 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Instruction-Finetuned Language Models
Oct 20, 2022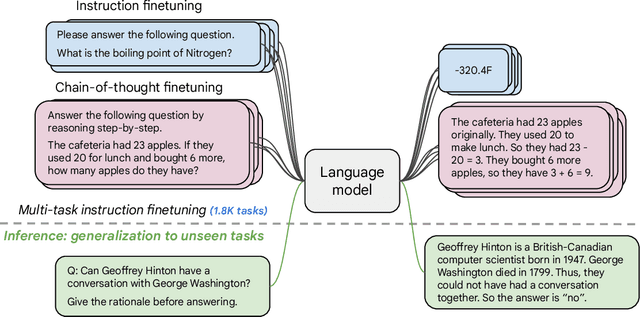

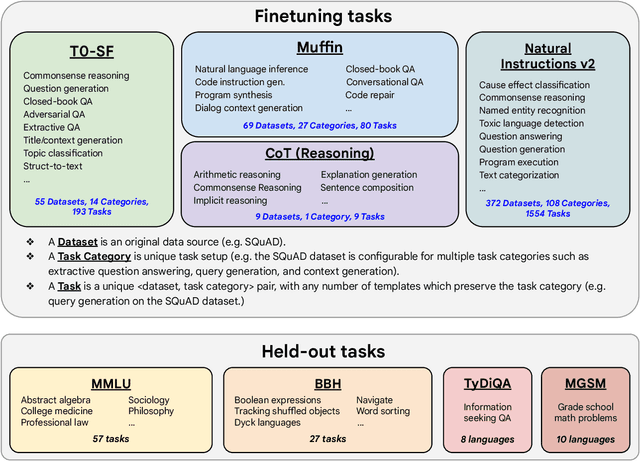

Finetuning language models on a collection of datasets phrased as instructions has been shown to improve model performance and generalization to unseen tasks. In this paper we explore instruction finetuning with a particular focus on (1) scaling the number of tasks, (2) scaling the model size, and (3) finetuning on chain-of-thought data. We find that instruction finetuning with the above aspects dramatically improves performance on a variety of model classes (PaLM, T5, U-PaLM), prompting setups (zero-shot, few-shot, CoT), and evaluation benchmarks (MMLU, BBH, TyDiQA, MGSM, open-ended generation). For instance, Flan-PaLM 540B instruction-finetuned on 1.8K tasks outperforms PALM 540B by a large margin (+9.4% on average). Flan-PaLM 540B achieves state-of-the-art performance on several benchmarks, such as 75.2% on five-shot MMLU. We also publicly release Flan-T5 checkpoints, which achieve strong few-shot performance even compared to much larger models, such as PaLM 62B. Overall, instruction finetuning is a general method for improving the performance and usability of pretrained language models.
A Review of Sparse Expert Models in Deep Learning
Sep 04, 2022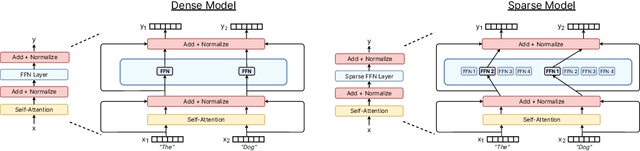

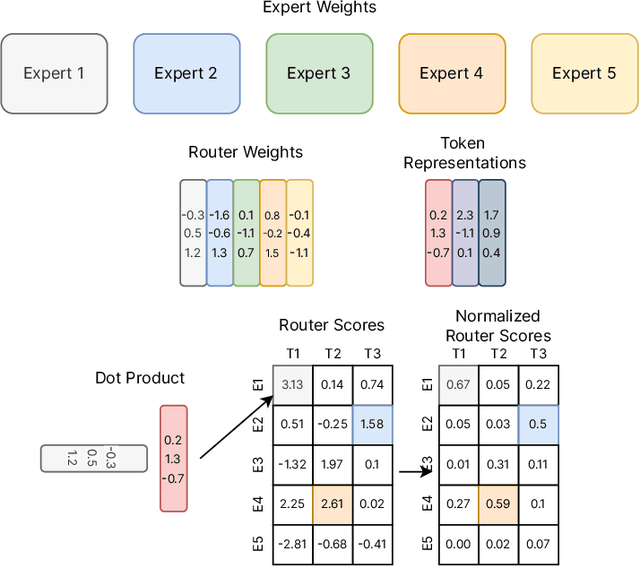

Sparse expert models are a thirty-year old concept re-emerging as a popular architecture in deep learning. This class of architecture encompasses Mixture-of-Experts, Switch Transformers, Routing Networks, BASE layers, and others, all with the unifying idea that each example is acted on by a subset of the parameters. By doing so, the degree of sparsity decouples the parameter count from the compute per example allowing for extremely large, but efficient models. The resulting models have demonstrated significant improvements across diverse domains such as natural language processing, computer vision, and speech recognition. We review the concept of sparse expert models, provide a basic description of the common algorithms, contextualize the advances in the deep learning era, and conclude by highlighting areas for future work.
Emergent Abilities of Large Language Models
Jun 15, 2022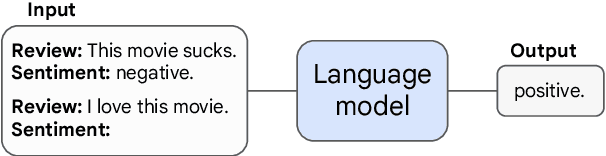
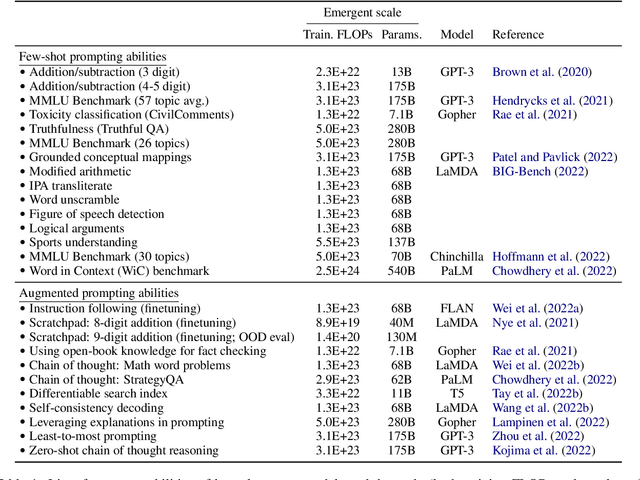
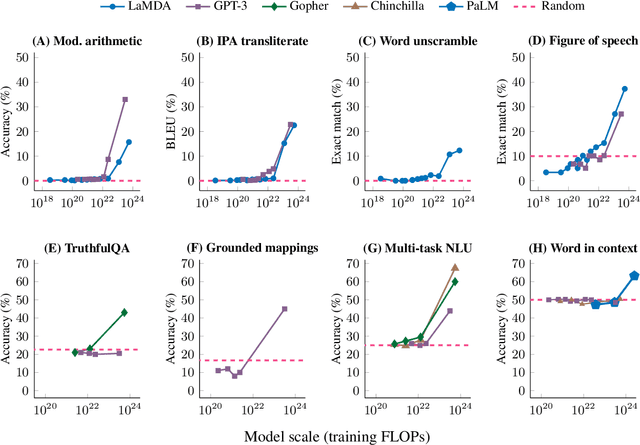
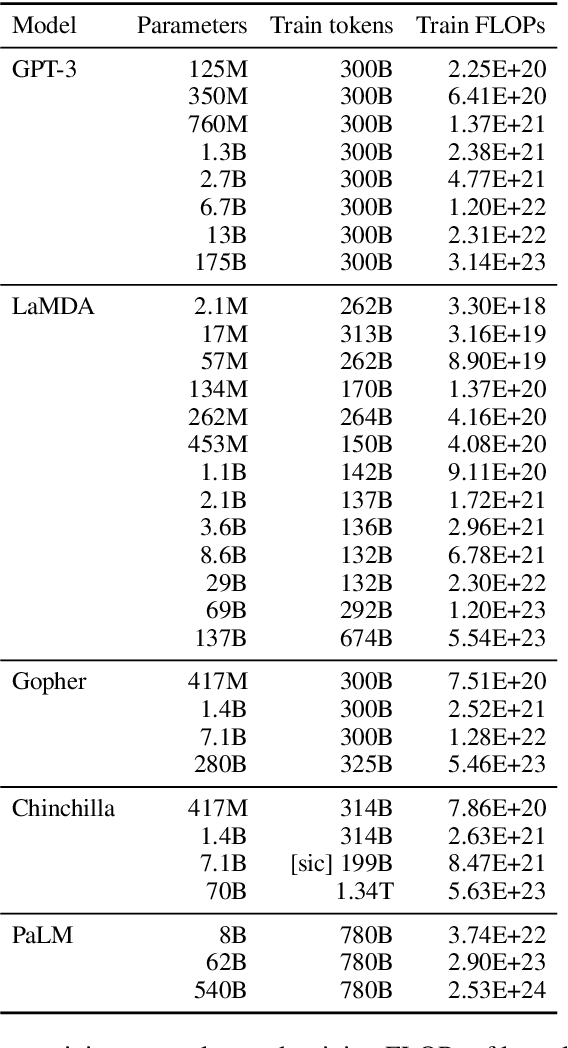
Scaling up language models has been shown to predictably improve performance and sample efficiency on a wide range of downstream tasks. This paper instead discusses an unpredictable phenomenon that we refer to as emergent abilities of large language models. We consider an ability to be emergent if it is not present in smaller models but is present in larger models. Thus, emergent abilities cannot be predicted simply by extrapolating the performance of smaller models. The existence of such emergence implies that additional scaling could further expand the range of capabilities of language models.
An Evolutionary Approach to Dynamic Introduction of Tasks in Large-scale Multitask Learning Systems
Jun 05, 2022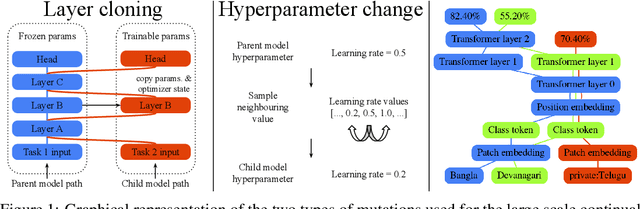


Multitask learning assumes that models capable of learning from multiple tasks can achieve better quality and efficiency via knowledge transfer, a key feature of human learning. Though, state of the art ML models rely on high customization for each task and leverage size and data scale rather than scaling the number of tasks. Also, continual learning, that adds the temporal aspect to multitask, is often focused to the study of common pitfalls such as catastrophic forgetting instead of being studied at a large scale as a critical component to build the next generation artificial intelligence. We propose an evolutionary method that can generate a large scale multitask model, and can support the dynamic and continuous addition of new tasks. The generated multitask model is sparsely activated and integrates a task-based routing that guarantees bounded compute cost and fewer added parameters per task as the model expands. The proposed method relies on a knowledge compartmentalization technique to achieve immunity against catastrophic forgetting and other common pitfalls such as gradient interference and negative transfer. We empirically show that the proposed method can jointly solve and achieve competitive results on 69image classification tasks, for example achieving the best test accuracy reported fora model trained only on public data for competitive tasks such as cifar10: 99.43%.
muNet: Evolving Pretrained Deep Neural Networks into Scalable Auto-tuning Multitask Systems
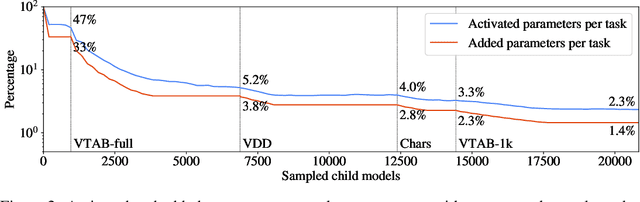
May 25, 2022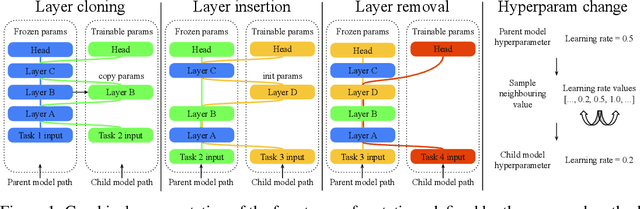
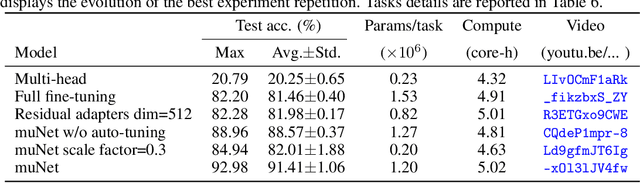
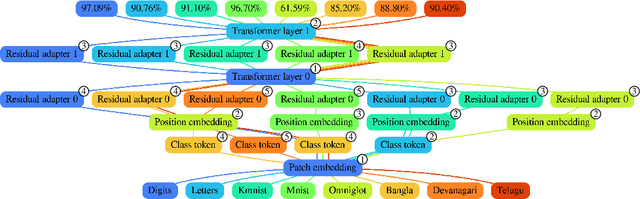
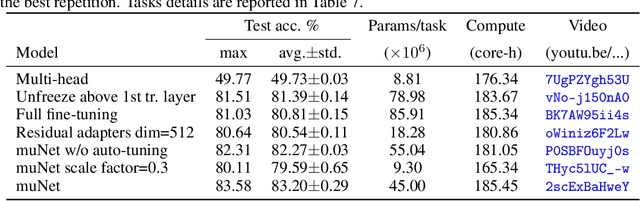
Most uses of machine learning today involve training a model from scratch for a particular task, or sometimes starting with a model pretrained on a related task and then fine-tuning on a downstream task. Both approaches offer limited knowledge transfer between different tasks, time-consuming human-driven customization to individual tasks and high computational costs especially when starting from randomly initialized models. We propose a method that uses the layers of a pretrained deep neural network as building blocks to construct an ML system that can jointly solve an arbitrary number of tasks. The resulting system can leverage cross tasks knowledge transfer, while being immune from common drawbacks of multitask approaches such as catastrophic forgetting, gradients interference and negative transfer. We define an evolutionary approach designed to jointly select the prior knowledge relevant for each task, choose the subset of the model parameters to train and dynamically auto-tune its hyperparameters. Furthermore, a novel scale control method is employed to achieve quality/size trade-offs that outperform common fine-tuning techniques. Compared with standard fine-tuning on a benchmark of 10 diverse image classification tasks, the proposed model improves the average accuracy by 2.39% while using 47% less parameters per task.
PaLM: Scaling Language Modeling with Pathways
Apr 19, 2022



Large language models have been shown to achieve remarkable performance across a variety of natural language tasks using few-shot learning, which drastically reduces the number of task-specific training examples needed to adapt the model to a particular application. To further our understanding of the impact of scale on few-shot learning, we trained a 540-billion parameter, densely activated, Transformer language model, which we call Pathways Language Model PaLM. We trained PaLM on 6144 TPU v4 chips using Pathways, a new ML system which enables highly efficient training across multiple TPU Pods. We demonstrate continued benefits of scaling by achieving state-of-the-art few-shot learning results on hundreds of language understanding and generation benchmarks. On a number of these tasks, PaLM 540B achieves breakthrough performance, outperforming the finetuned state-of-the-art on a suite of multi-step reasoning tasks, and outperforming average human performance on the recently released BIG-bench benchmark. A significant number of BIG-bench tasks showed discontinuous improvements from model scale, meaning that performance steeply increased as we scaled to our largest model. PaLM also has strong capabilities in multilingual tasks and source code generation, which we demonstrate on a wide array of benchmarks. We additionally provide a comprehensive analysis on bias and toxicity, and study the extent of training data memorization with respect to model scale. Finally, we discuss the ethical considerations related to large language models and discuss potential mitigation strategies.
The Carbon Footprint of Machine Learning Training Will Plateau, Then Shrink
Apr 11, 2022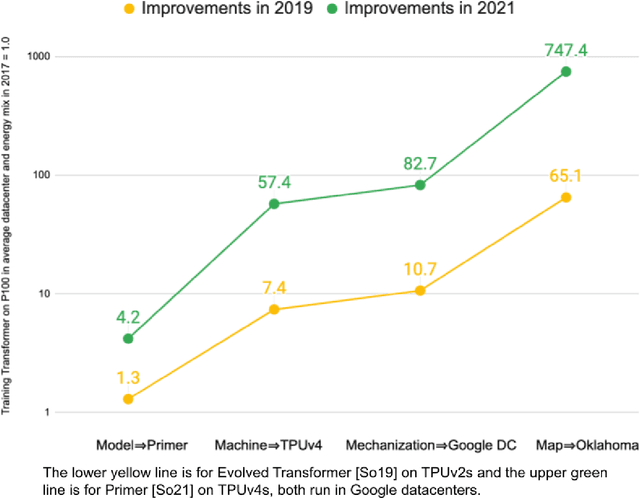
Machine Learning (ML) workloads have rapidly grown in importance, but raised concerns about their carbon footprint. Four best practices can reduce ML training energy by up to 100x and CO2 emissions up to 1000x. By following best practices, overall ML energy use (across research, development, and production) held steady at <15% of Google's total energy use for the past three years. If the whole ML field were to adopt best practices, total carbon emissions from training would reduce. Hence, we recommend that ML papers include emissions explicitly to foster competition on more than just model quality. Estimates of emissions in papers that omitted them have been off 100x-100,000x, so publishing emissions has the added benefit of ensuring accurate accounting. Given the importance of climate change, we must get the numbers right to make certain that we work on its biggest challenges.
Pathways: Asynchronous Distributed Dataflow for ML
Mar 23, 2022
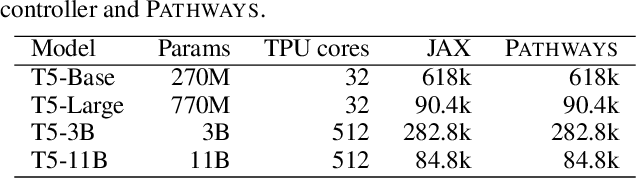
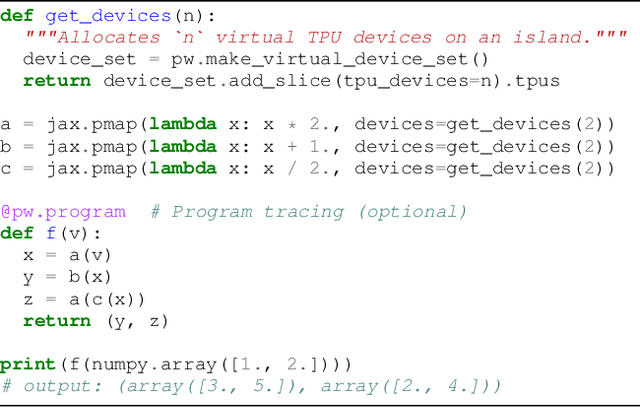
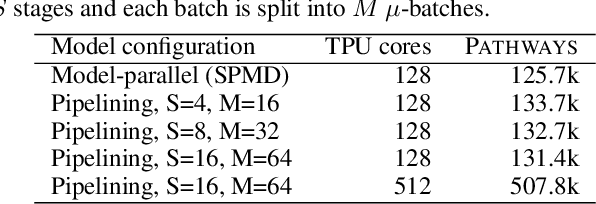
We present the design of a new large scale orchestration layer for accelerators. Our system, Pathways, is explicitly designed to enable exploration of new systems and ML research ideas, while retaining state of the art performance for current models. Pathways uses a sharded dataflow graph of asynchronous operators that consume and produce futures, and efficiently gang-schedules heterogeneous parallel computations on thousands of accelerators while coordinating data transfers over their dedicated interconnects. Pathways makes use of a novel asynchronous distributed dataflow design that lets the control plane execute in parallel despite dependencies in the data plane. This design, with careful engineering, allows Pathways to adopt a single-controller model that makes it easier to express complex new parallelism patterns. We demonstrate that Pathways can achieve performance parity (~100% accelerator utilization) with state-of-the-art systems when running SPMD computations over 2048 TPUs, while also delivering throughput comparable to the SPMD case for Transformer models that are pipelined across 16 stages, or sharded across two islands of accelerators connected over a data center network.
Designing Effective Sparse Expert Models
Feb 17, 2022
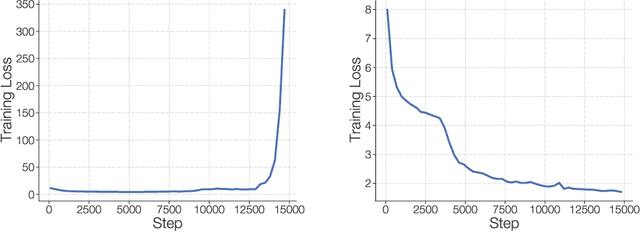

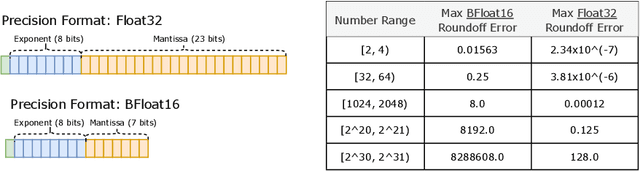
Scale has opened new frontiers in natural language processing -- but at a high cost. In response, Mixture-of-Experts (MoE) and Switch Transformers have been proposed as an energy efficient path to even larger and more capable language models. But advancing the state-of-the-art across a broad set of natural language tasks has been hindered by training instabilities and uncertain quality during fine-tuning. Our work focuses on these issues and acts as a design guide. We conclude by scaling a sparse model to 269B parameters, with a computational cost comparable to a 32B dense encoder-decoder Transformer (Stable and Transferable Mixture-of-Experts or ST-MoE-32B). For the first time, a sparse model achieves state-of-the-art performance in transfer learning, across a diverse set of tasks including reasoning (SuperGLUE, ARC Easy, ARC Challenge), summarization (XSum, CNN-DM), closed book question answering (WebQA, Natural Questions), and adversarially constructed tasks (Winogrande, ANLI R3).
Carbon Emissions and Large Neural Network Training
Apr 23, 2021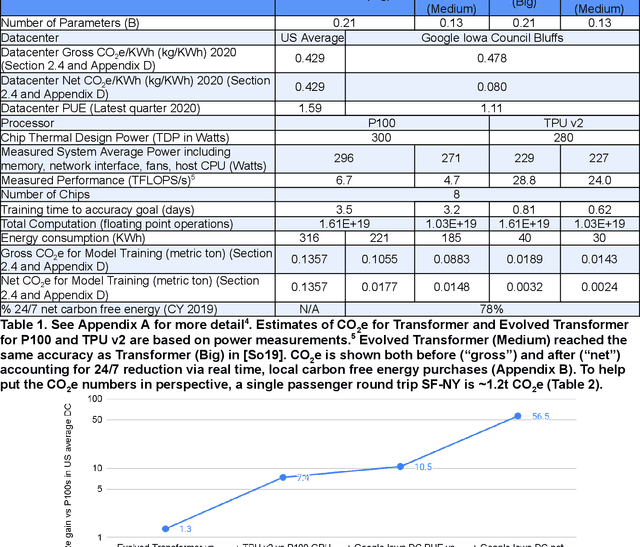

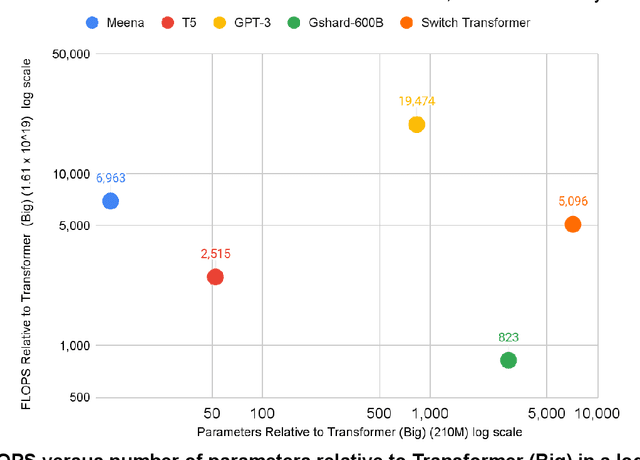
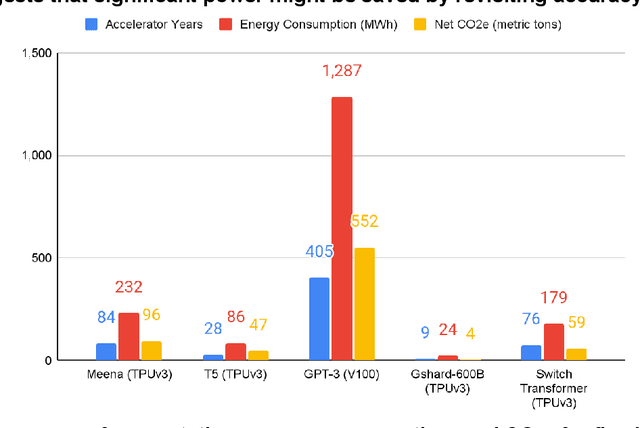
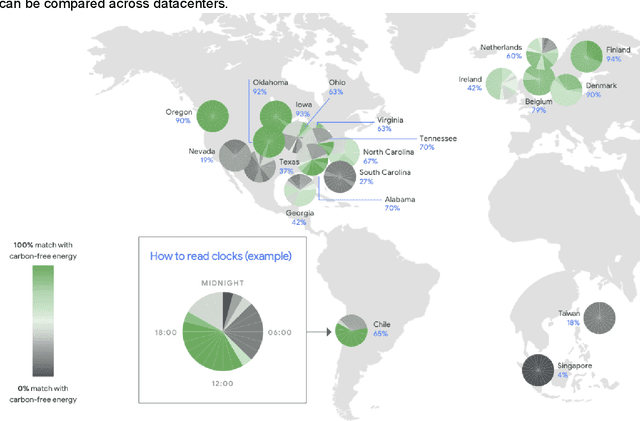
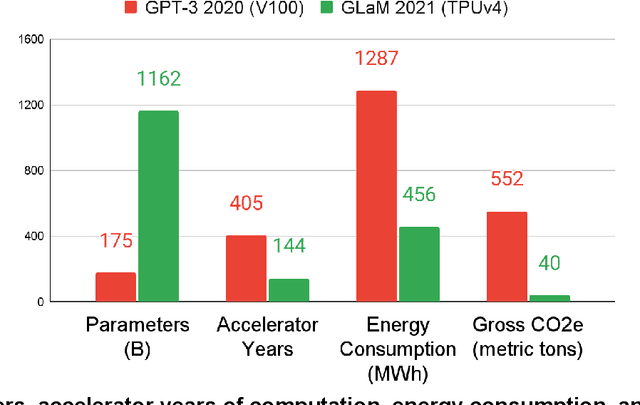
The computation demand for machine learning (ML) has grown rapidly recently, which comes with a number of costs. Estimating the energy cost helps measure its environmental impact and finding greener strategies, yet it is challenging without detailed information. We calculate the energy use and carbon footprint of several recent large models-T5, Meena, GShard, Switch Transformer, and GPT-3-and refine earlier estimates for the neural architecture search that found Evolved Transformer. We highlight the following opportunities to improve energy efficiency and CO2 equivalent emissions (CO2e): Large but sparsely activated DNNs can consume <1/10th the energy of large, dense DNNs without sacrificing accuracy despite using as many or even more parameters. Geographic location matters for ML workload scheduling since the fraction of carbon-free energy and resulting CO2e vary ~5X-10X, even within the same country and the same organization. We are now optimizing where and when large models are trained. Specific datacenter infrastructure matters, as Cloud datacenters can be ~1.4-2X more energy efficient than typical datacenters, and the ML-oriented accelerators inside them can be ~2-5X more effective than off-the-shelf systems. Remarkably, the choice of DNN, datacenter, and processor can reduce the carbon footprint up to ~100-1000X. These large factors also make retroactive estimates of energy cost difficult. To avoid miscalculations, we believe ML papers requiring large computational resources should make energy consumption and CO2e explicit when practical. We are working to be more transparent about energy use and CO2e in our future research. To help reduce the carbon footprint of ML, we believe energy usage and CO2e should be a key metric in evaluating models, and we are collaborating with MLPerf developers to include energy usage during training and inference in this industry standard benchmark.