 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClustering Mixture Models in Almost-Linear Time via List-Decodable Mean Estimation
Jun 16, 2021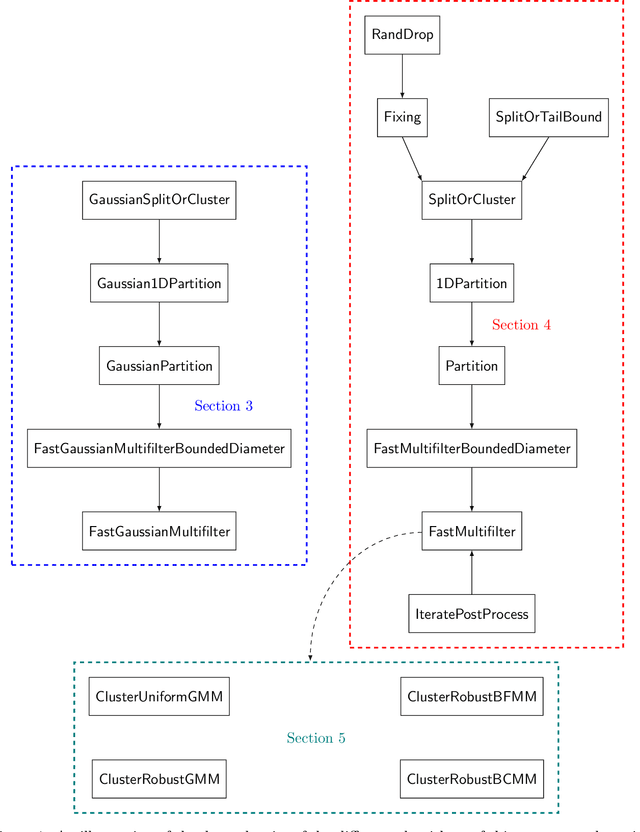
We study the problem of list-decodable mean estimation, where an adversary can corrupt a majority of the dataset. Specifically, we are given a set $T$ of $n$ points in $\mathbb{R}^d$ and a parameter $0< \alpha <\frac 1 2$ such that an $\alpha$-fraction of the points in $T$ are i.i.d. samples from a well-behaved distribution $\mathcal{D}$ and the remaining $(1-\alpha)$-fraction of the points are arbitrary. The goal is to output a small list of vectors at least one of which is close to the mean of $\mathcal{D}$. As our main contribution, we develop new algorithms for list-decodable mean estimation, achieving nearly-optimal statistical guarantees, with running time $n^{1 + o(1)} d$. All prior algorithms for this problem had additional polynomial factors in $\frac 1 \alpha$. As a corollary, we obtain the first almost-linear time algorithms for clustering mixtures of $k$ separated well-behaved distributions, nearly-matching the statistical guarantees of spectral methods. Prior clustering algorithms inherently relied on an application of $k$-PCA, thereby incurring runtimes of $\Omega(n d k)$. This marks the first runtime improvement for this basic statistical problem in nearly two decades. The starting point of our approach is a novel and simpler near-linear time robust mean estimation algorithm in the $\alpha \to 1$ regime, based on a one-shot matrix multiplicative weights-inspired potential decrease. We crucially leverage this new algorithmic framework in the context of the iterative multi-filtering technique of Diakonikolas et. al. '18, '20, providing a method to simultaneously cluster and downsample points using one-dimensional projections -- thus, bypassing the $k$-PCA subroutines required by prior algorithms.
List-Decodable Mean Estimation in Nearly-PCA Time
Nov 19, 2020Traditionally, robust statistics has focused on designing estimators tolerant to a minority of contaminated data. Robust list-decodable learning focuses on the more challenging regime where only a minority $\frac 1 k$ fraction of the dataset is drawn from the distribution of interest, and no assumptions are made on the remaining data. We study the fundamental task of list-decodable mean estimation in high dimensions. Our main result is a new list-decodable mean estimation algorithm for bounded covariance distributions with optimal sample complexity and error rate, running in nearly-PCA time. Assuming the ground truth distribution on $\mathbb{R}^d$ has bounded covariance, our algorithm outputs a list of $O(k)$ candidate means, one of which is within distance $O(\sqrt{k})$ from the truth. Our algorithm runs in time $\widetilde{O}(ndk)$ for all $k = O(\sqrt{d}) \cup \Omega(d)$, where $n$ is the size of the dataset. We also show that a variant of our algorithm has runtime $\widetilde{O}(ndk)$ for all $k$, at the expense of an $O(\sqrt{\log k})$ factor in the recovery guarantee. This runtime matches up to logarithmic factors the cost of performing a single $k$-PCA on the data, which is a natural bottleneck of known algorithms for (very) special cases of our problem, such as clustering well-separated mixtures. Prior to our work, the fastest list-decodable mean estimation algorithms had runtimes $\widetilde{O}(n^2 d k^2)$ and $\widetilde{O}(nd k^{\ge 6})$. Our approach builds on a novel soft downweighting method, $\mathsf{SIFT}$, which is arguably the simplest known polynomial-time mean estimation technique in the list-decodable learning setting. To develop our fast algorithms, we boost the computational cost of $\mathsf{SIFT}$ via a careful "win-win-win" analysis of an approximate Ky Fan matrix multiplicative weights procedure we develop, which we believe may be of independent interest.
List-Decodable Mean Estimation via Iterative Multi-Filtering
Jun 20, 2020We study the problem of {\em list-decodable mean estimation} for bounded covariance distributions. Specifically, we are given a set $T$ of points in $\mathbb{R}^d$ with the promise that an unknown $\alpha$-fraction of points in $T$, where $0< \alpha < 1/2$, are drawn from an unknown mean and bounded covariance distribution $D$, and no assumptions are made on the remaining points. The goal is to output a small list of hypothesis vectors such that at least one of them is close to the mean of $D$. We give the first practically viable estimator for this problem. In more detail, our algorithm is sample and computationally efficient, and achieves information-theoretically near-optimal error. While the only prior algorithm for this setting inherently relied on the ellipsoid method, our algorithm is iterative and only uses spectral techniques. Our main technical innovation is the design of a soft outlier removal procedure for high-dimensional heavy-tailed datasets with a majority of outliers.