 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLorentz Group Equivariant Autoencoders
Dec 14, 2022There has been significant work recently in developing machine learning models in high energy physics (HEP), for tasks such as classification, simulation, and anomaly detection. Typically, these models are adapted from those designed for datasets in computer vision or natural language processing without necessarily incorporating inductive biases suited to HEP data, such as respecting its inherent symmetries. Such inductive biases can make the model more performant and interpretable, and reduce the amount of training data needed. To that end, we develop the Lorentz group autoencoder (LGAE), an autoencoder model equivariant with respect to the proper, orthochronous Lorentz group $\mathrm{SO}^+(3,1)$, with a latent space living in the representations of the group. We present our architecture and several experimental results on jets at the LHC and find it significantly outperforms a non-Lorentz-equivariant graph neural network baseline on compression and reconstruction, and anomaly detection. We also demonstrate the advantage of such an equivariant model in analyzing the latent space of the autoencoder, which can have a significant impact on the explainability of anomalies found by such black-box machine learning models.
On the Evaluation of Generative Models in High Energy Physics
Nov 18, 2022



There has been a recent explosion in research into machine-learning-based generative modeling to tackle computational challenges for simulations in high energy physics (HEP). In order to use such alternative simulators in practice, we need well defined metrics to compare different generative models and evaluate their discrepancy from the true distributions. We present the first systematic review and investigation into evaluation metrics and their sensitivity to failure modes of generative models, using the framework of two-sample goodness-of-fit testing, and their relevance and viability for HEP. Inspired by previous work in both physics and computer vision, we propose two new metrics, the Fr\'echet and kernel physics distances (FPD and KPD), and perform a variety of experiments measuring their performance on simple Gaussian-distributed, and simulated high energy jet datasets. We find FPD, in particular, to be the most sensitive metric to all alternative jet distributions tested and recommend its adoption, along with the KPD and Wasserstein distances between individual feature distributions, for evaluating generative models in HEP. We finally demonstrate the efficacy of these proposed metrics in evaluating and comparing a novel attention-based generative adversarial particle transformer to the state-of-the-art message-passing generative adversarial network jet simulation model.
Do graph neural networks learn traditional jet substructure?
Nov 17, 2022



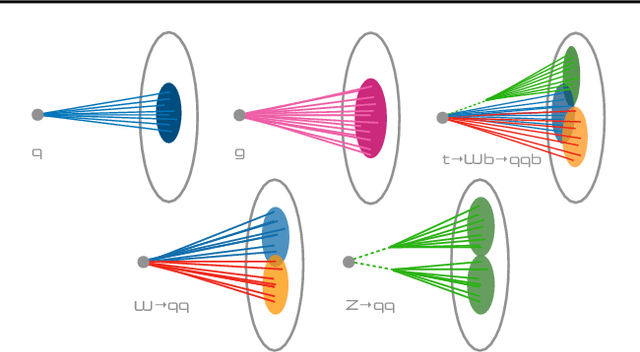
At the CERN LHC, the task of jet tagging, whose goal is to infer the origin of a jet given a set of final-state particles, is dominated by machine learning methods. Graph neural networks have been used to address this task by treating jets as point clouds with underlying, learnable, edge connections between the particles inside. We explore the decision-making process for one such state-of-the-art network, ParticleNet, by looking for relevant edge connections identified using the layerwise-relevance propagation technique. As the model is trained, we observe changes in the distribution of relevant edges connecting different intermediate clusters of particles, known as subjets. The resulting distribution of subjet connections is different for signal jets originating from top quarks, whose subjets typically correspond to its three decay products, and background jets originating from lighter quarks and gluons. This behavior indicates that the model is using traditional jet substructure observables, such as the number of prongs -- energetic particle clusters -- within a jet, when identifying jets.
FastStamp: Accelerating Neural Steganography and Digital Watermarking of Images on FPGAs
Sep 26, 2022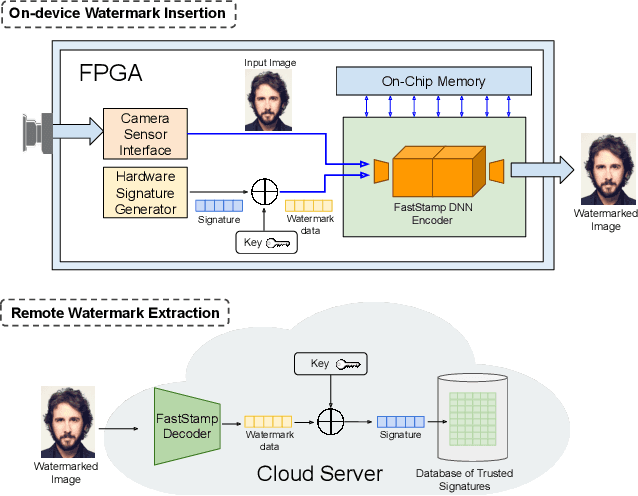
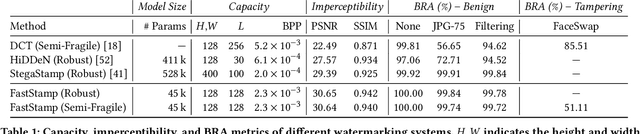
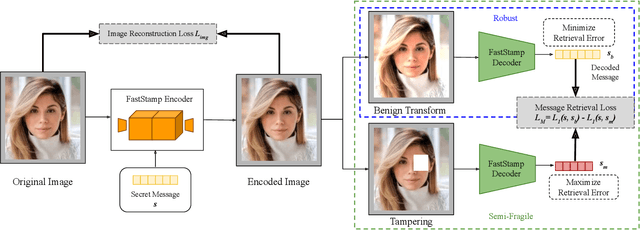

Steganography and digital watermarking are the tasks of hiding recoverable data in image pixels. Deep neural network (DNN) based image steganography and watermarking techniques are quickly replacing traditional hand-engineered pipelines. DNN based watermarking techniques have drastically improved the message capacity, imperceptibility and robustness of the embedded watermarks. However, this improvement comes at the cost of increased computational overhead of the watermark encoder neural network. In this work, we design the first accelerator platform FastStamp to perform DNN based steganography and digital watermarking of images on hardware. We first propose a parameter efficient DNN model for embedding recoverable bit-strings in image pixels. Our proposed model can match the success metrics of prior state-of-the-art DNN based watermarking methods while being significantly faster and lighter in terms of memory footprint. We then design an FPGA based accelerator framework to further improve the model throughput and power consumption by leveraging data parallelism and customized computation paths. FastStamp allows embedding hardware signatures into images to establish media authenticity and ownership of digital media. Our best design achieves 68 times faster inference as compared to GPU implementations of prior DNN based watermark encoder while consuming less power.
Data Science and Machine Learning in Education
Jul 19, 2022
The growing role of data science (DS) and machine learning (ML) in high-energy physics (HEP) is well established and pertinent given the complex detectors, large data, sets and sophisticated analyses at the heart of HEP research. Moreover, exploiting symmetries inherent in physics data have inspired physics-informed ML as a vibrant sub-field of computer science research. HEP researchers benefit greatly from materials widely available materials for use in education, training and workforce development. They are also contributing to these materials and providing software to DS/ML-related fields. Increasingly, physics departments are offering courses at the intersection of DS, ML and physics, often using curricula developed by HEP researchers and involving open software and data used in HEP. In this white paper, we explore synergies between HEP research and DS/ML education, discuss opportunities and challenges at this intersection, and propose community activities that will be mutually beneficial.
FastML Science Benchmarks: Accelerating Real-Time Scientific Edge Machine Learning
Jul 16, 2022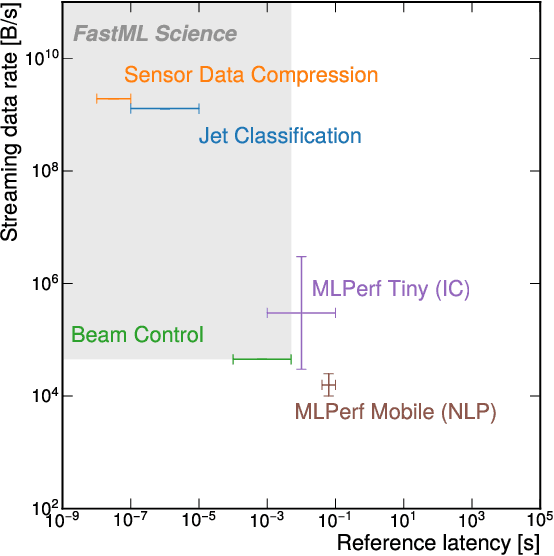
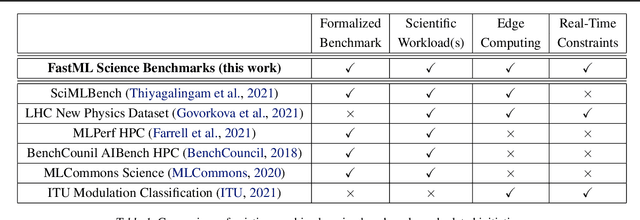

Applications of machine learning (ML) are growing by the day for many unique and challenging scientific applications. However, a crucial challenge facing these applications is their need for ultra low-latency and on-detector ML capabilities. Given the slowdown in Moore's law and Dennard scaling, coupled with the rapid advances in scientific instrumentation that is resulting in growing data rates, there is a need for ultra-fast ML at the extreme edge. Fast ML at the edge is essential for reducing and filtering scientific data in real-time to accelerate science experimentation and enable more profound insights. To accelerate real-time scientific edge ML hardware and software solutions, we need well-constrained benchmark tasks with enough specifications to be generically applicable and accessible. These benchmarks can guide the design of future edge ML hardware for scientific applications capable of meeting the nanosecond and microsecond level latency requirements. To this end, we present an initial set of scientific ML benchmarks, covering a variety of ML and embedded system techniques.
Open-source FPGA-ML codesign for the MLPerf Tiny Benchmark
Jun 23, 2022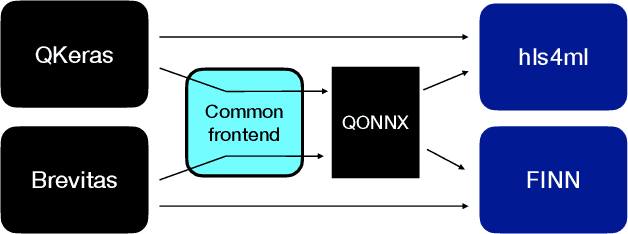
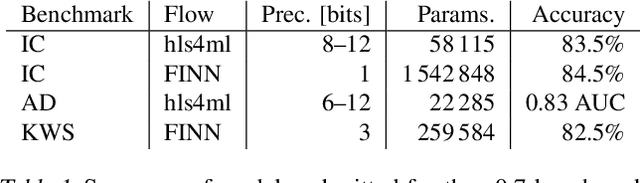
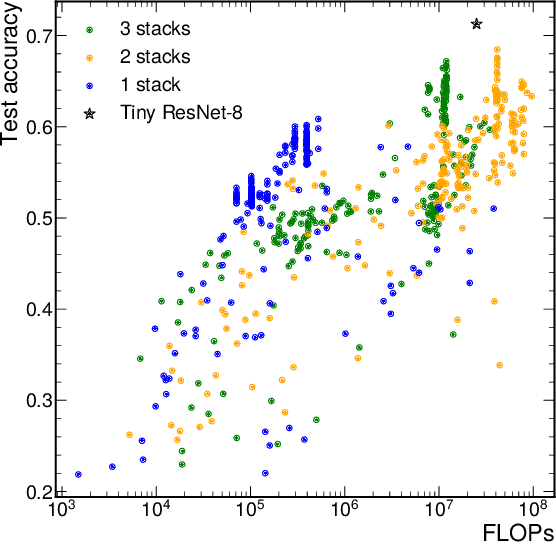
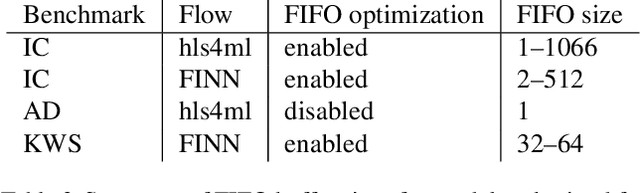
We present our development experience and recent results for the MLPerf Tiny Inference Benchmark on field-programmable gate array (FPGA) platforms. We use the open-source hls4ml and FINN workflows, which aim to democratize AI-hardware codesign of optimized neural networks on FPGAs. We present the design and implementation process for the keyword spotting, anomaly detection, and image classification benchmark tasks. The resulting hardware implementations are quantized, configurable, spatial dataflow architectures tailored for speed and efficiency and introduce new generic optimizations and common workflows developed as a part of this work. The full workflow is presented from quantization-aware training to FPGA implementation. The solutions are deployed on system-on-chip (Pynq-Z2) and pure FPGA (Arty A7-100T) platforms. The resulting submissions achieve latencies as low as 20 $\mu$s and energy consumption as low as 30 $\mu$J per inference. We demonstrate how emerging ML benchmarks on heterogeneous hardware platforms can catalyze collaboration and the development of new techniques and more accessible tools.
QONNX: Representing Arbitrary-Precision Quantized Neural Networks
Jun 17, 2022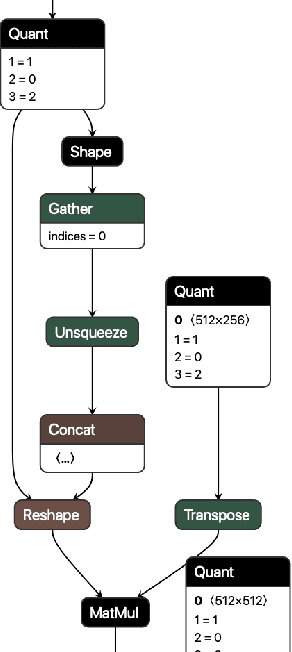
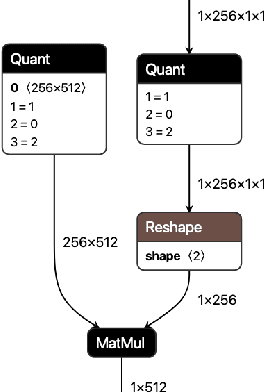
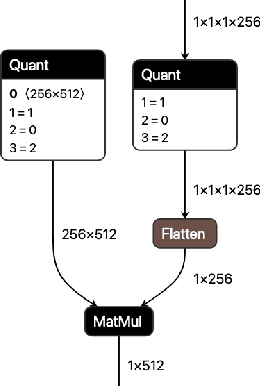
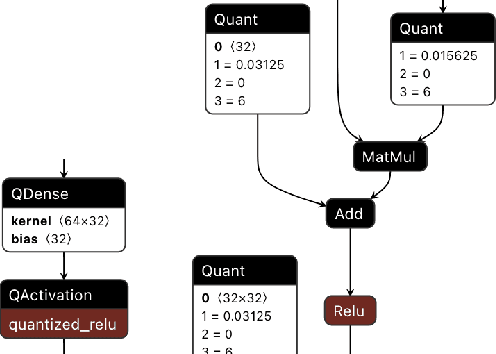
We present extensions to the Open Neural Network Exchange (ONNX) intermediate representation format to represent arbitrary-precision quantized neural networks. We first introduce support for low precision quantization in existing ONNX-based quantization formats by leveraging integer clipping, resulting in two new backward-compatible variants: the quantized operator format with clipping and quantize-clip-dequantize (QCDQ) format. We then introduce a novel higher-level ONNX format called quantized ONNX (QONNX) that introduces three new operators -- Quant, BipolarQuant, and Trunc -- in order to represent uniform quantization. By keeping the QONNX IR high-level and flexible, we enable targeting a wider variety of platforms. We also present utilities for working with QONNX, as well as examples of its usage in the FINN and hls4ml toolchains. Finally, we introduce the QONNX model zoo to share low-precision quantized neural networks.
Physics Community Needs, Tools, and Resources for Machine Learning
Mar 30, 2022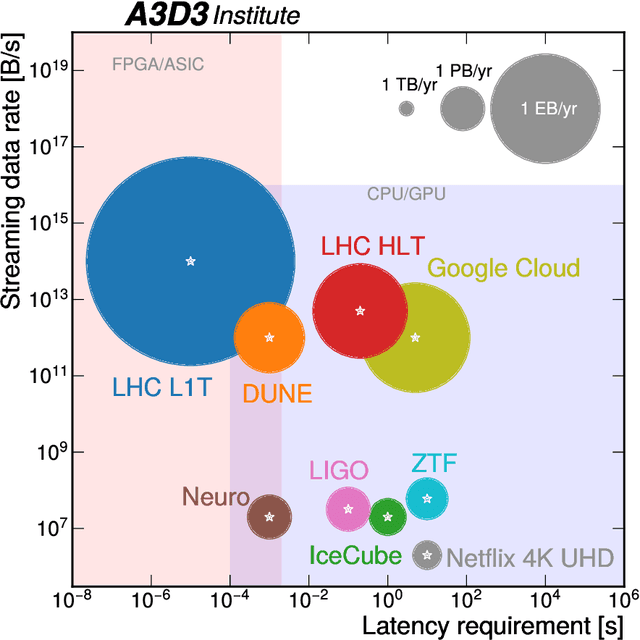

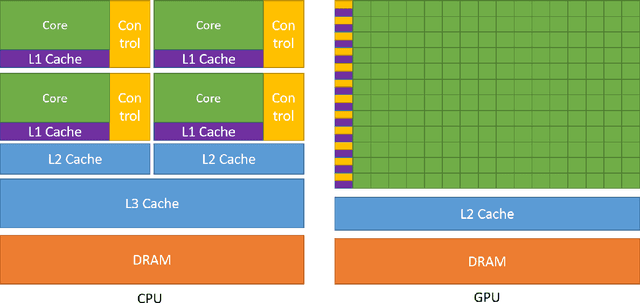
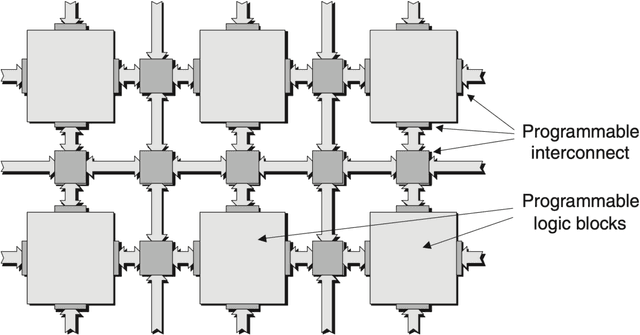
Machine learning (ML) is becoming an increasingly important component of cutting-edge physics research, but its computational requirements present significant challenges. In this white paper, we discuss the needs of the physics community regarding ML across latency and throughput regimes, the tools and resources that offer the possibility of addressing these needs, and how these can be best utilized and accessed in the coming years.
Graph Neural Networks in Particle Physics: Implementations, Innovations, and Challenges
Mar 25, 2022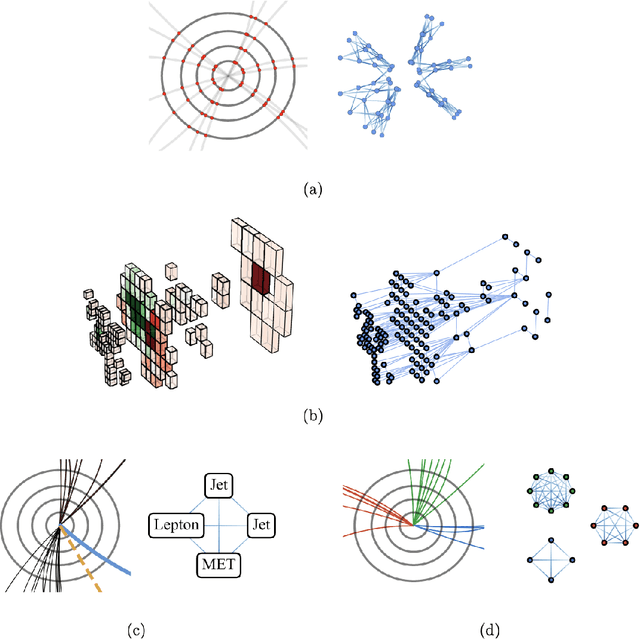
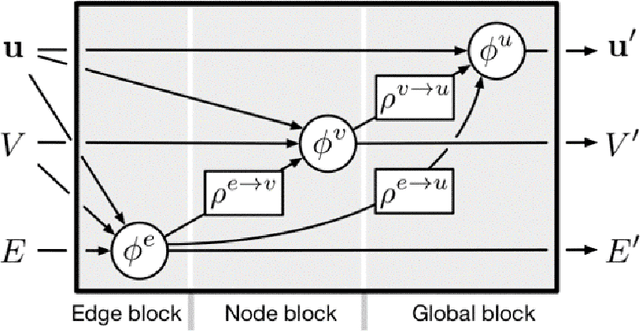
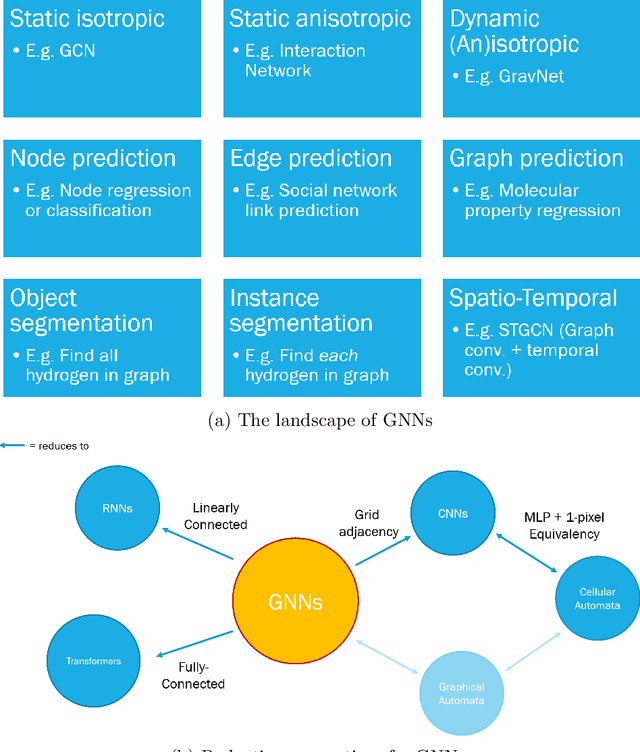
Many physical systems can be best understood as sets of discrete data with associated relationships. Where previously these sets of data have been formulated as series or image data to match the available machine learning architectures, with the advent of graph neural networks (GNNs), these systems can be learned natively as graphs. This allows a wide variety of high- and low-level physical features to be attached to measurements and, by the same token, a wide variety of HEP tasks to be accomplished by the same GNN architectures. GNNs have found powerful use-cases in reconstruction, tagging, generation and end-to-end analysis. With the wide-spread adoption of GNNs in industry, the HEP community is well-placed to benefit from rapid improvements in GNN latency and memory usage. However, industry use-cases are not perfectly aligned with HEP and much work needs to be done to best match unique GNN capabilities to unique HEP obstacles. We present here a range of these capabilities, predictions of which are currently being well-adopted in HEP communities, and which are still immature. We hope to capture the landscape of graph techniques in machine learning as well as point out the most significant gaps that are inhibiting potentially large leaps in research.