 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Unions of Convex Sets via Invertible Latent Decomposition for Path Planning
Jun 10, 2026Collision-free path planning in cluttered, real-world environments relies on a representation of the collision-free space, and existing representations broadly fall into two categories. Explicit representations, such as unions of convex sets, can be plugged into optimization-based planners as hard collision-free constraints, but their parameters scale poorly with configuration-space dimension. Implicit representations, by contrast, are flexible and scale well to complex geometries, yet typically lack such guarantees. We bridge this gap with ILD (Invertible Latent Decomposition), a framework that jointly learns an invertible mapping and a union of explicit convex polytopes in the resulting latent space. Planning is carried out over these latent convex sets, and the invertible mapping decodes the resulting paths back to the original configuration space while preserving feasibility with respect to the refined explicit safe regions. We further propose Visibility-Guided Sampling (VGS) to keep the convex sets connected for path planning. Across 2D navigation, 6-DoF, and 14-DoF manipulation environments, ILD achieves broader coverage, better inter-set connectivity, and higher path-planning success rates than prior baselines, with zero observed false positives after test-time refinement. On a 14-DoF bimanual manipulator, we further demonstrate real-time collision-free planning, with test-time refinement adapting to scene-geometry changes during real-world deployment on a single 6-DoF arm.
Learning Dexterous Grasping from Sparse Taxonomy Guidance
Apr 05, 2026Dexterous manipulation requires planning a grasp configuration suited to the object and task, which is then executed through coordinated multi-finger control. However, specifying grasp plans with dense pose or contact targets for every object and task is impractical. Meanwhile, end-to-end reinforcement learning from task rewards alone lacks controllability, making it difficult for users to intervene when failures occur. To this end, we present GRIT, a two-stage framework that learns dexterous control from sparse taxonomy guidance. GRIT first predicts a taxonomy-based grasp specification from the scene and task context. Conditioned on this sparse command, a policy generates continuous finger motions that accomplish the task while preserving the intended grasp structure. Our result shows that certain grasp taxonomies are more effective for specific object geometries. By leveraging this relationship, GRIT improves generalization to novel objects over baselines and achieves an overall success rate of 87.9%. Moreover, real-world experiments demonstrate controllability, enabling grasp strategies to be adjusted through high-level taxonomy selection based on object geometry and task intent.
Teaching Robots Like Dogs: Learning Agile Navigation from Luring, Gesture, and Speech
Jan 13, 2026In this work, we aim to enable legged robots to learn how to interpret human social cues and produce appropriate behaviors through physical human guidance. However, learning through physical engagement can place a heavy burden on users when the process requires large amounts of human-provided data. To address this, we propose a human-in-the-loop framework that enables robots to acquire navigational behaviors in a data-efficient manner and to be controlled via multimodal natural human inputs, specifically gestural and verbal commands. We reconstruct interaction scenes using a physics-based simulation and aggregate data to mitigate distributional shifts arising from limited demonstration data. Our progressive goal cueing strategy adaptively feeds appropriate commands and navigation goals during training, leading to more accurate navigation and stronger alignment between human input and robot behavior. We evaluate our framework across six real-world agile navigation scenarios, including jumping over or avoiding obstacles. Our experimental results show that our proposed method succeeds in almost all trials across these scenarios, achieving a 97.15% task success rate with less than 1 hour of demonstration data in total.
Spatio-Temporal Motion Retargeting for Quadruped Robots
Apr 17, 2024This work introduces a motion retargeting approach for legged robots, which aims to create motion controllers that imitate the fine behavior of animals. Our approach, namely spatio-temporal motion retargeting (STMR), guides imitation learning procedures by transferring motion from source to target, effectively bridging the morphological disparities by ensuring the feasibility of imitation on the target system. Our STMR method comprises two components: spatial motion retargeting (SMR) and temporal motion retargeting (TMR). On the one hand, SMR tackles motion retargeting at the kinematic level by generating kinematically feasible whole-body motions from keypoint trajectories. On the other hand, TMR aims to retarget motion at the dynamic level by optimizing motion in the temporal domain. We showcase the effectiveness of our method in facilitating Imitation Learning (IL) for complex animal movements through a series of simulation and hardware experiments. In these experiments, our STMR method successfully tailored complex animal motions from various media, including video captured by a hand-held camera, to fit the morphology and physical properties of the target robots. This enabled RL policy training for precise motion tracking, while baseline methods struggled with highly dynamic motion involving flying phases. Moreover, we validated that the control policy can successfully imitate six different motions in two quadruped robots with different dimensions and physical properties in real-world settings.
Active Visual Search in the Wild
Sep 20, 2022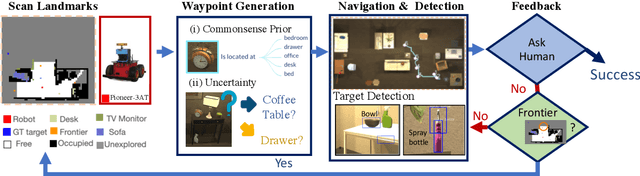
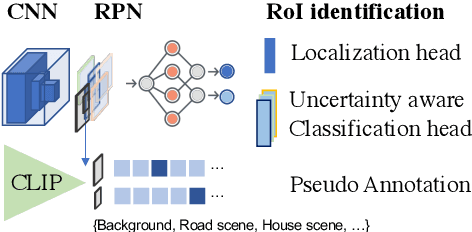

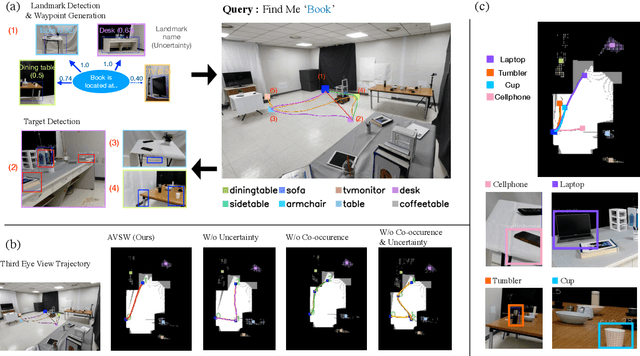
In this paper, we focus on the problem of efficiently locating a target object described with free-form language using a mobile robot equipped with vision sensors (e.g., an RGBD camera). Conventional active visual search predefines a set of objects to search for, rendering these techniques restrictive in practice. To provide added flexibility in active visual searching, we propose a system where a user can enter target commands using free-form language; we call this system Active Visual Search in the Wild (AVSW). AVSW detects and plans to search for a target object inputted by a user through a semantic grid map represented by static landmarks (e.g., desk or bed). For efficient planning of object search patterns, AVSW considers commonsense knowledge-based co-occurrence and predictive uncertainty while deciding which landmarks to visit first. We validate the proposed method with respect to SR (success rate) and SPL (success weighted by path length) in both simulated and real-world environments. The proposed method outperforms previous methods in terms of SPL in simulated scenarios with an average gap of 0.283. We further demonstrate AVSW with a Pioneer-3AT robot in real-world studies.