 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSearching for More Efficient Dynamic Programs
Sep 14, 2021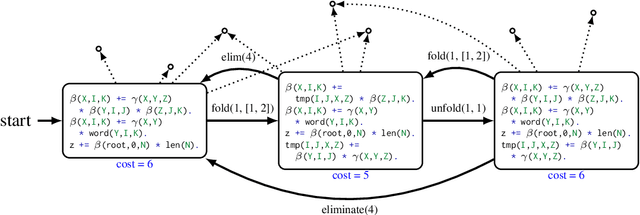
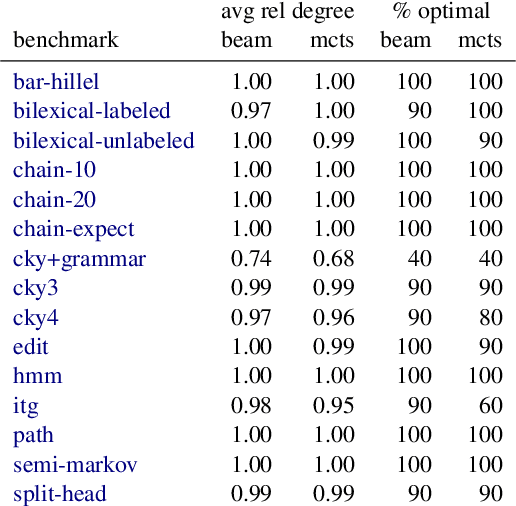

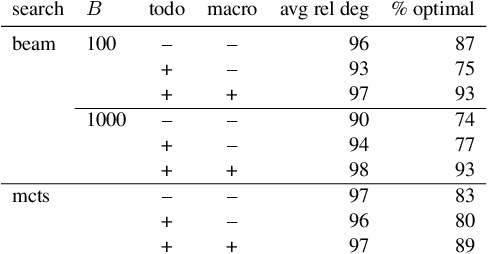
Computational models of human language often involve combinatorial problems. For instance, a probabilistic parser may marginalize over exponentially many trees to make predictions. Algorithms for such problems often employ dynamic programming and are not always unique. Finding one with optimal asymptotic runtime can be unintuitive, time-consuming, and error-prone. Our work aims to automate this laborious process. Given an initial correct declarative program, we search for a sequence of semantics-preserving transformations to improve its running time as much as possible. To this end, we describe a set of program transformations, a simple metric for assessing the efficiency of a transformed program, and a heuristic search procedure to improve this metric. We show that in practice, automated search -- like the mental search performed by human programmers -- can find substantial improvements to the initial program. Empirically, we show that many common speed-ups described in the NLP literature could have been discovered automatically by our system.
Constrained Language Models Yield Few-Shot Semantic Parsers
Apr 18, 2021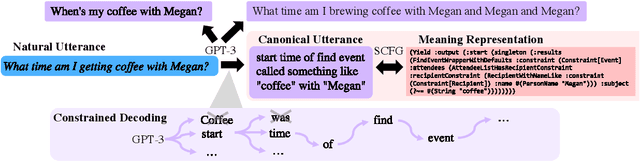

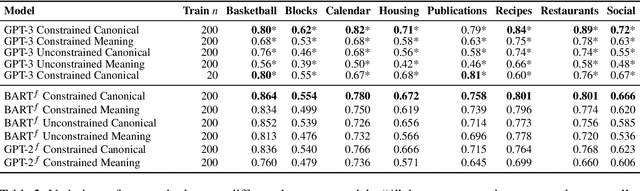
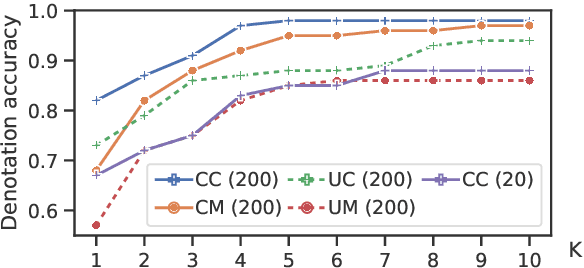
We explore the use of large pretrained language models as few-shot semantic parsers. The goal in semantic parsing is to generate a structured meaning representation given a natural language input. However, language models are trained to generate natural language. To bridge the gap, we use language models to paraphrase inputs into a controlled sublanguage resembling English that can be automatically mapped to a target meaning representation. With a small amount of data and very little code to convert into English-like representations, we provide a blueprint for rapidly bootstrapping semantic parsers and demonstrate good performance on multiple tasks.
Learning How to Ask: Querying LMs with Mixtures of Soft Prompts
Apr 14, 2021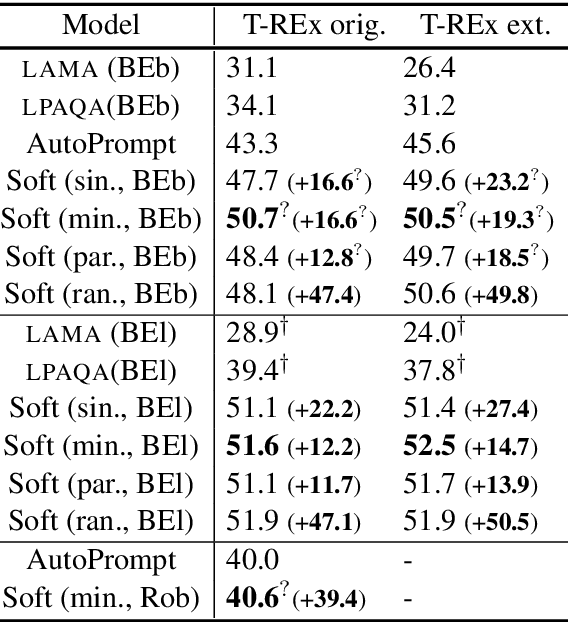


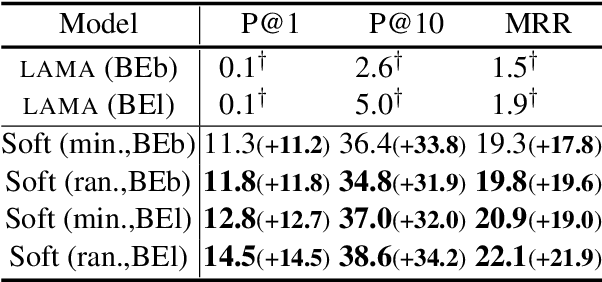
Natural-language prompts have recently been used to coax pretrained language models into performing other AI tasks, using a fill-in-the-blank paradigm (Petroni et al., 2019) or a few-shot extrapolation paradigm (Brown et al., 2020). For example, language models retain factual knowledge from their training corpora that can be extracted by asking them to "fill in the blank" in a sentential prompt. However, where does this prompt come from? We explore the idea of learning prompts by gradient descent -- either fine-tuning prompts taken from previous work, or starting from random initialization. Our prompts consist of "soft words," i.e., continuous vectors that are not necessarily word type embeddings from the language model. Furthermore, for each task, we optimize a mixture of prompts, learning which prompts are most effective and how to ensemble them. Across multiple English LMs and tasks, our approach hugely outperforms previous methods, showing that the implicit factual knowledge in language models was previously underestimated. Moreover, this knowledge is cheap to elicit: random initialization is nearly as good as informed initialization.
Noise-Contrastive Estimation for Multivariate Point Processes
Nov 02, 2020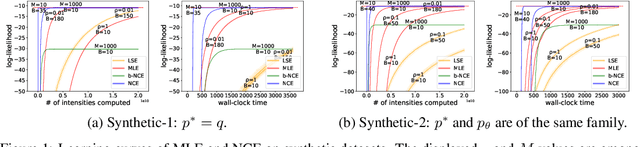
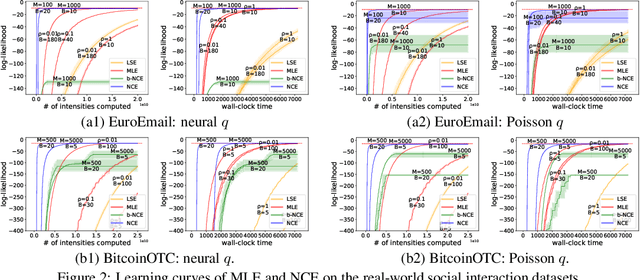
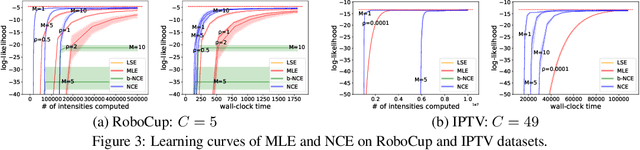
The log-likelihood of a generative model often involves both positive and negative terms. For a temporal multivariate point process, the negative term sums over all the possible event types at each time and also integrates over all the possible times. As a result, maximum likelihood estimation is expensive. We show how to instead apply a version of noise-contrastive estimation---a general parameter estimation method with a less expensive stochastic objective. Our specific instantiation of this general idea works out in an interestingly non-trivial way and has provable guarantees for its optimality, consistency and efficiency. On several synthetic and real-world datasets, our method shows benefits: for the model to achieve the same level of log-likelihood on held-out data, our method needs considerably fewer function evaluations and less wall-clock time.
Autoregressive Modeling is Misspecified for Some Sequence Distributions
Oct 22, 2020
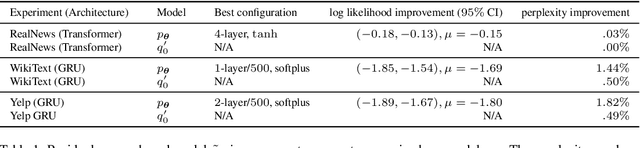
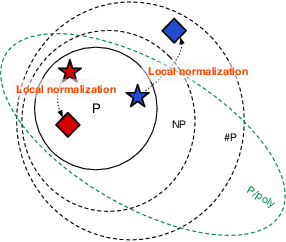
Should sequences be modeled autoregressively---one symbol at a time? How much computation is needed to predict the next symbol? While local normalization is cheap, this also limits its power. We point out that some probability distributions over discrete sequences cannot be well-approximated by any autoregressive model whose runtime and parameter size grow polynomially in the sequence length---even though their unnormalized sequence probabilities are efficient to compute exactly. Intuitively, the probability of the next symbol can be expensive to compute or approximate (even via randomized algorithms) when it marginalizes over exponentially many possible futures, which is in general $\mathrm{NP}$-hard. Our result is conditional on the widely believed hypothesis that $\mathrm{NP} \nsubseteq \mathrm{P/poly}$ (without which the polynomial hierarchy would collapse at the second level). This theoretical observation serves as a caution to the viewpoint that pumping up parameter size is a straightforward way to improve autoregressive models (e.g., in language modeling). It also suggests that globally normalized (energy-based) models may sometimes outperform locally normalized (autoregressive) models, as we demonstrate experimentally for language modeling.
Task-Oriented Dialogue as Dataflow Synthesis
Oct 02, 2020We describe an approach to task-oriented dialogue in which dialogue state is represented as a dataflow graph. A dialogue agent maps each user utterance to a program that extends this graph. Programs include metacomputation operators for reference and revision that reuse dataflow fragments from previous turns. Our graph-based state enables the expression and manipulation of complex user intents, and explicit metacomputation makes these intents easier for learned models to predict. We introduce a new dataset, SMCalFlow, featuring complex dialogues about events, weather, places, and people. Experiments show that dataflow graphs and metacomputation substantially improve representability and predictability in these natural dialogues. Additional experiments on the MultiWOZ dataset show that our dataflow representation enables an otherwise off-the-shelf sequence-to-sequence model to match the best existing task-specific state tracking model. The SMCalFlow dataset and code for replicating experiments are available at https://www.microsoft.com/en-us/research/project/dataflow-based-dialogue-semantic-machines.
Neural Datalog Through Time: Informed Temporal Modeling via Logical Specification
Jun 30, 2020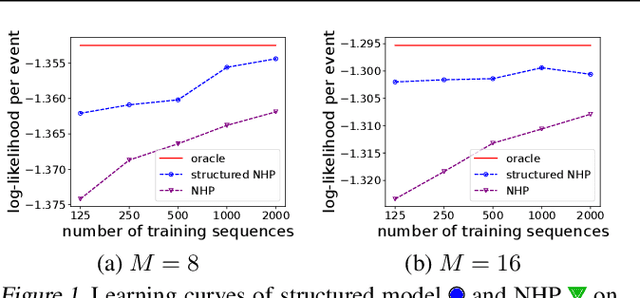
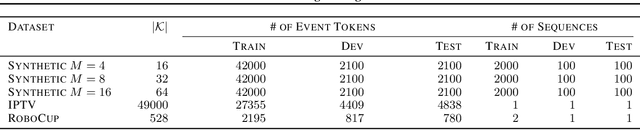
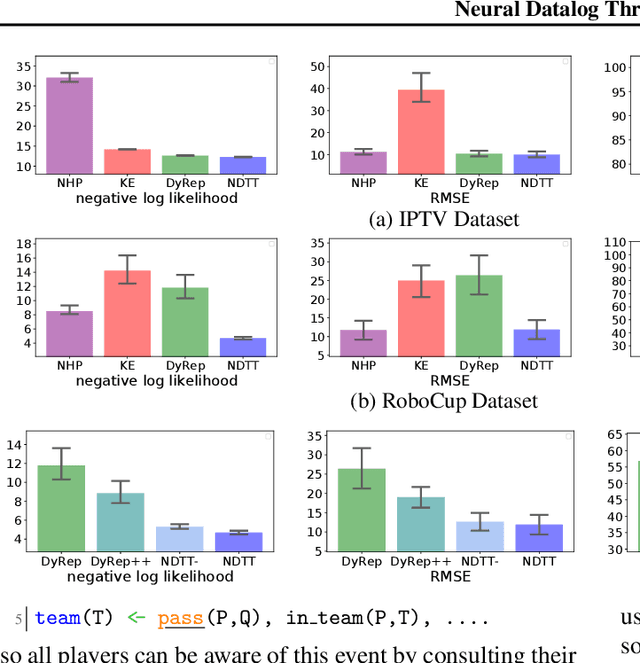
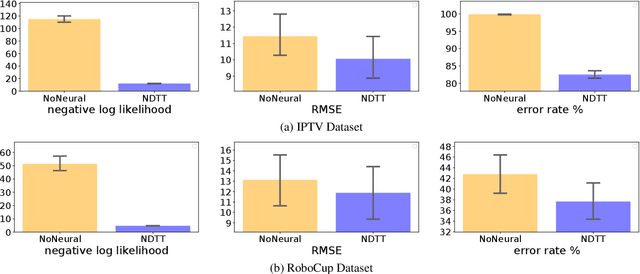
Learning how to predict future events from patterns of past events is difficult when the set of possible event types is large. Training an unrestricted neural model might overfit to spurious patterns. To exploit domain-specific knowledge of how past events might affect an event's present probability, we propose using a temporal deductive database to track structured facts over time. Rules serve to prove facts from other facts and from past events. Each fact has a time-varying state---a vector computed by a neural net whose topology is determined by the fact's provenance, including its experience of past events. The possible event types at any time are given by special facts, whose probabilities are neurally modeled alongside their states. In both synthetic and real-world domains, we show that neural probabilistic models derived from concise Datalog programs improve prediction by encoding appropriate domain knowledge in their architecture.
A Corpus for Large-Scale Phonetic Typology
May 28, 2020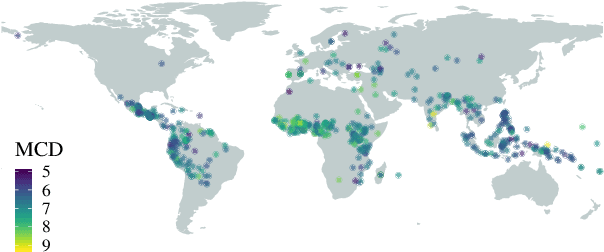
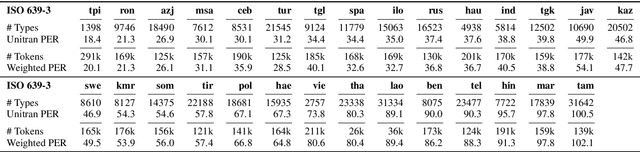
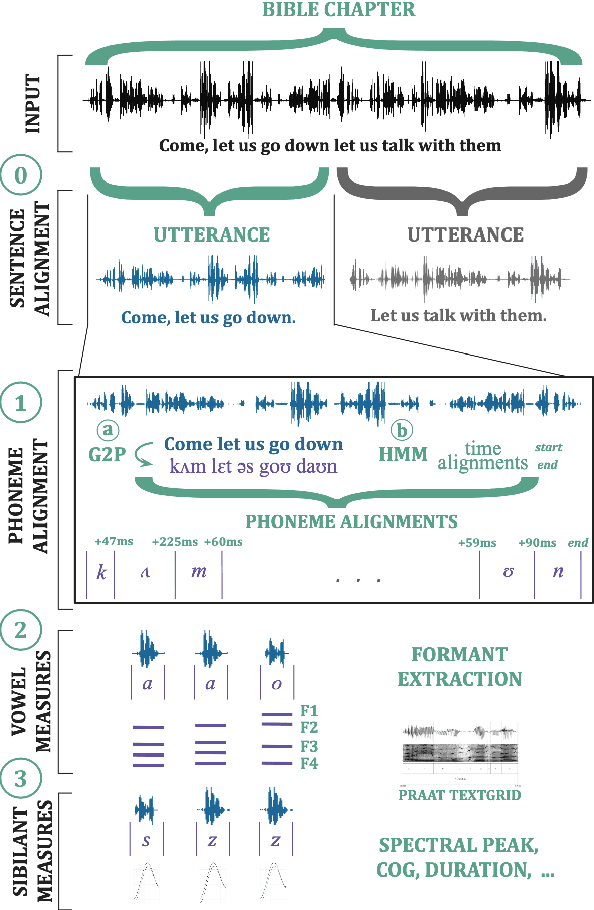
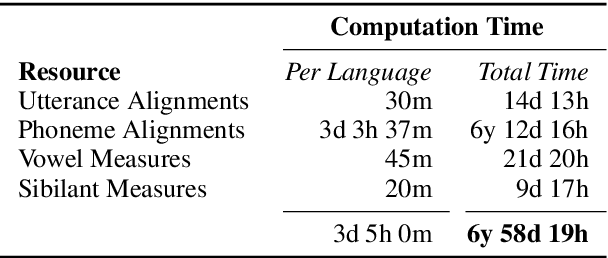
A major hurdle in data-driven research on typology is having sufficient data in many languages to draw meaningful conclusions. We present VoxClamantis v1.0, the first large-scale corpus for phonetic typology, with aligned segments and estimated phoneme-level labels in 690 readings spanning 635 languages, along with acoustic-phonetic measures of vowels and sibilants. Access to such data can greatly facilitate investigation of phonetic typology at a large scale and across many languages. However, it is non-trivial and computationally intensive to obtain such alignments for hundreds of languages, many of which have few to no resources presently available. We describe the methodology to create our corpus, discuss caveats with current methods and their impact on the utility of this data, and illustrate possible research directions through a series of case studies on the 48 highest-quality readings. Our corpus and scripts are publicly available for non-commercial use at https://voxclamantisproject.github.io.
Specializing Word Embeddings (for Parsing) by Information Bottleneck
Oct 01, 2019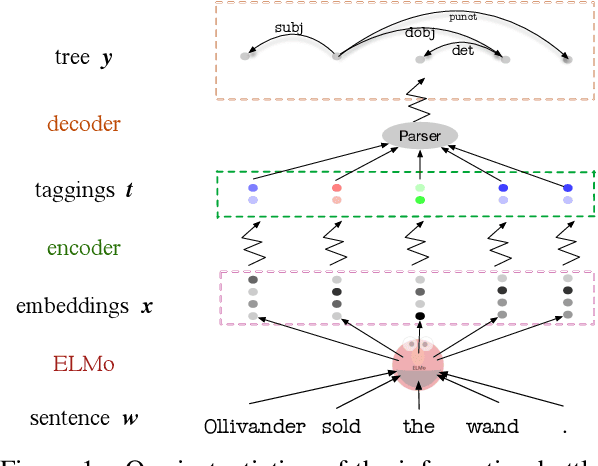
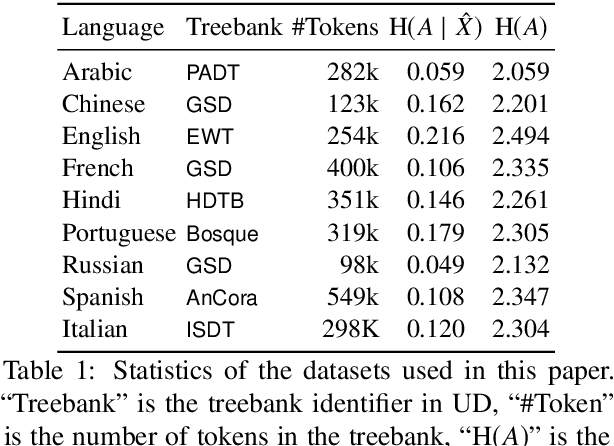
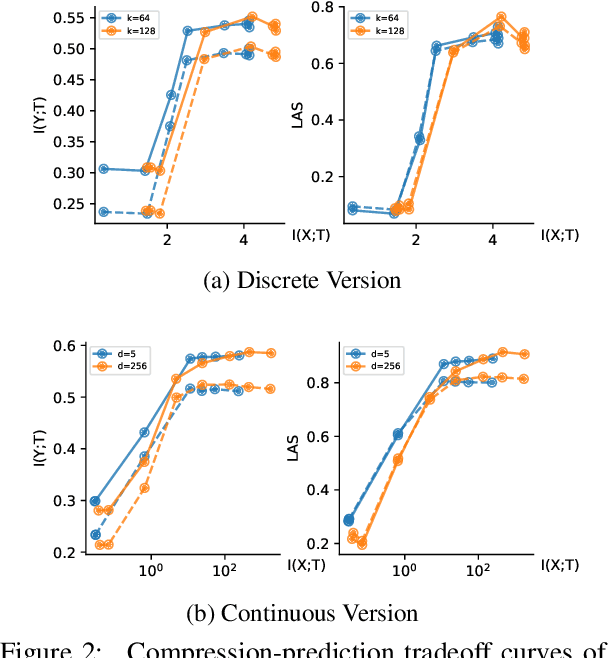
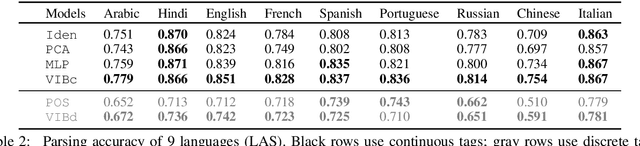
Pre-trained word embeddings like ELMo and BERT contain rich syntactic and semantic information, resulting in state-of-the-art performance on various tasks. We propose a very fast variational information bottleneck (VIB) method to nonlinearly compress these embeddings, keeping only the information that helps a discriminative parser. We compress each word embedding to either a discrete tag or a continuous vector. In the discrete version, our automatically compressed tags form an alternative tag set: we show experimentally that our tags capture most of the information in traditional POS tag annotations, but our tag sequences can be parsed more accurately at the same level of tag granularity. In the continuous version, we show experimentally that moderately compressing the word embeddings by our method yields a more accurate parser in 8 of 9 languages, unlike simple dimensionality reduction.
A Generative Model for Punctuation in Dependency Trees
Jun 26, 2019Treebanks traditionally treat punctuation marks as ordinary words, but linguists have suggested that a tree's "true" punctuation marks are not observed (Nunberg, 1990). These latent "underlying" marks serve to delimit or separate constituents in the syntax tree. When the tree's yield is rendered as a written sentence, a string rewriting mechanism transduces the underlying marks into "surface" marks, which are part of the observed (surface) string but should not be regarded as part of the tree. We formalize this idea in a generative model of punctuation that admits efficient dynamic programming. We train it without observing the underlying marks, by locally maximizing the incomplete data likelihood (similarly to EM). When we use the trained model to reconstruct the tree's underlying punctuation, the results appear plausible across 5 languages, and in particular, are consistent with Nunberg's analysis of English. We show that our generative model can be used to beat baselines on punctuation restoration. Also, our reconstruction of a sentence's underlying punctuation lets us appropriately render the surface punctuation (via our trained underlying-to-surface mechanism) when we syntactically transform the sentence.