 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeformable Kernel Networks for Joint Image Filtering
Oct 17, 2019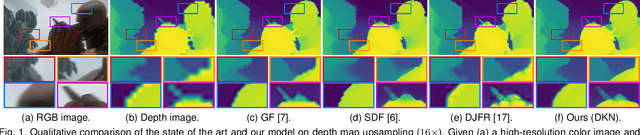
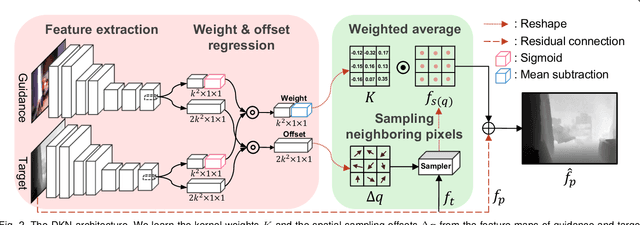

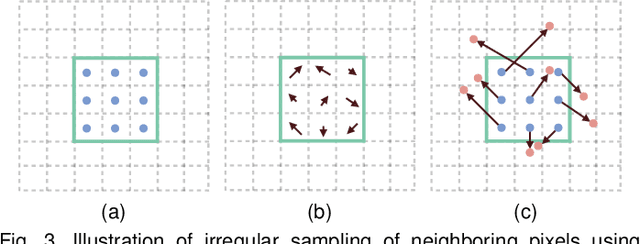
Joint image filters are used to transfer structural details from a guidance picture used as a prior to a target image, in tasks such as enhancing spatial resolution and suppressing noise. Previous methods based on convolutional neural networks (CNNs) combine nonlinear activations of spatially-invariant kernels to estimate structural details and regress the filtering result. In this paper, we instead learn explicitly sparse and spatially-variant kernels. We propose a CNN architecture and its efficient implementation, called the deformable kernel network (DKN), that outputs sets of neighbors and the corresponding weights adaptively for each pixel. The filtering result is then computed as a weighted average. We also propose a fast version of DKN that runs about seventeen times faster for an image of size 640 x 480. We demonstrate the effectiveness and flexibility of our models on the tasks of depth map upsampling, saliency map upsampling, cross-modality image restoration, texture removal, and semantic segmentation. In particular, we show that the weighted averaging process with sparsely sampled 3 x 3 kernels outperforms the state of the art by a significant margin in all cases.
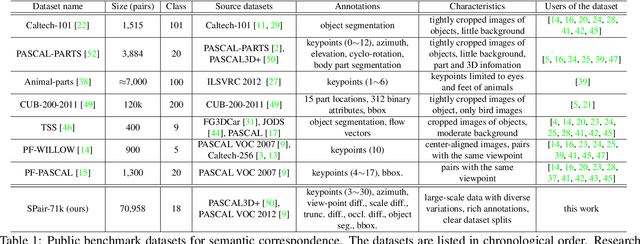
SPair-71k: A Large-scale Benchmark for Semantic Correspondence
Aug 28, 2019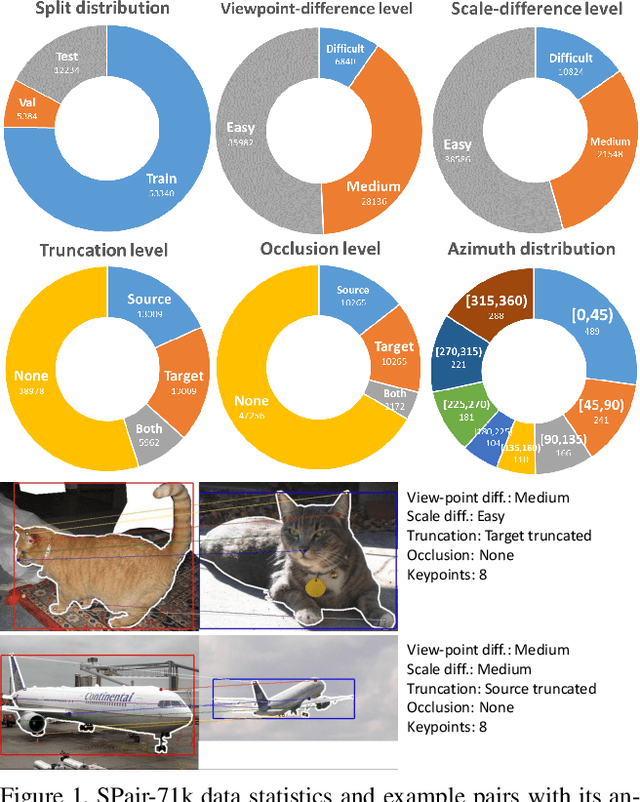
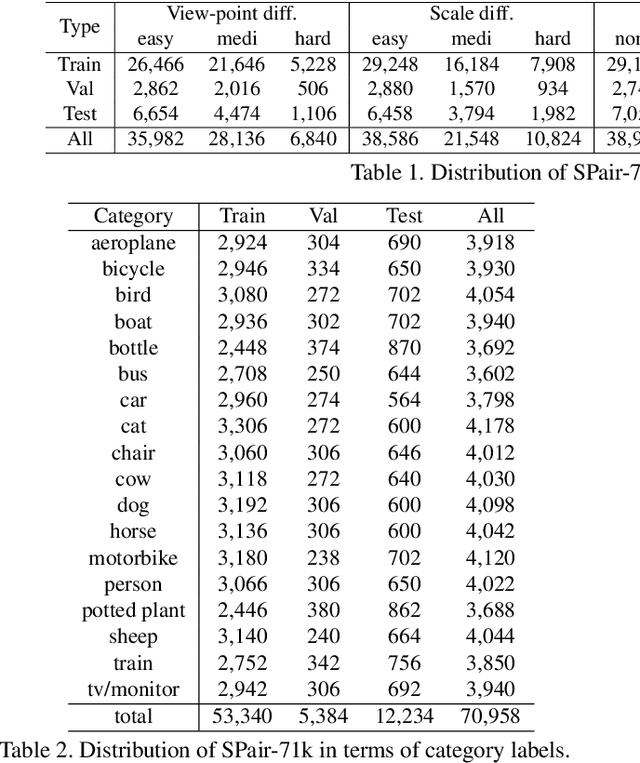
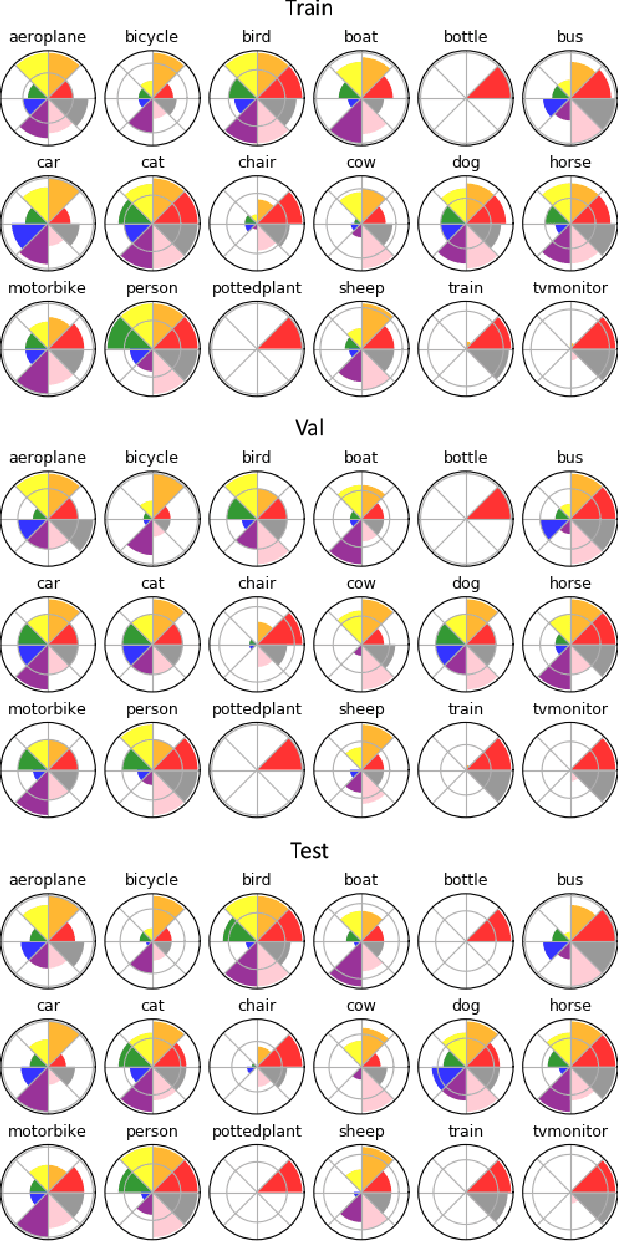
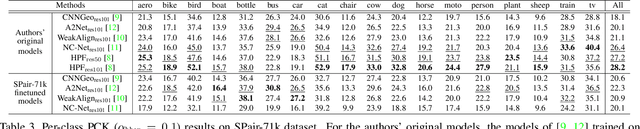
Establishing visual correspondences under large intra-class variations, which is often referred to as semantic correspondence or semantic matching, remains a challenging problem in computer vision. Despite its significance, however, most of the datasets for semantic correspondence are limited to a small amount of image pairs with similar viewpoints and scales. In this paper, we present a new large-scale benchmark dataset of semantically paired images, SPair-71k, which contains 70,958 image pairs with diverse variations in viewpoint and scale. Compared to previous datasets, it is significantly larger in number and contains more accurate and richer annotations. We believe this dataset will provide a reliable testbed to study the problem of semantic correspondence and will help to advance research in this area. We provide the results of recent methods on our new dataset as baselines for further research. Our benchmark is available online at http://cvlab.postech.ac.kr/research/SPair-71k/.
Hyperpixel Flow: Semantic Correspondence with Multi-layer Neural Features
Aug 18, 2019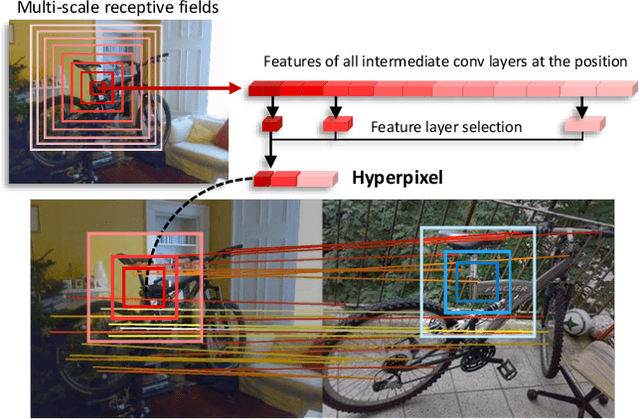

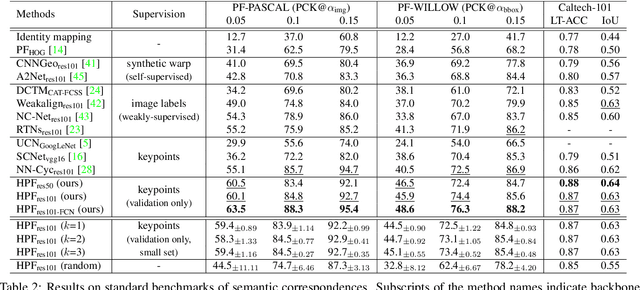
Establishing visual correspondences under large intra-class variations requires analyzing images at different levels, from features linked to semantics and context to local patterns, while being invariant to instance-specific details. To tackle these challenges, we represent images by "hyperpixels" that leverage a small number of relevant features selected among early to late layers of a convolutional neural network. Taking advantage of the condensed features of hyperpixels, we develop an effective real-time matching algorithm based on Hough geometric voting. The proposed method, hyperpixel flow, sets a new state of the art on three standard benchmarks as well as a new dataset, SPair-71k, which contains a significantly larger number of image pairs than existing datasets, with more accurate and richer annotations for in-depth analysis.
Unsupervised Image Matching and Object Discovery as Optimization
Apr 05, 2019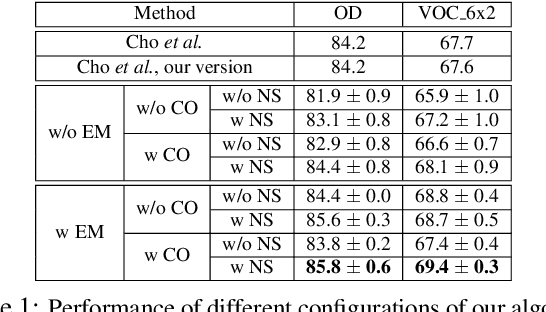
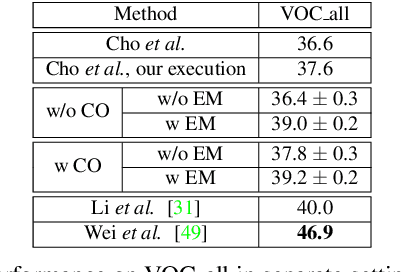

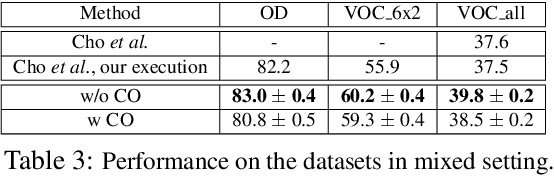
Learning with complete or partial supervision is powerful but relies on ever-growing human annotation efforts. As a way to mitigate this serious problem, as well as to serve specific applications, unsupervised learning has emerged as an important field of research. In computer vision, unsupervised learning comes in various guises. We focus here on the unsupervised discovery and matching of object categories among images in a collection, following the work of Cho et al. 2015. We show that the original approach can be reformulated and solved as a proper optimization problem. Experiments on several benchmarks establish the merit of our approach.
SFNet: Learning Object-aware Semantic Correspondence
Apr 05, 2019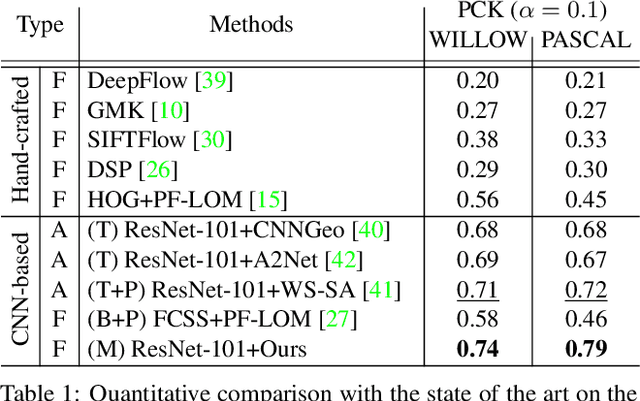
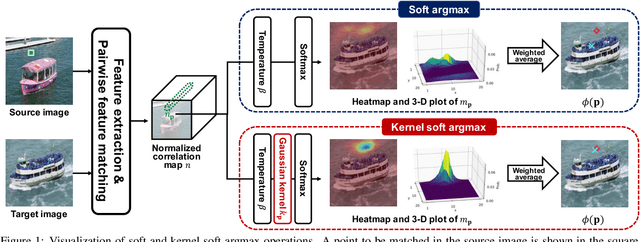
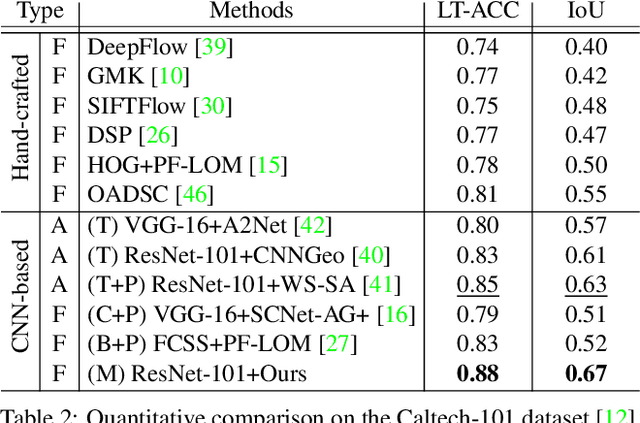

We address the problem of semantic correspondence, that is, establishing a dense flow field between images depicting different instances of the same object or scene category. We propose to use images annotated with binary foreground masks and subjected to synthetic geometric deformations to train a convolutional neural network (CNN) for this task. Using these masks as part of the supervisory signal offers a good compromise between semantic flow methods, where the amount of training data is limited by the cost of manually selecting point correspondences, and semantic alignment ones, where the regression of a single global geometric transformation between images may be sensitive to image-specific details such as background clutter. We propose a new CNN architecture, dubbed SFNet, which implements this idea. It leverages a new and differentiable version of the argmax function for end-to-end training, with a loss that combines mask and flow consistency with smoothness terms. Experimental results demonstrate the effectiveness of our approach, which significantly outperforms the state of the art on standard benchmarks.
Deformable kernel networks for guided depth map upsampling
Mar 27, 2019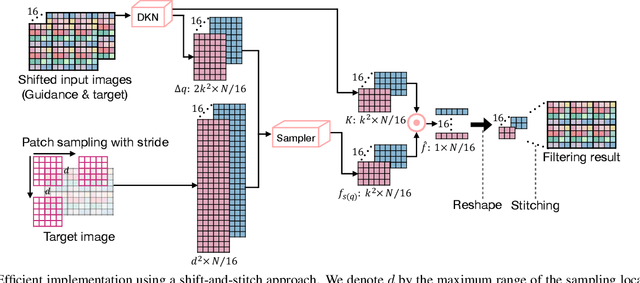

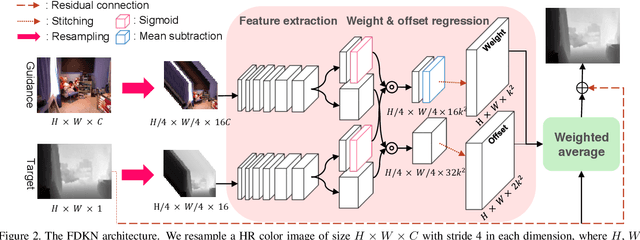
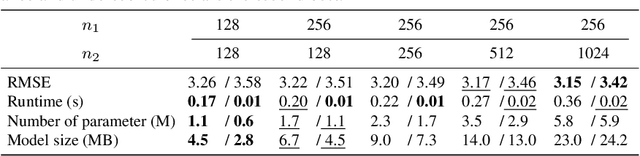
We address the problem of upsampling a low-resolution (LR) depth map using a registered high-resolution (HR) color image of the same scene. Previous methods based on convolutional neural networks (CNNs) combine nonlinear activations of spatially-invariant kernels to estimate structural details from LR depth and HR color images, and regress upsampling results directly from the networks. In this paper, we revisit the weighted averaging process that has been widely used to transfer structural details from hand-crafted visual features to LR depth maps. We instead learn explicitly sparse and spatially-variant kernels for this task. To this end, we propose a CNN architecture and its efficient implementation, called the deformable kernel network (DKN), that outputs sparse sets of neighbors and the corresponding weights adaptively for each pixel. We also propose a fast version of DKN (FDKN) that runs about 17 times faster (0.01 seconds for a HR image of size 640 x 480). Experimental results on standard benchmarks demonstrate the effectiveness of our approach. In particular, we show that the weighted averaging process with 3 x 3 kernels (i.e., aggregating 9 samples sparsely chosen) outperforms the state of the art by a significant margin.
On the Solvability of Viewing Graphs
Sep 18, 2018
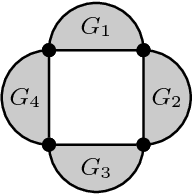
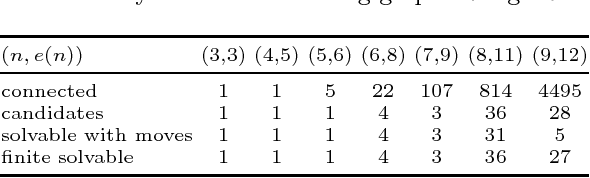

A set of fundamental matrices relating pairs of cameras in some configuration can be represented as edges of a "viewing graph". Whether or not these fundamental matrices are generically sufficient to recover the global camera configuration depends on the structure of this graph. We study characterizations of "solvable" viewing graphs and present several new results that can be applied to determine which pairs of views may be used to recover all camera parameters. We also discuss strategies for verifying the solvability of a graph computationally.
SCNet: Learning Semantic Correspondence
Aug 17, 2017
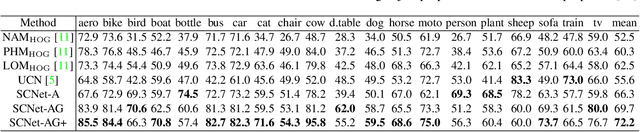
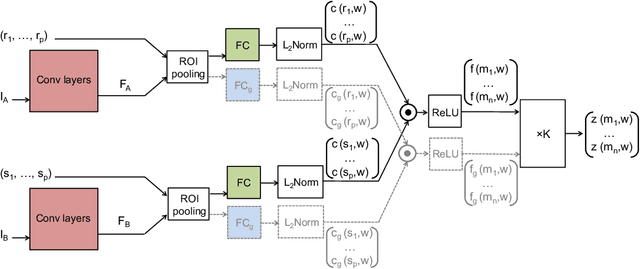
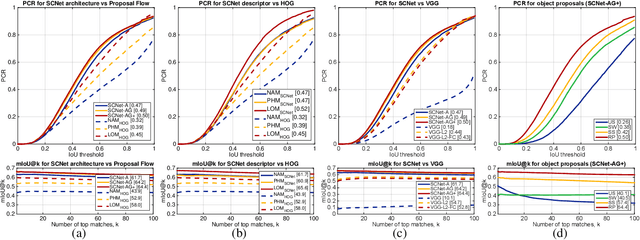
This paper addresses the problem of establishing semantic correspondences between images depicting different instances of the same object or scene category. Previous approaches focus on either combining a spatial regularizer with hand-crafted features, or learning a correspondence model for appearance only. We propose instead a convolutional neural network architecture, called SCNet, for learning a geometrically plausible model for semantic correspondence. SCNet uses region proposals as matching primitives, and explicitly incorporates geometric consistency in its loss function. It is trained on image pairs obtained from the PASCAL VOC 2007 keypoint dataset, and a comparative evaluation on several standard benchmarks demonstrates that the proposed approach substantially outperforms both recent deep learning architectures and previous methods based on hand-crafted features.
General models for rational cameras and the case of two-slit projections
Apr 11, 2017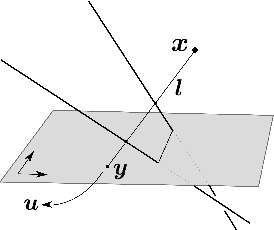
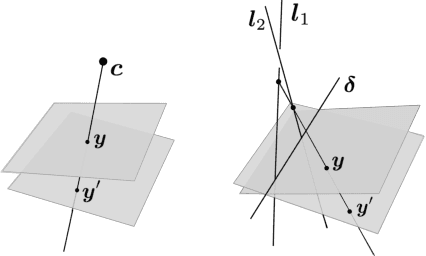
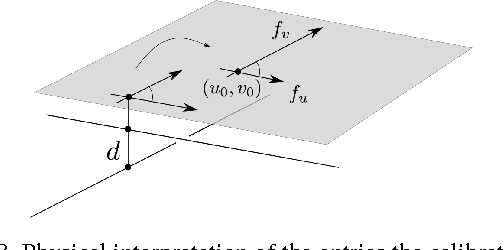
The rational camera model recently introduced in [19] provides a general methodology for studying abstract nonlinear imaging systems and their multi-view geometry. This paper builds on this framework to study "physical realizations" of rational cameras. More precisely, we give an explicit account of the mapping between between physical visual rays and image points (missing in the original description), which allows us to give simple analytical expressions for direct and inverse projections. We also consider "primitive" camera models, that are orbits under the action of various projective transformations, and lead to a general notion of intrinsic parameters. The methodology is general, but it is illustrated concretely by an in-depth study of two-slit cameras, that we model using pairs of linear projections. This simple analytical form allows us to describe models for the corresponding primitive cameras, to introduce intrinsic parameters with a clear geometric meaning, and to define an epipolar tensor characterizing two-view correspondences. In turn, this leads to new algorithms for structure from motion and self-calibration.
Proposal Flow: Semantic Correspondences from Object Proposals
Mar 21, 2017


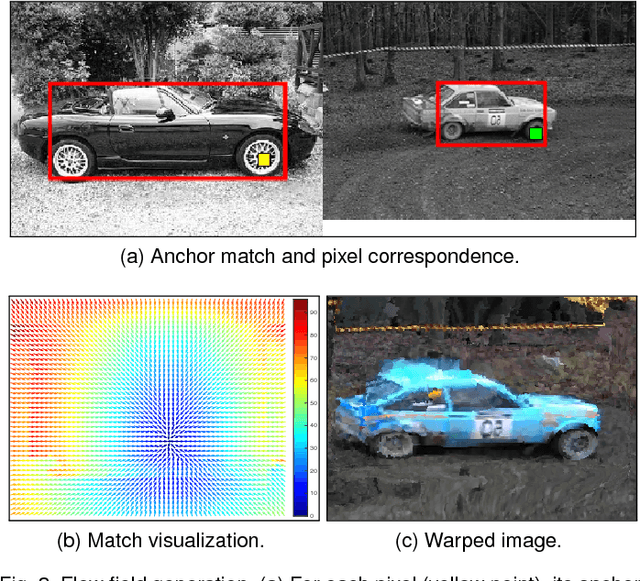
Finding image correspondences remains a challenging problem in the presence of intra-class variations and large changes in scene layout. Semantic flow methods are designed to handle images depicting different instances of the same object or scene category. We introduce a novel approach to semantic flow, dubbed proposal flow, that establishes reliable correspondences using object proposals. Unlike prevailing semantic flow approaches that operate on pixels or regularly sampled local regions, proposal flow benefits from the characteristics of modern object proposals, that exhibit high repeatability at multiple scales, and can take advantage of both local and geometric consistency constraints among proposals. We also show that the corresponding sparse proposal flow can effectively be transformed into a conventional dense flow field. We introduce two new challenging datasets that can be used to evaluate both general semantic flow techniques and region-based approaches such as proposal flow. We use these benchmarks to compare different matching algorithms, object proposals, and region features within proposal flow, to the state of the art in semantic flow. This comparison, along with experiments on standard datasets, demonstrates that proposal flow significantly outperforms existing semantic flow methods in various settings.