four NLG tasks, including question generation, commonsense generation, text summarization, and translation, show that best-$k$ search yields more diverse and natural outputs compared to strong baselines, while our approach maintains high text quality. The proposed algorithm is parameter-free, lightweight, efficient, and easy to use.
Robust Unstructured Knowledge Access in Conversational Dialogue with ASR Errors
Nov 08, 2022



Performance of spoken language understanding (SLU) can be degraded with automatic speech recognition (ASR) errors. We propose a novel approach to improve SLU robustness by randomly corrupting clean training text with an ASR error simulator, followed by self-correcting the errors and minimizing the target classification loss in a joint manner. In the proposed error simulator, we leverage confusion networks generated from an ASR decoder without human transcriptions to generate a variety of error patterns for model training. We evaluate our approach on the DSTC10 challenge targeted for knowledge-grounded task-oriented conversational dialogues with ASR errors. Experimental results show the effectiveness of our proposed approach, boosting the knowledge-seeking turn detection (KTD) F1 significantly from 0.9433 to 0.9904. Knowledge cluster classification is boosted from 0.7924 to 0.9333 in Recall@1. After knowledge document re-ranking, our approach shows significant improvement in all knowledge selection metrics, from 0.7358 to 0.7806 in Recall@1, from 0.8301 to 0.9333 in Recall@5, and from 0.7798 to 0.8460 in MRR@5 on the test set. In the recent DSTC10 evaluation, our approach demonstrates significant improvement in knowledge selection, boosting Recall@1 from 0.495 to 0.7144 compared to the official baseline. Our source code is released in GitHub https://github.com/yctam/dstc10_track2_task2.git.
* 7 pages, 2 figures. Accepted at ICASSP 2022
Multi-agent Dynamic Algorithm Configuration
Oct 13, 2022

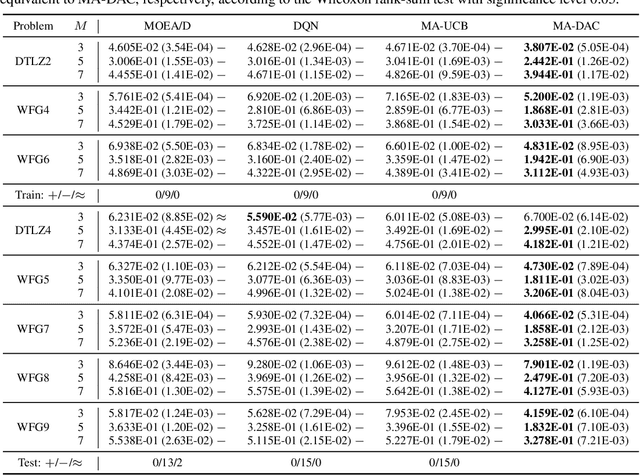
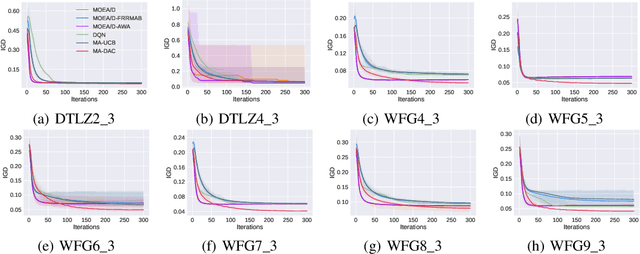
Automated algorithm configuration relieves users from tedious, trial-and-error tuning tasks. A popular algorithm configuration tuning paradigm is dynamic algorithm configuration (DAC), in which an agent learns dynamic configuration policies across instances by reinforcement learning (RL). However, in many complex algorithms, there may exist different types of configuration hyperparameters, and such heterogeneity may bring difficulties for classic DAC which uses a single-agent RL policy. In this paper, we aim to address this issue and propose multi-agent DAC (MA-DAC), with one agent working for one type of configuration hyperparameter. MA-DAC formulates the dynamic configuration of a complex algorithm with multiple types of hyperparameters as a contextual multi-agent Markov decision process and solves it by a cooperative multi-agent RL (MARL) algorithm. To instantiate, we apply MA-DAC to a well-known optimization algorithm for multi-objective optimization problems. Experimental results show the effectiveness of MA-DAC in not only achieving superior performance compared with other configuration tuning approaches based on heuristic rules, multi-armed bandits, and single-agent RL, but also being capable of generalizing to different problem classes. Furthermore, we release the environments in this paper as a benchmark for testing MARL algorithms, with the hope of facilitating the application of MARL.
Neural Architecture Search on Efficient Transformers and Beyond
Jul 28, 2022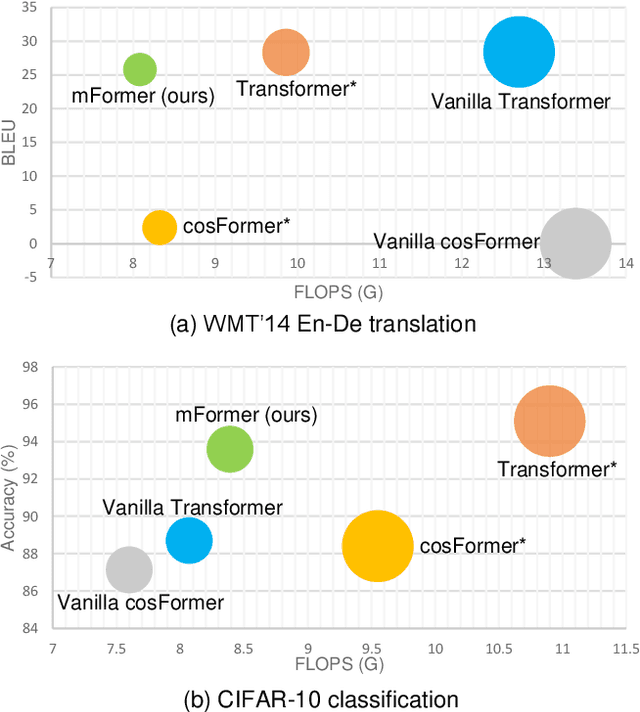
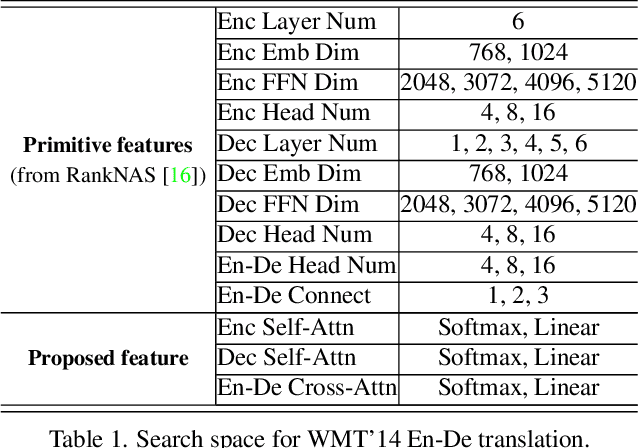


Recently, numerous efficient Transformers have been proposed to reduce the quadratic computational complexity of standard Transformers caused by the Softmax attention. However, most of them simply swap Softmax with an efficient attention mechanism without considering the customized architectures specially for the efficient attention. In this paper, we argue that the handcrafted vanilla Transformer architectures for Softmax attention may not be suitable for efficient Transformers. To address this issue, we propose a new framework to find optimal architectures for efficient Transformers with the neural architecture search (NAS) technique. The proposed method is validated on popular machine translation and image classification tasks. We observe that the optimal architecture of the efficient Transformer has the reduced computation compared with that of the standard Transformer, but the general accuracy is less comparable. It indicates that the Softmax attention and efficient attention have their own distinctions but neither of them can simultaneously balance the accuracy and efficiency well. This motivates us to mix the two types of attention to reduce the performance imbalance. Besides the search spaces that commonly used in existing NAS Transformer approaches, we propose a new search space that allows the NAS algorithm to automatically search the attention variants along with architectures. Extensive experiments on WMT' 14 En-De and CIFAR-10 demonstrate that our searched architecture maintains comparable accuracy to the standard Transformer with notably improved computational efficiency.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.