 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Price of Tolerance in Distribution Testing
Jun 25, 2021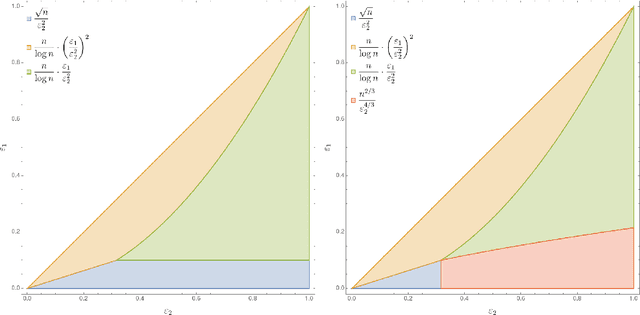
We revisit the problem of tolerant distribution testing. That is, given samples from an unknown distribution $p$ over $\{1, \dots, n\}$, is it $\varepsilon_1$-close to or $\varepsilon_2$-far from a reference distribution $q$ (in total variation distance)? Despite significant interest over the past decade, this problem is well understood only in the extreme cases. In the noiseless setting (i.e., $\varepsilon_1 = 0$) the sample complexity is $\Theta(\sqrt{n})$, strongly sublinear in the domain size. At the other end of the spectrum, when $\varepsilon_1 = \varepsilon_2/2$, the sample complexity jumps to the barely sublinear $\Theta(n/\log n)$. However, very little is known about the intermediate regime. We fully characterize the price of tolerance in distribution testing as a function of $n$, $\varepsilon_1$, $\varepsilon_2$, up to a single $\log n$ factor. Specifically, we show the sample complexity to be \[\tilde \Theta\left(\frac{\sqrt{n}}{\varepsilon_2^{2}} + \frac{n}{\log n} \cdot \max \left\{\frac{\varepsilon_1}{\varepsilon_2^2},\left(\frac{\varepsilon_1}{\varepsilon_2^2}\right)^{\!\!2}\right\}\right),\] providing a smooth tradeoff between the two previously known cases. We also provide a similar characterization for the problem of tolerant equivalence testing, where both $p$ and $q$ are unknown. Surprisingly, in both cases, the main quantity dictating the sample complexity is the ratio $\varepsilon_1/\varepsilon_2^2$, and not the more intuitive $\varepsilon_1/\varepsilon_2$. Of particular technical interest is our lower bound framework, which involves novel approximation-theoretic tools required to handle the asymmetry between $\varepsilon_1$ and $\varepsilon_2$, a challenge absent from previous works.
Robust Regression Revisited: Acceleration and Improved Estimation Rates
Jun 22, 2021We study fast algorithms for statistical regression problems under the strong contamination model, where the goal is to approximately optimize a generalized linear model (GLM) given adversarially corrupted samples. Prior works in this line of research were based on the robust gradient descent framework of Prasad et. al., a first-order method using biased gradient queries, or the Sever framework of Diakonikolas et. al., an iterative outlier-removal method calling a stationary point finder. We present nearly-linear time algorithms for robust regression problems with improved runtime or estimation guarantees compared to the state-of-the-art. For the general case of smooth GLMs (e.g. logistic regression), we show that the robust gradient descent framework of Prasad et. al. can be accelerated, and show our algorithm extends to optimizing the Moreau envelopes of Lipschitz GLMs (e.g. support vector machines), answering several open questions in the literature. For the well-studied case of robust linear regression, we present an alternative approach obtaining improved estimation rates over prior nearly-linear time algorithms. Interestingly, our method starts with an identifiability proof introduced in the context of the sum-of-squares algorithm of Bakshi and Prasad, which achieved optimal error rates while requiring large polynomial runtime and sample complexity. We reinterpret their proof within the Sever framework and obtain a dramatically faster and more sample-efficient algorithm under fewer distributional assumptions.
Clustering Mixture Models in Almost-Linear Time via List-Decodable Mean Estimation
Jun 16, 2021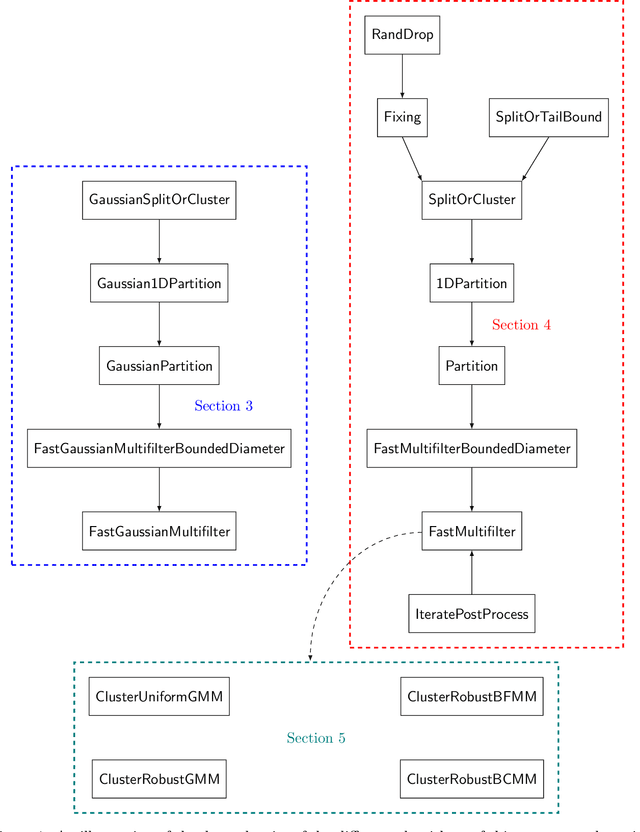
We study the problem of list-decodable mean estimation, where an adversary can corrupt a majority of the dataset. Specifically, we are given a set $T$ of $n$ points in $\mathbb{R}^d$ and a parameter $0< \alpha <\frac 1 2$ such that an $\alpha$-fraction of the points in $T$ are i.i.d. samples from a well-behaved distribution $\mathcal{D}$ and the remaining $(1-\alpha)$-fraction of the points are arbitrary. The goal is to output a small list of vectors at least one of which is close to the mean of $\mathcal{D}$. As our main contribution, we develop new algorithms for list-decodable mean estimation, achieving nearly-optimal statistical guarantees, with running time $n^{1 + o(1)} d$. All prior algorithms for this problem had additional polynomial factors in $\frac 1 \alpha$. As a corollary, we obtain the first almost-linear time algorithms for clustering mixtures of $k$ separated well-behaved distributions, nearly-matching the statistical guarantees of spectral methods. Prior clustering algorithms inherently relied on an application of $k$-PCA, thereby incurring runtimes of $\Omega(n d k)$. This marks the first runtime improvement for this basic statistical problem in nearly two decades. The starting point of our approach is a novel and simpler near-linear time robust mean estimation algorithm in the $\alpha \to 1$ regime, based on a one-shot matrix multiplicative weights-inspired potential decrease. We crucially leverage this new algorithmic framework in the context of the iterative multi-filtering technique of Diakonikolas et. al. '18, '20, providing a method to simultaneously cluster and downsample points using one-dimensional projections -- thus, bypassing the $k$-PCA subroutines required by prior algorithms.
Sparsification for Sums of Exponentials and its Algorithmic Applications
Jun 05, 2021Many works in signal processing and learning theory operate under the assumption that the underlying model is simple, e.g. that a signal is approximately $k$-Fourier-sparse or that a distribution can be approximated by a mixture model that has at most $k$ components. However the problem of fitting the parameters of such a model becomes more challenging when the frequencies/components are too close together. In this work we introduce new methods for sparsifying sums of exponentials and give various algorithmic applications. First we study Fourier-sparse interpolation without a frequency gap, where Chen et al. gave an algorithm for finding an $\epsilon$-approximate solution which uses $k' = \mbox{poly}(k, \log 1/\epsilon)$ frequencies. Second, we study learning Gaussian mixture models in one dimension without a separation condition. Kernel density estimators give an $\epsilon$-approximation that uses $k' = O(k/\epsilon^2)$ components. These methods both output models that are much more complex than what we started out with. We show how to post-process to reduce the number of frequencies/components down to $k' = \widetilde{O}(k)$, which is optimal up to logarithmic factors. Moreover we give applications to model selection. In particular, we give the first algorithms for approximately (and robustly) determining the number of components in a Gaussian mixture model that work without a separation condition.
Toward Instance-Optimal State Certification With Incoherent Measurements
Feb 25, 2021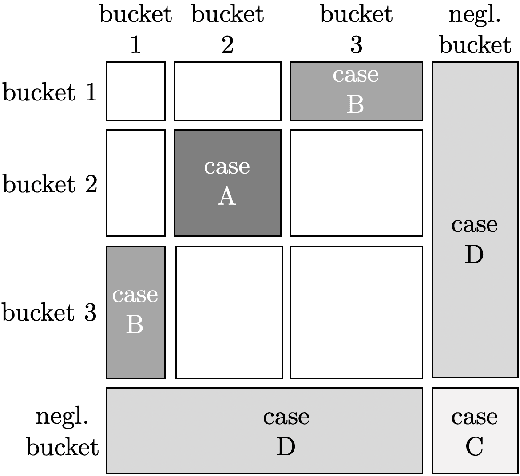
We revisit the basic problem of quantum state certification: given copies of unknown mixed state $\rho\in\mathbb{C}^{d\times d}$ and the description of a mixed state $\sigma$, decide whether $\sigma = \rho$ or $\|\sigma - \rho\|_{\mathsf{tr}} \ge \epsilon$. When $\sigma$ is maximally mixed, this is mixedness testing, and it is known that $\Omega(d^{\Theta(1)}/\epsilon^2)$ copies are necessary, where the exact exponent depends on the type of measurements the learner can make [OW15, BCL20], and in many of these settings there is a matching upper bound [OW15, BOW19, BCL20]. Can one avoid this $d^{\Theta(1)}$ dependence for certain kinds of mixed states $\sigma$, e.g. ones which are approximately low rank? More ambitiously, does there exist a simple functional $f:\mathbb{C}^{d\times d}\to\mathbb{R}_{\ge 0}$ for which one can show that $\Theta(f(\sigma)/\epsilon^2)$ copies are necessary and sufficient for state certification with respect to any $\sigma$? Such instance-optimal bounds are known in the context of classical distribution testing, e.g. [VV17]. Here we give the first bounds of this nature for the quantum setting, showing (up to log factors) that the copy complexity for state certification using nonadaptive incoherent measurements is essentially given by the copy complexity for mixedness testing times the fidelity between $\sigma$ and the maximally mixed state. Surprisingly, our bound differs substantially from instance optimal bounds for the classical problem, demonstrating a qualitative difference between the two settings.
Byzantine-Resilient Non-Convex Stochastic Gradient Descent
Dec 28, 2020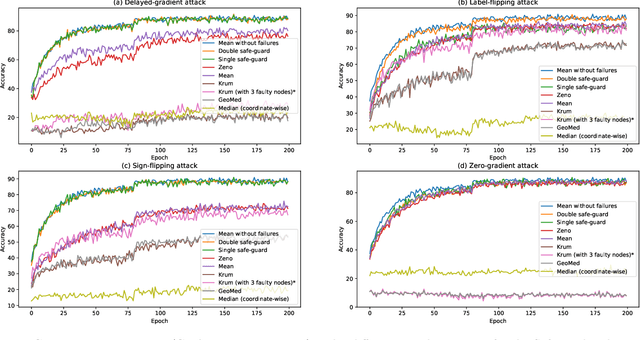
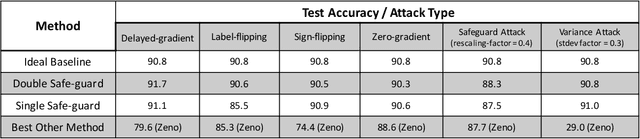
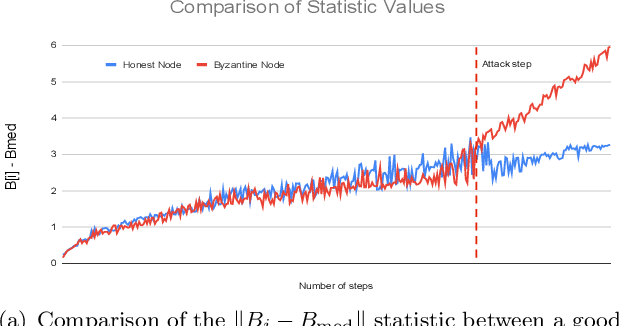
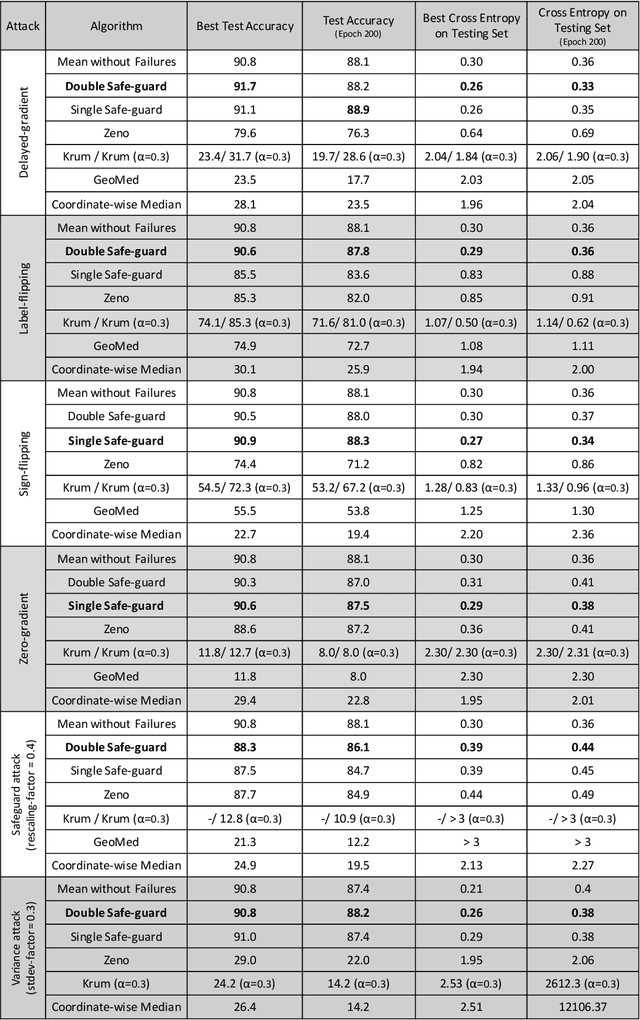
We study adversary-resilient stochastic distributed optimization, in which $m$ machines can independently compute stochastic gradients, and cooperate to jointly optimize over their local objective functions. However, an $\alpha$-fraction of the machines are $\textit{Byzantine}$, in that they may behave in arbitrary, adversarial ways. We consider a variant of this procedure in the challenging $\textit{non-convex}$ case. Our main result is a new algorithm SafeguardSGD which can provably escape saddle points and find approximate local minima of the non-convex objective. The algorithm is based on a new concentration filtering technique, and its sample and time complexity bounds match the best known theoretical bounds in the stochastic, distributed setting when no Byzantine machines are present. Our algorithm is practical: it improves upon the performance of prior methods when training deep neural networks, it is relatively lightweight, and is the first method to withstand two recently-proposed Byzantine attacks.
List-Decodable Mean Estimation in Nearly-PCA Time
Nov 19, 2020Traditionally, robust statistics has focused on designing estimators tolerant to a minority of contaminated data. Robust list-decodable learning focuses on the more challenging regime where only a minority $\frac 1 k$ fraction of the dataset is drawn from the distribution of interest, and no assumptions are made on the remaining data. We study the fundamental task of list-decodable mean estimation in high dimensions. Our main result is a new list-decodable mean estimation algorithm for bounded covariance distributions with optimal sample complexity and error rate, running in nearly-PCA time. Assuming the ground truth distribution on $\mathbb{R}^d$ has bounded covariance, our algorithm outputs a list of $O(k)$ candidate means, one of which is within distance $O(\sqrt{k})$ from the truth. Our algorithm runs in time $\widetilde{O}(ndk)$ for all $k = O(\sqrt{d}) \cup \Omega(d)$, where $n$ is the size of the dataset. We also show that a variant of our algorithm has runtime $\widetilde{O}(ndk)$ for all $k$, at the expense of an $O(\sqrt{\log k})$ factor in the recovery guarantee. This runtime matches up to logarithmic factors the cost of performing a single $k$-PCA on the data, which is a natural bottleneck of known algorithms for (very) special cases of our problem, such as clustering well-separated mixtures. Prior to our work, the fastest list-decodable mean estimation algorithms had runtimes $\widetilde{O}(n^2 d k^2)$ and $\widetilde{O}(nd k^{\ge 6})$. Our approach builds on a novel soft downweighting method, $\mathsf{SIFT}$, which is arguably the simplest known polynomial-time mean estimation technique in the list-decodable learning setting. To develop our fast algorithms, we boost the computational cost of $\mathsf{SIFT}$ via a careful "win-win-win" analysis of an approximate Ky Fan matrix multiplicative weights procedure we develop, which we believe may be of independent interest.
Statistical Query Algorithms and Low-Degree Tests Are Almost Equivalent
Sep 13, 2020Researchers currently use a number of approaches to predict and substantiate information-computation gaps in high-dimensional statistical estimation problems. A prominent approach is to characterize the limits of restricted models of computation, which on the one hand yields strong computational lower bounds for powerful classes of algorithms and on the other hand helps guide the development of efficient algorithms. In this paper, we study two of the most popular restricted computational models, the statistical query framework and low-degree polynomials, in the context of high-dimensional hypothesis testing. Our main result is that under mild conditions on the testing problem, the two classes of algorithms are essentially equivalent in power. As corollaries, we obtain new statistical query lower bounds for sparse PCA, tensor PCA and several variants of the planted clique problem.
Aligning AI With Shared Human Values
Aug 05, 2020



We show how to assess a language model's knowledge of basic concepts of morality. We introduce the ETHICS dataset, a new benchmark that spans concepts in justice, well-being, duties, virtues, and commonsense morality. Models predict widespread moral judgments about diverse text scenarios. This requires connecting physical and social world knowledge to value judgements, a capability that may enable us to filter out needlessly inflammatory chatbot outputs or eventually regularize open-ended reinforcement learning agents. With the ETHICS dataset, we find that current language models have a promising but incomplete understanding of basic ethical knowledge. Our work shows that progress can be made on machine ethics today, and it provides a steppingstone toward AI that is aligned with human values.
Well-Conditioned Methods for Ill-Conditioned Systems: Linear Regression with Semi-Random Noise
Aug 04, 2020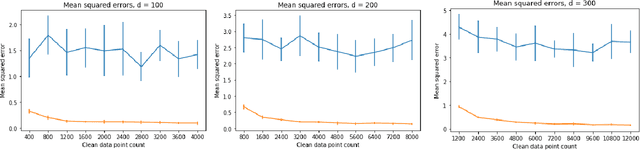
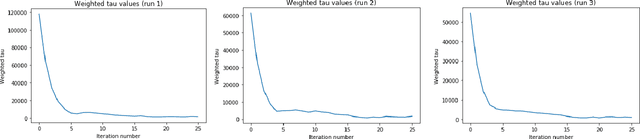
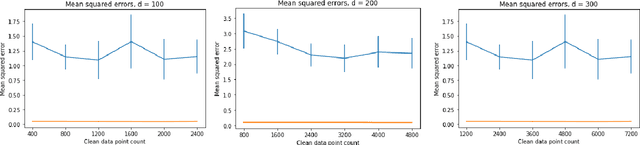
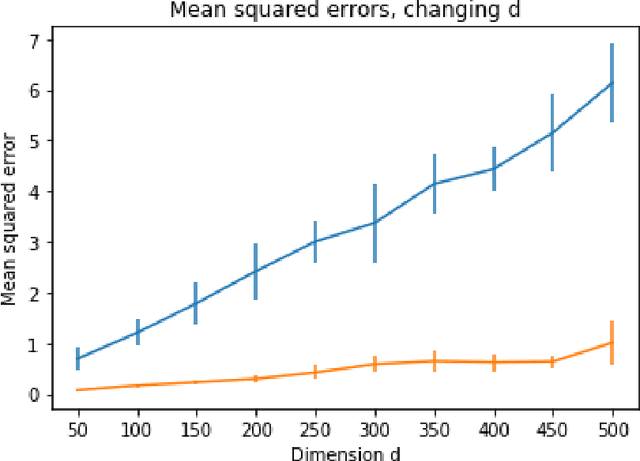
Classical iterative algorithms for linear system solving and regression are brittle to the condition number of the data matrix. Even a semi-random adversary, constrained to only give additional consistent information, can arbitrarily hinder the resulting computational guarantees of existing solvers. We show how to overcome this barrier by developing a framework which takes state-of-the-art solvers and "robustifies" them to achieve comparable guarantees against a semi-random adversary. Given a matrix which contains an (unknown) well-conditioned submatrix, our methods obtain computational and statistical guarantees as if the entire matrix was well-conditioned. We complement our theoretical results with preliminary experimental evidence, showing that our methods are effective in practice.