 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Dexterous Grasping from Sparse Taxonomy Guidance
Apr 05, 2026Dexterous manipulation requires planning a grasp configuration suited to the object and task, which is then executed through coordinated multi-finger control. However, specifying grasp plans with dense pose or contact targets for every object and task is impractical. Meanwhile, end-to-end reinforcement learning from task rewards alone lacks controllability, making it difficult for users to intervene when failures occur. To this end, we present GRIT, a two-stage framework that learns dexterous control from sparse taxonomy guidance. GRIT first predicts a taxonomy-based grasp specification from the scene and task context. Conditioned on this sparse command, a policy generates continuous finger motions that accomplish the task while preserving the intended grasp structure. Our result shows that certain grasp taxonomies are more effective for specific object geometries. By leveraging this relationship, GRIT improves generalization to novel objects over baselines and achieves an overall success rate of 87.9%. Moreover, real-world experiments demonstrate controllability, enabling grasp strategies to be adjusted through high-level taxonomy selection based on object geometry and task intent.
Trajectory-based Reinforcement Learning of Non-prehensile Manipulation Skills for Semi-Autonomous Teleoperation
Sep 27, 2021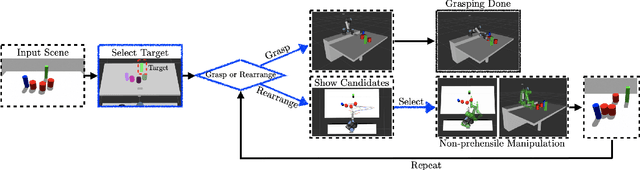
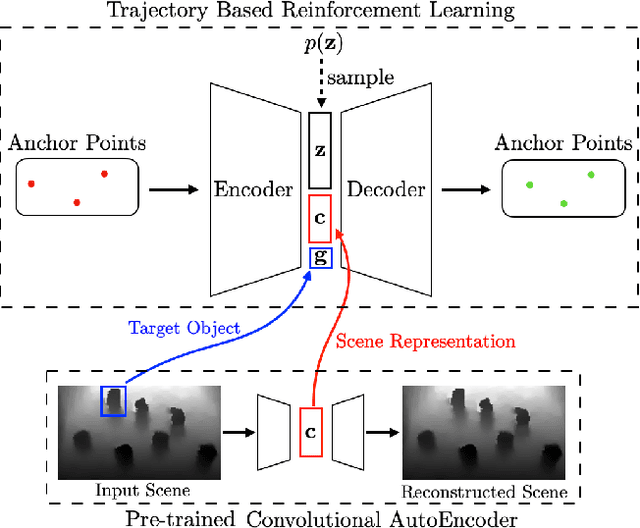
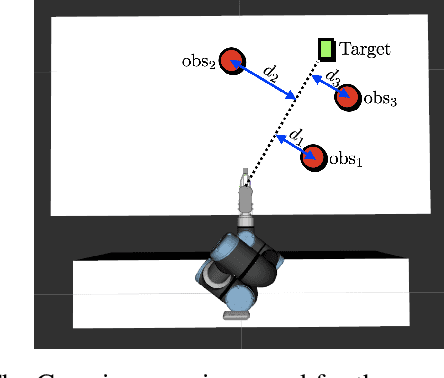
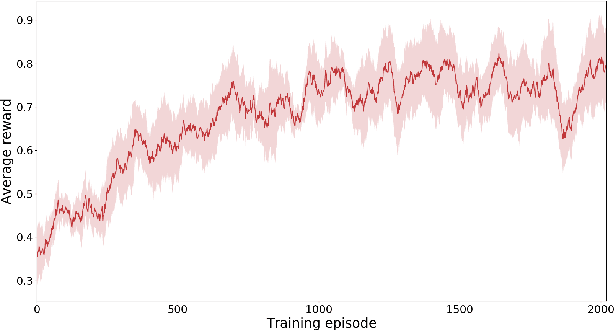
In this paper, we present a semi-autonomous teleoperation framework for a pick-and-place task using an RGB-D sensor. In particular, we assume that the target object is located in a cluttered environment where both prehensile grasping and non-prehensile manipulation are combined for efficient teleoperation. A trajectory-based reinforcement learning is utilized for learning the non-prehensile manipulation to rearrange the objects for enabling direct grasping. From the depth image of the cluttered environment and the location of the goal object, the learned policy can provide multiple options of non-prehensile manipulation to the human operator. We carefully design a reward function for the rearranging task where the policy is trained in a simulational environment. Then, the trained policy is transferred to a real-world and evaluated in a number of real-world experiments with the varying number of objects where we show that the proposed method outperforms manual keyboard control in terms of the time duration for the grasping.