 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Factual Errors in Summarization: Errors, Summarizers, Datasets, Error Detectors
Paper and Code
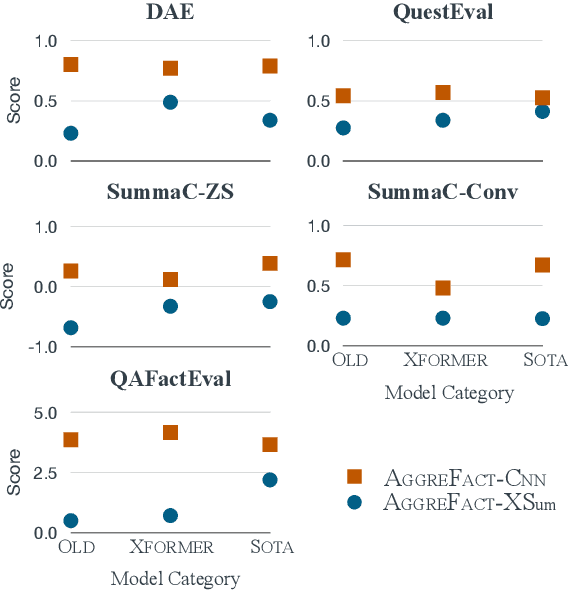
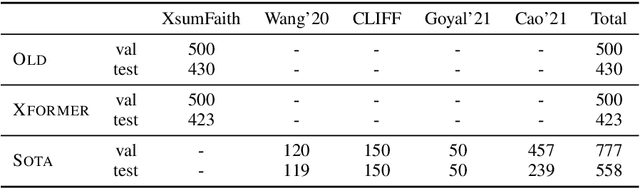
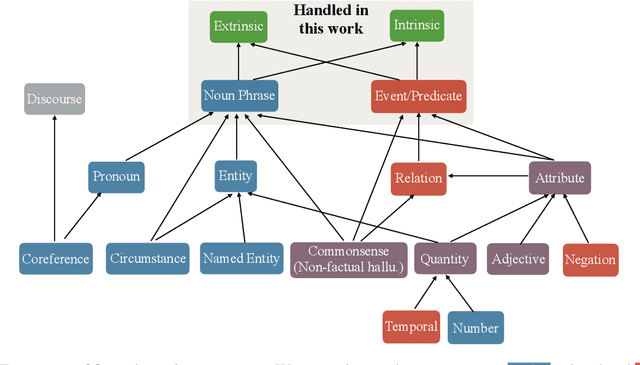
The propensity of abstractive summarization systems to make factual errors has been the subject of significant study, including work on models to detect factual errors and annotation of errors in current systems' outputs. However, the ever-evolving nature of summarization systems, error detectors, and annotated benchmarks make factuality evaluation a moving target; it is hard to get a clear picture of how techniques compare. In this work, we collect labeled factuality errors from across nine datasets of annotated summary outputs and stratify them in a new way, focusing on what kind of base summarization model was used. To support finer-grained analysis, we unify the labeled error types into a single taxonomy and project each of the datasets' errors into this shared labeled space. We then contrast five state-of-the-art error detection methods on this benchmark. Our findings show that benchmarks built on modern summary outputs (those from pre-trained models) show significantly different results than benchmarks using pre-Transformer models. Furthermore, no one factuality technique is superior in all settings or for all error types, suggesting that system developers should take care to choose the right system for their task at hand.