 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToy Models of Superposition
Sep 21, 2022Neural networks often pack many unrelated concepts into a single neuron - a puzzling phenomenon known as 'polysemanticity' which makes interpretability much more challenging. This paper provides a toy model where polysemanticity can be fully understood, arising as a result of models storing additional sparse features in "superposition." We demonstrate the existence of a phase change, a surprising connection to the geometry of uniform polytopes, and evidence of a link to adversarial examples. We also discuss potential implications for mechanistic interpretability.
Language Models (Mostly) Know What They Know
Jul 16, 2022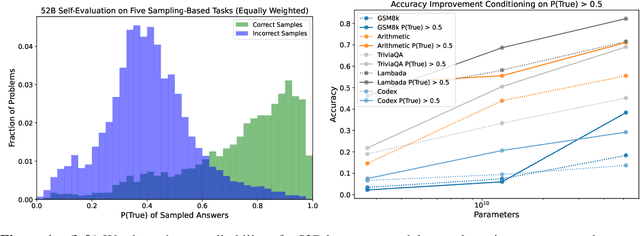
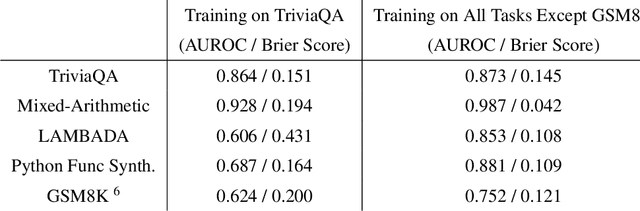
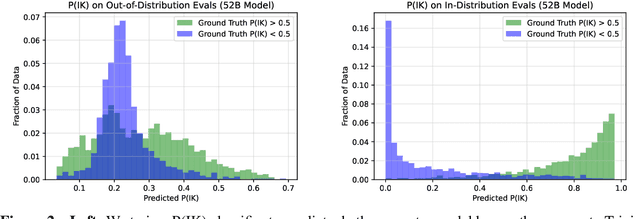
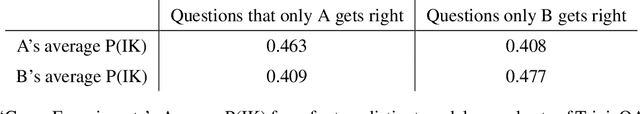
We study whether language models can evaluate the validity of their own claims and predict which questions they will be able to answer correctly. We first show that larger models are well-calibrated on diverse multiple choice and true/false questions when they are provided in the right format. Thus we can approach self-evaluation on open-ended sampling tasks by asking models to first propose answers, and then to evaluate the probability "P(True)" that their answers are correct. We find encouraging performance, calibration, and scaling for P(True) on a diverse array of tasks. Performance at self-evaluation further improves when we allow models to consider many of their own samples before predicting the validity of one specific possibility. Next, we investigate whether models can be trained to predict "P(IK)", the probability that "I know" the answer to a question, without reference to any particular proposed answer. Models perform well at predicting P(IK) and partially generalize across tasks, though they struggle with calibration of P(IK) on new tasks. The predicted P(IK) probabilities also increase appropriately in the presence of relevant source materials in the context, and in the presence of hints towards the solution of mathematical word problems. We hope these observations lay the groundwork for training more honest models, and for investigating how honesty generalizes to cases where models are trained on objectives other than the imitation of human writing.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
Scaling Laws and Interpretability of Learning from Repeated Data
May 21, 2022
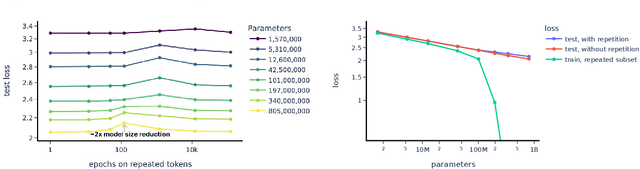
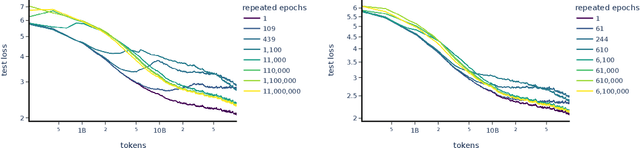
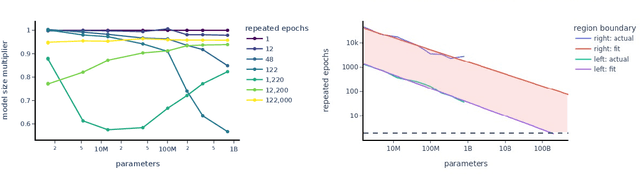
Recent large language models have been trained on vast datasets, but also often on repeated data, either intentionally for the purpose of upweighting higher quality data, or unintentionally because data deduplication is not perfect and the model is exposed to repeated data at the sentence, paragraph, or document level. Some works have reported substantial negative performance effects of this repeated data. In this paper we attempt to study repeated data systematically and to understand its effects mechanistically. To do this, we train a family of models where most of the data is unique but a small fraction of it is repeated many times. We find a strong double descent phenomenon, in which repeated data can lead test loss to increase midway through training. A predictable range of repetition frequency leads to surprisingly severe degradation in performance. For instance, performance of an 800M parameter model can be degraded to that of a 2x smaller model (400M params) by repeating 0.1% of the data 100 times, despite the other 90% of the training tokens remaining unique. We suspect there is a range in the middle where the data can be memorized and doing so consumes a large fraction of the model's capacity, and this may be where the peak of degradation occurs. Finally, we connect these observations to recent mechanistic interpretability work - attempting to reverse engineer the detailed computations performed by the model - by showing that data repetition disproportionately damages copying and internal structures associated with generalization, such as induction heads, providing a possible mechanism for the shift from generalization to memorization. Taken together, these results provide a hypothesis for why repeating a relatively small fraction of data in large language models could lead to disproportionately large harms to performance.
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Apr 12, 2022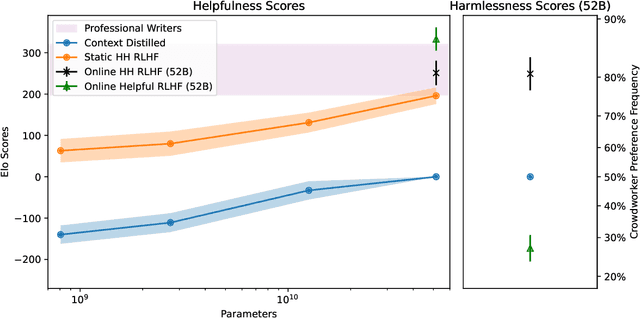
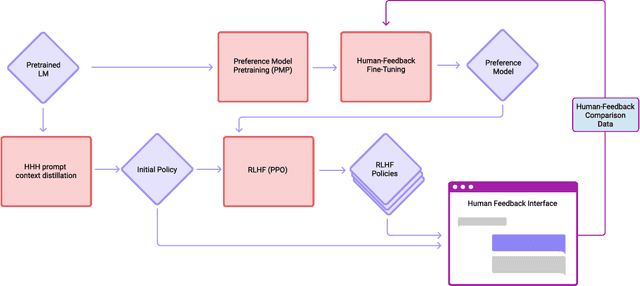
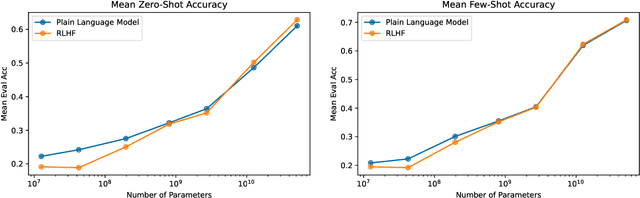
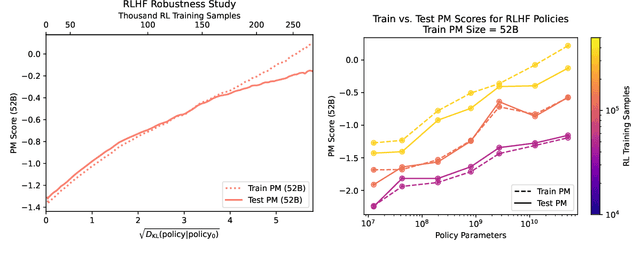
We apply preference modeling and reinforcement learning from human feedback (RLHF) to finetune language models to act as helpful and harmless assistants. We find this alignment training improves performance on almost all NLP evaluations, and is fully compatible with training for specialized skills such as python coding and summarization. We explore an iterated online mode of training, where preference models and RL policies are updated on a weekly cadence with fresh human feedback data, efficiently improving our datasets and models. Finally, we investigate the robustness of RLHF training, and identify a roughly linear relation between the RL reward and the square root of the KL divergence between the policy and its initialization. Alongside our main results, we perform peripheral analyses on calibration, competing objectives, and the use of OOD detection, compare our models with human writers, and provide samples from our models using prompts appearing in recent related work.
A General Language Assistant as a Laboratory for Alignment
Dec 09, 2021
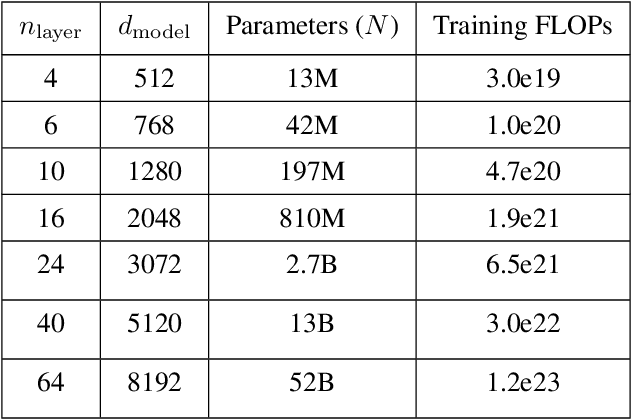
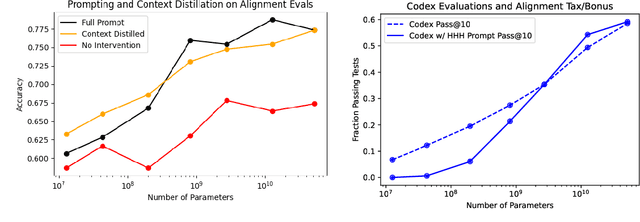
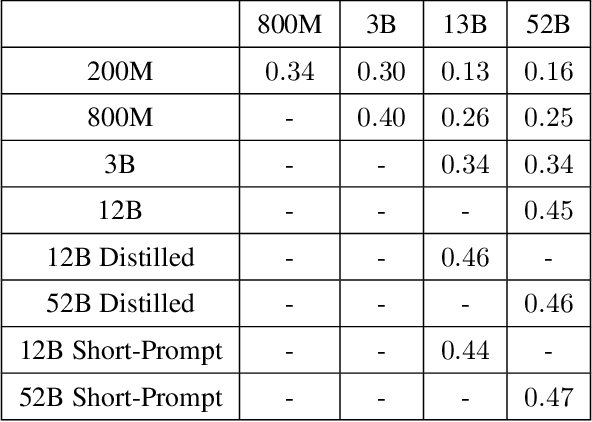
Given the broad capabilities of large language models, it should be possible to work towards a general-purpose, text-based assistant that is aligned with human values, meaning that it is helpful, honest, and harmless. As an initial foray in this direction we study simple baseline techniques and evaluations, such as prompting. We find that the benefits from modest interventions increase with model size, generalize to a variety of alignment evaluations, and do not compromise the performance of large models. Next we investigate scaling trends for several training objectives relevant to alignment, comparing imitation learning, binary discrimination, and ranked preference modeling. We find that ranked preference modeling performs much better than imitation learning, and often scales more favorably with model size. In contrast, binary discrimination typically performs and scales very similarly to imitation learning. Finally we study a `preference model pre-training' stage of training, with the goal of improving sample efficiency when finetuning on human preferences.
Evaluating Large Language Models Trained on Code
Jul 14, 2021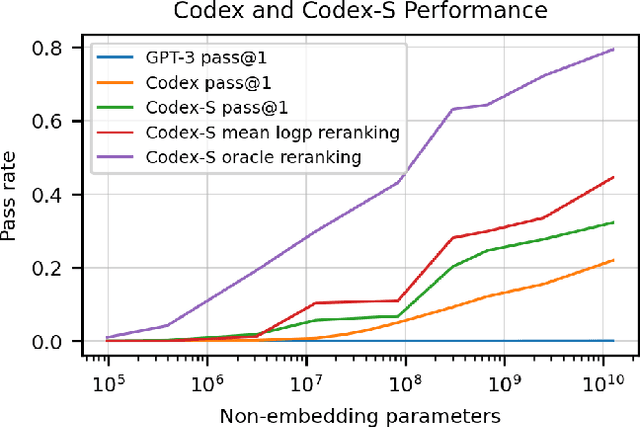
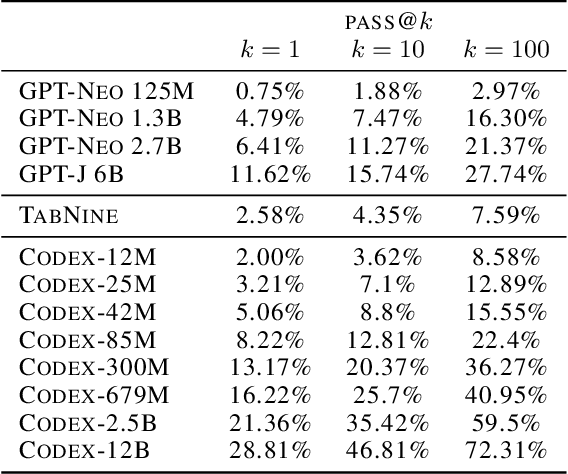
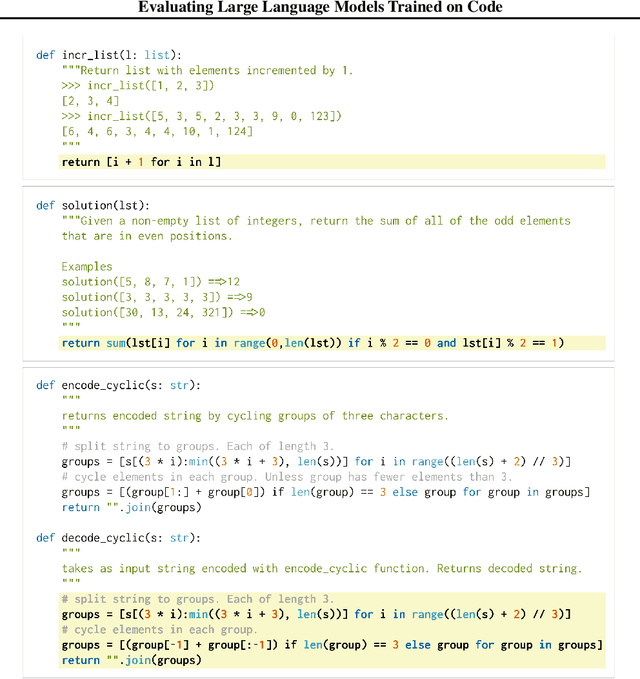
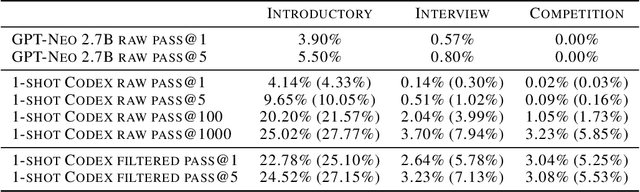
We introduce Codex, a GPT language model fine-tuned on publicly available code from GitHub, and study its Python code-writing capabilities. A distinct production version of Codex powers GitHub Copilot. On HumanEval, a new evaluation set we release to measure functional correctness for synthesizing programs from docstrings, our model solves 28.8% of the problems, while GPT-3 solves 0% and GPT-J solves 11.4%. Furthermore, we find that repeated sampling from the model is a surprisingly effective strategy for producing working solutions to difficult prompts. Using this method, we solve 70.2% of our problems with 100 samples per problem. Careful investigation of our model reveals its limitations, including difficulty with docstrings describing long chains of operations and with binding operations to variables. Finally, we discuss the potential broader impacts of deploying powerful code generation technologies, covering safety, security, and economics.
Explaining Neural Scaling Laws
Feb 12, 2021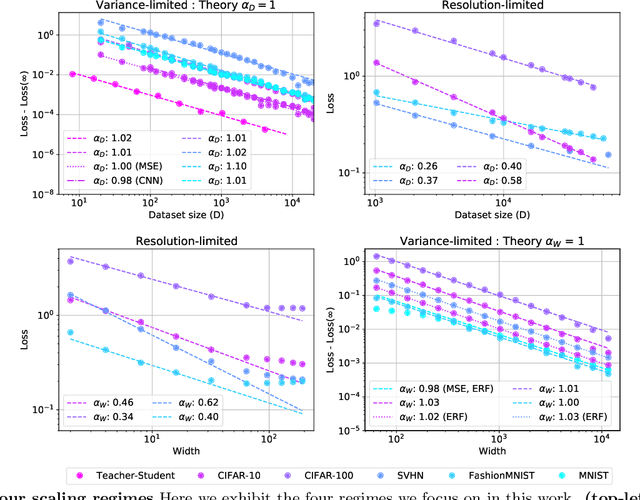
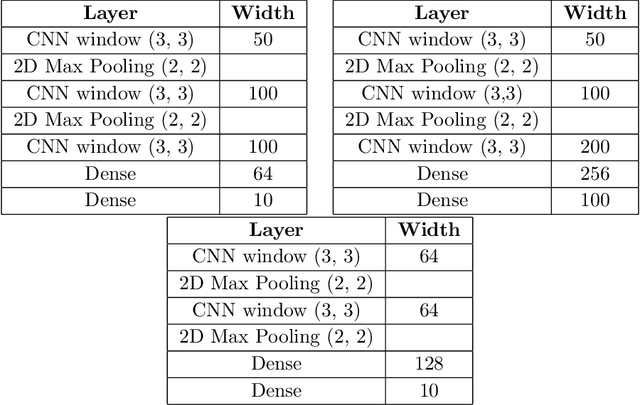
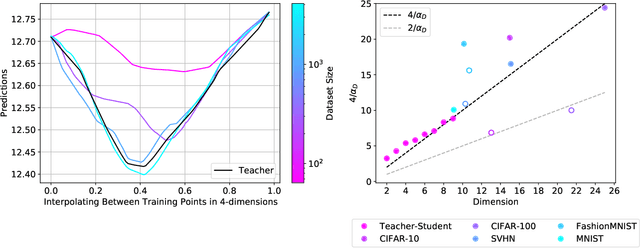
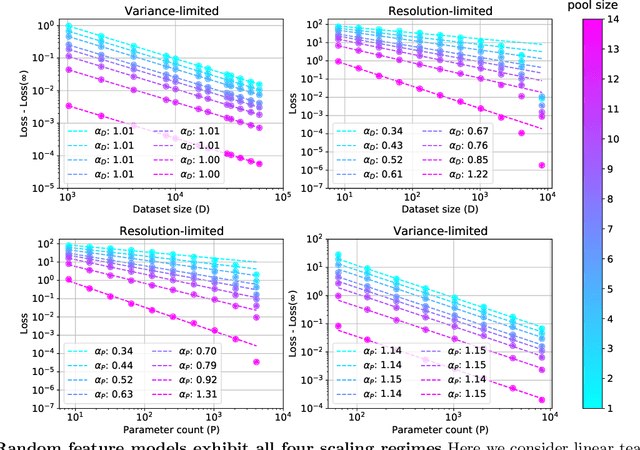
The test loss of well-trained neural networks often follows precise power-law scaling relations with either the size of the training dataset or the number of parameters in the network. We propose a theory that explains and connects these scaling laws. We identify variance-limited and resolution-limited scaling behavior for both dataset and model size, for a total of four scaling regimes. The variance-limited scaling follows simply from the existence of a well-behaved infinite data or infinite width limit, while the resolution-limited regime can be explained by positing that models are effectively resolving a smooth data manifold. In the large width limit, this can be equivalently obtained from the spectrum of certain kernels, and we present evidence that large width and large dataset resolution-limited scaling exponents are related by a duality. We exhibit all four scaling regimes in the controlled setting of large random feature and pretrained models and test the predictions empirically on a range of standard architectures and datasets. We also observe several empirical relationships between datasets and scaling exponents: super-classing image tasks does not change exponents, while changing input distribution (via changing datasets or adding noise) has a strong effect. We further explore the effect of architecture aspect ratio on scaling exponents.
Scaling Laws for Transfer
Feb 02, 2021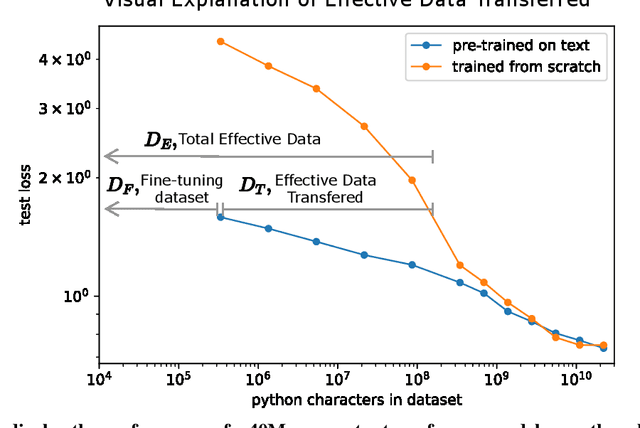

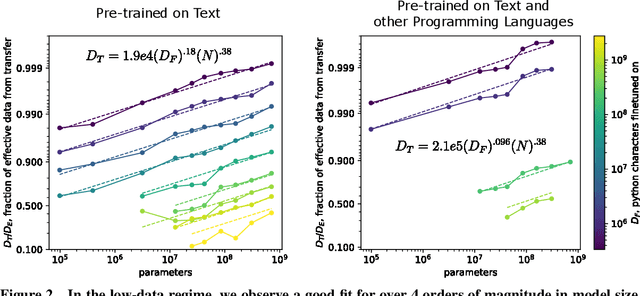
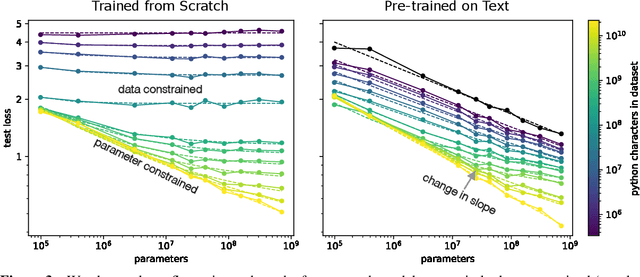
We study empirical scaling laws for transfer learning between distributions in an unsupervised, fine-tuning setting. When we train increasingly large neural networks from-scratch on a fixed-size dataset, they eventually become data-limited and stop improving in performance (cross-entropy loss). When we do the same for models pre-trained on a large language dataset, the slope in performance gains is merely reduced rather than going to zero. We calculate the effective data "transferred" from pre-training by determining how much data a transformer of the same size would have required to achieve the same loss when training from scratch. In other words, we focus on units of data while holding everything else fixed. We find that the effective data transferred is described well in the low data regime by a power-law of parameter count and fine-tuning dataset size. We believe the exponents in these power-laws correspond to measures of the generality of a model and proximity of distributions (in a directed rather than symmetric sense). We find that pre-training effectively multiplies the fine-tuning dataset size. Transfer, like overall performance, scales predictably in terms of parameters, data, and compute.
Scaling Laws for Autoregressive Generative Modeling
Nov 06, 2020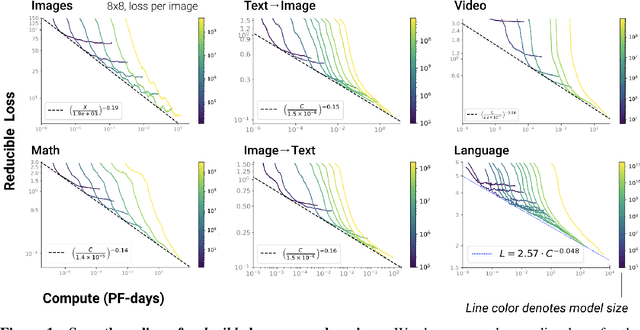
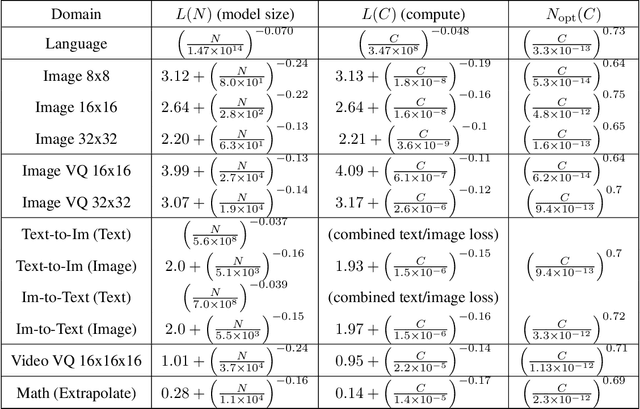
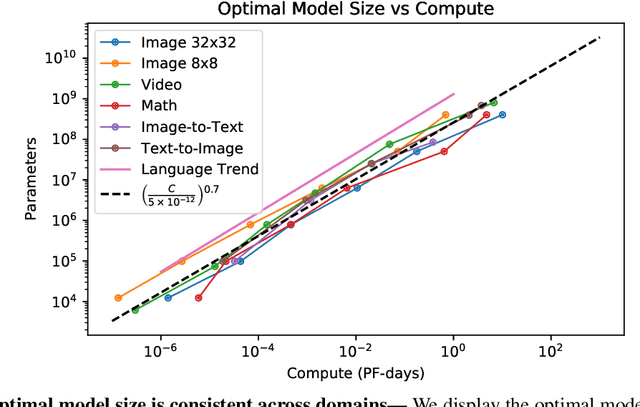

We identify empirical scaling laws for the cross-entropy loss in four domains: generative image modeling, video modeling, multimodal image$\leftrightarrow$text models, and mathematical problem solving. In all cases autoregressive Transformers smoothly improve in performance as model size and compute budgets increase, following a power-law plus constant scaling law. The optimal model size also depends on the compute budget through a power-law, with exponents that are nearly universal across all data domains. The cross-entropy loss has an information theoretic interpretation as $S($True$) + D_{\mathrm{KL}}($True$||$Model$)$, and the empirical scaling laws suggest a prediction for both the true data distribution's entropy and the KL divergence between the true and model distributions. With this interpretation, billion-parameter Transformers are nearly perfect models of the YFCC100M image distribution downsampled to an $8\times 8$ resolution, and we can forecast the model size needed to achieve any given reducible loss (ie $D_{\mathrm{KL}}$) in nats/image for other resolutions. We find a number of additional scaling laws in specific domains: (a) we identify a scaling relation for the mutual information between captions and images in multimodal models, and show how to answer the question "Is a picture worth a thousand words?"; (b) in the case of mathematical problem solving, we identify scaling laws for model performance when extrapolating beyond the training distribution; (c) we finetune generative image models for ImageNet classification and find smooth scaling of the classification loss and error rate, even as the generative loss levels off. Taken together, these results strengthen the case that scaling laws have important implications for neural network performance, including on downstream tasks.