 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerator Surgery for Compressed Sensing
Mar 01, 2021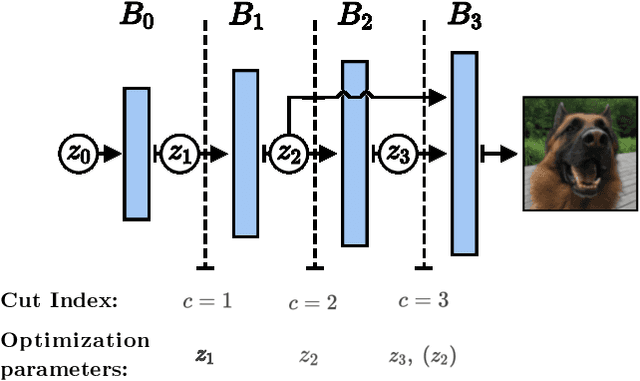
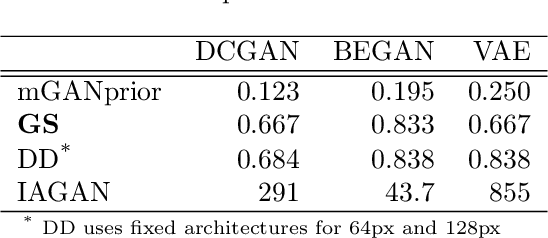
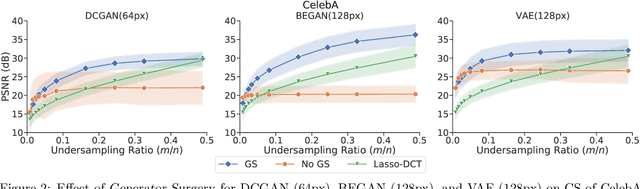
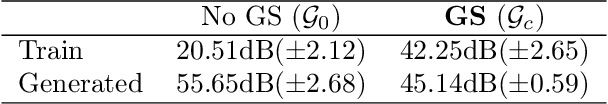
Image recovery from compressive measurements requires a signal prior for the images being reconstructed. Recent work has explored the use of deep generative models with low latent dimension as signal priors for such problems. However, their recovery performance is limited by high representation error. We introduce a method for achieving low representation error using generators as signal priors. Using a pre-trained generator, we remove one or more initial blocks at test time and optimize over the new, higher-dimensional latent space to recover a target image. Experiments demonstrate significantly improved reconstruction quality for a variety of network architectures. This approach also works well for out-of-training-distribution images and is competitive with other state-of-the-art methods. Our experiments show that test-time architectural modifications can greatly improve the recovery quality of generator signal priors for compressed sensing.
Action Priors for Large Action Spaces in Robotics
Jan 11, 2021
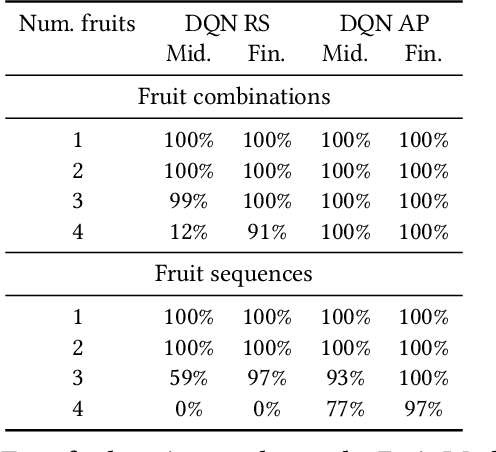

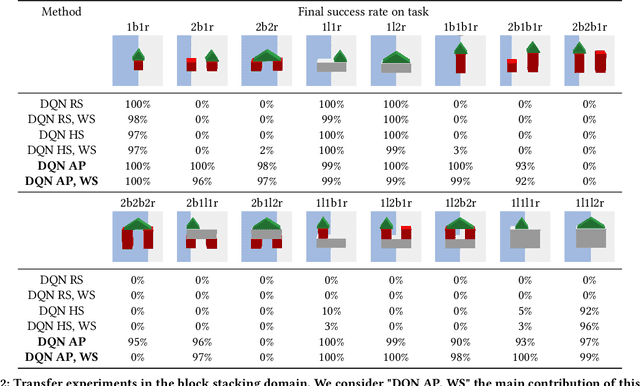
In robotics, it is often not possible to learn useful policies using pure model-free reinforcement learning without significant reward shaping or curriculum learning. As a consequence, many researchers rely on expert demonstrations to guide learning. However, acquiring expert demonstrations can be expensive. This paper proposes an alternative approach where the solutions of previously solved tasks are used to produce an action prior that can facilitate exploration in future tasks. The action prior is a probability distribution over actions that summarizes the set of policies found solving previous tasks. Our results indicate that this approach can be used to solve robotic manipulation problems that would otherwise be infeasible without expert demonstrations.
Improving Few-Shot Visual Classification with Unlabelled Examples
Jun 17, 2020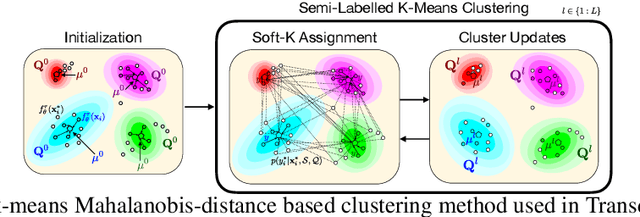
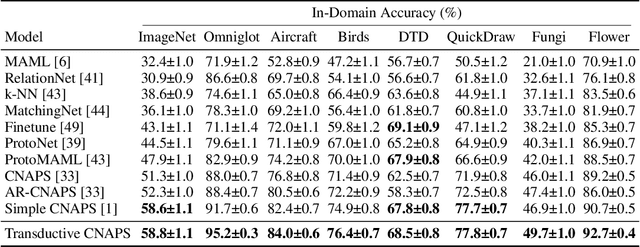
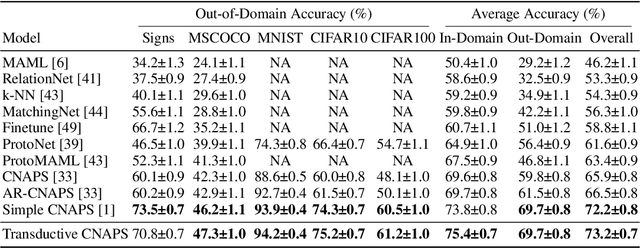
We propose a transductive meta-learning method that uses unlabelled instances to improve few-shot image classification performance. Our approach combines a regularized Mahalanobis-distance-based soft k-means clustering procedure with a state of the art neural adaptive feature extractor to achieve improved test-time classification accuracy using unlabelled data. We evaluate our method on transductive few-shot learning tasks, in which the goal is to jointly predict labels for query (test) examples given a set of support (training) examples. We achieve new state of the art in-domain performance on Meta-Dataset, and improve accuracy on mini- and tiered-ImageNet as compared to other conditional neural adaptive methods that use the same pre-trained feature extractor.
Query-Focused EHR Summarization to Aid Imaging Diagnosis
Apr 26, 2020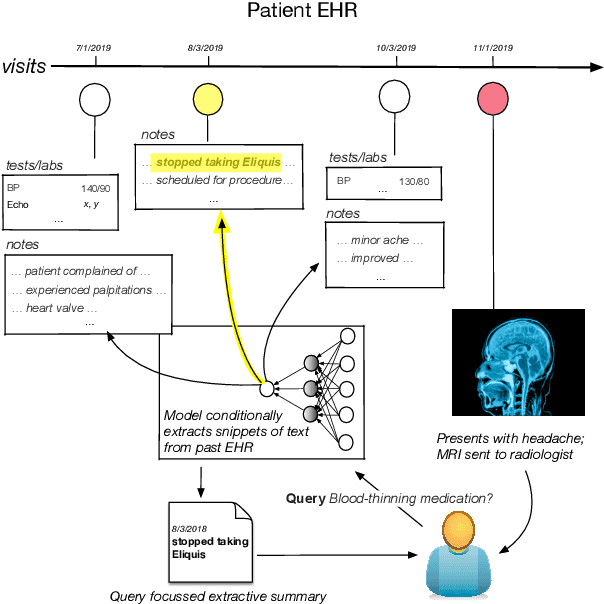
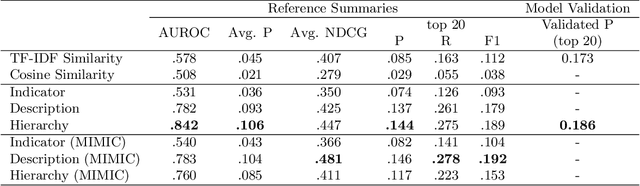
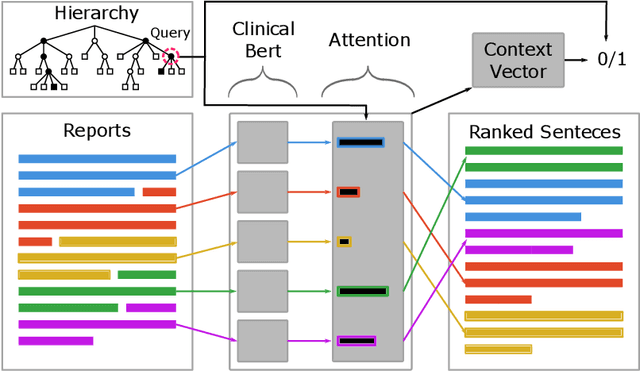
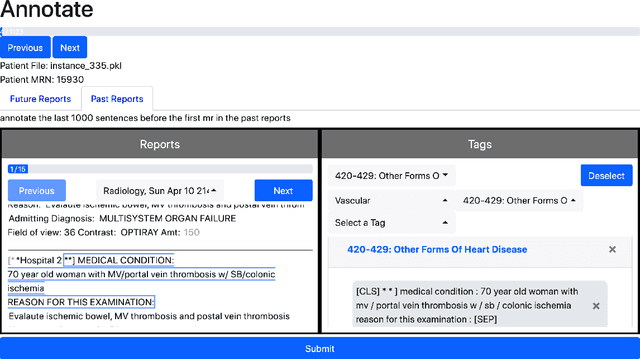
Electronic Health Records (EHRs) provide vital contextual information to radiologists and other physicians when making a diagnosis. Unfortunately, because a given patient's record may contain hundreds of notes and reports, identifying relevant information within these in the short time typically allotted to a case is very difficult. We propose and evaluate models that extract relevant text snippets from patient records to provide a rough case summary intended to aid physicians considering one or more diagnoses. This is hard because direct supervision (i.e., physician annotations of snippets relevant to specific diagnoses in medical records) is prohibitively expensive to collect at scale. We propose a distantly supervised strategy in which we use groups of International Classification of Diseases (ICD) codes observed in 'future' records as noisy proxies for 'downstream' diagnoses. Using this we train a transformer-based neural model to perform extractive summarization conditioned on potential diagnoses. This model defines an attention mechanism that is conditioned on potential diagnoses (queries) provided by the diagnosing physician. We train (via distant supervision) and evaluate variants of this model on EHR data from Brigham and Women's Hospital in Boston and MIMIC-III (the latter to facilitate reproducibility). Evaluations performed by radiologists demonstrate that these distantly supervised models yield better extractive summaries than do unsupervised approaches. Such models may aid diagnosis by identifying sentences in past patient reports that are clinically relevant to a potential diagnosis.
Deep Markov Spatio-Temporal Factorization
Mar 22, 2020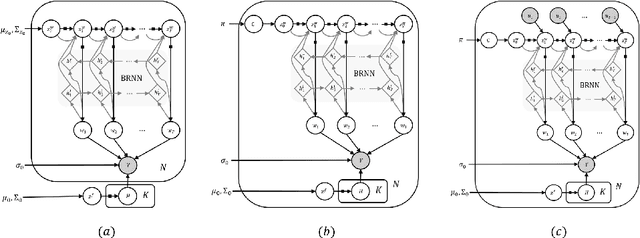

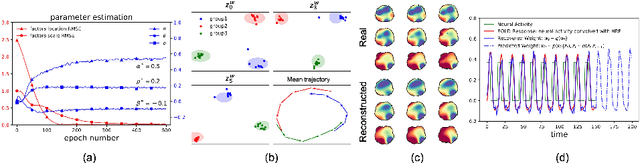

We introduce deep Markov spatio-temporal factorization (DMSTF), a deep generative model for spatio-temporal data. Like other factor analysis methods, DMSTF approximates high-dimensional data by a product between time-dependent weights and spatially dependent factors. These weights and factors are in turn represented in terms of lower-dimensional latent variables that we infer using stochastic variational inference. The innovation in DMSTF is that we parameterize weights in terms of a deep Markovian prior, which is able to characterize nonlinear temporal dynamics. We parameterize the corresponding variational distribution using a bidirectional recurrent network. This results in a flexible family of hierarchical deep generative factor analysis models that can be extended to perform time series clustering, or perform factor analysis in the presence of a control signal. Our experiments, which consider simulated data, fMRI data, and traffic data, demonstrate that DMSTF outperforms related methods in terms of reconstruction accuracy and can perform forecasting in a variety domains with nonlinear temporal transitions.
Learning discrete state abstractions with deep variational inference
Mar 09, 2020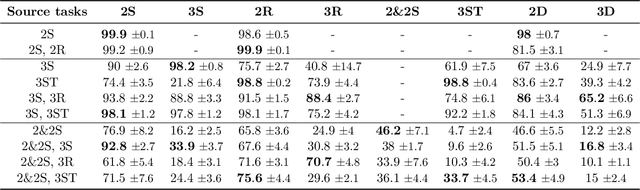
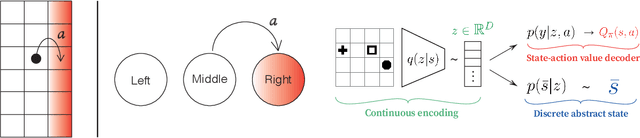
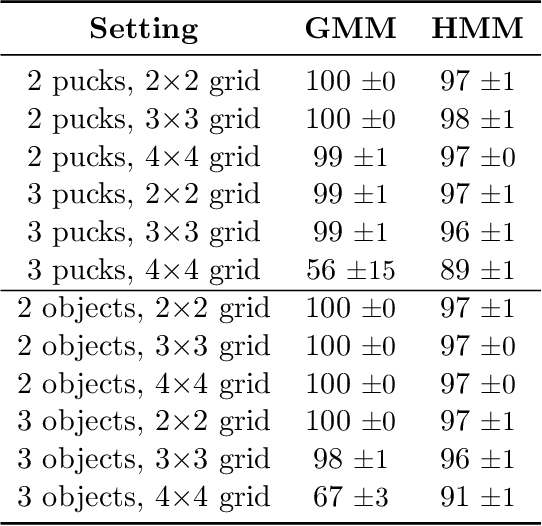
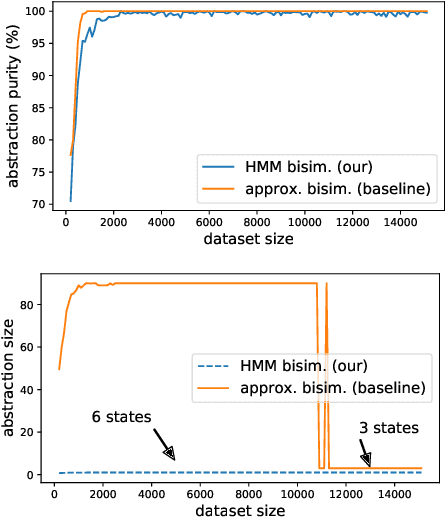
Abstraction is crucial for effective sequential decision making in domains with large state spaces. In this work, we propose a variational information bottleneck method for learning approximate bisimulations, a type of state abstraction. We use a deep neural net encoder to map states onto continuous embeddings. The continuous latent space is then compressed into a discrete representation using an action-conditioned hidden Markov model, which is trained end-to-end with the neural network. Our method is suited for environments with high-dimensional states and learns from a stream of experience collected by an agent acting in a Markov decision process. Through a learned discrete abstract model, we can efficiently plan for unseen goals in a multi-goal Reinforcement Learning setting. We test our method in simplified robotic manipulation domains with image states. We also compare it against previous model-based approaches to finding bisimulations in discrete grid-world-like environments.
Evaluating Combinatorial Generalization in Variational Autoencoders
Nov 11, 2019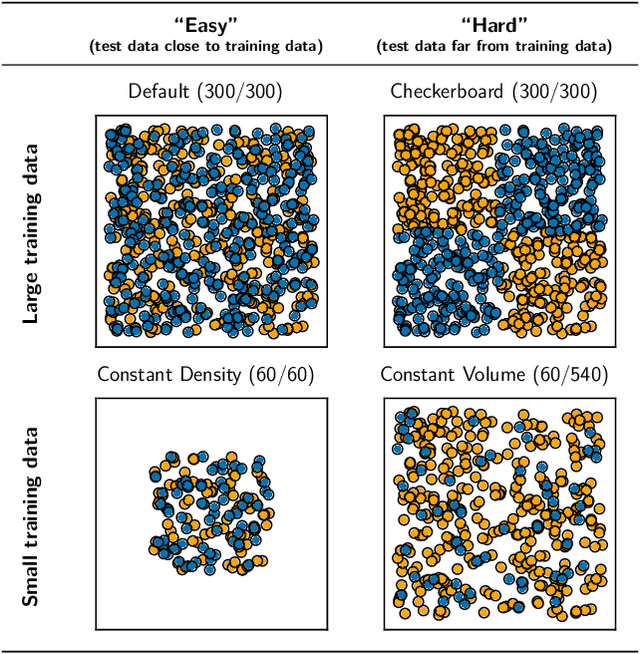
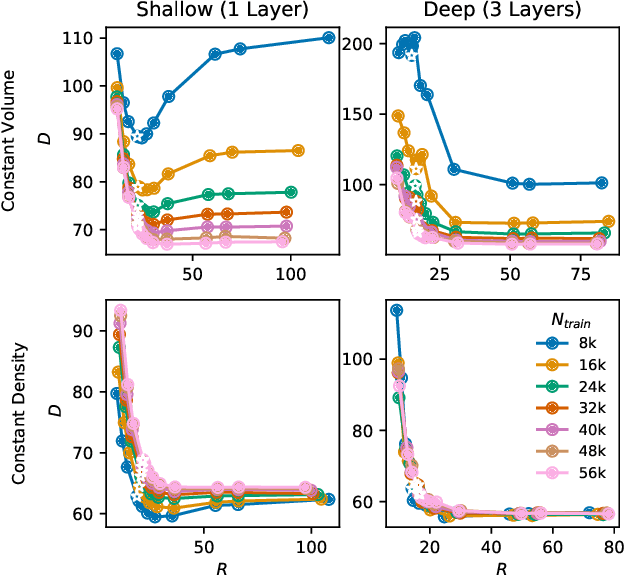
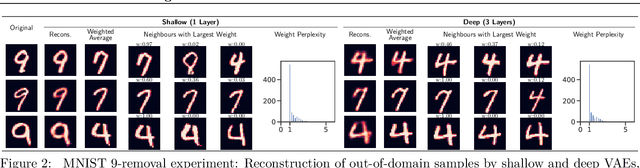

We evaluate the ability of variational autoencoders to generalize to unseen examples in domains with a large combinatorial space of feature values. Our experiments systematically evaluate the effect of network width, depth, regularization, and the typical distance between the training and test examples. Increasing network capacity benefits generalization in easy problems, where test-set examples are similar to training examples. In more difficult problems, increasing capacity deteriorates generalization when optimizing the standard VAE objective, but once again improves generalization when we decrease the KL regularization. Our results establish that interplay between model capacity and KL regularization is not clear cut; we need to take the typical distance between train and test examples into account when evaluating generalization.
Amortized Population Gibbs Samplers with Neural Sufficient Statistics
Nov 04, 2019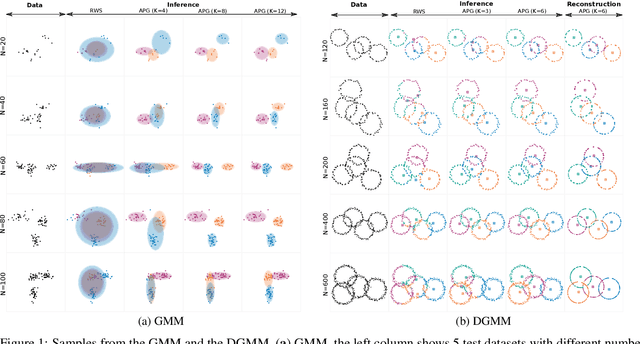
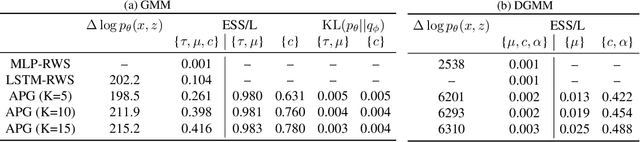
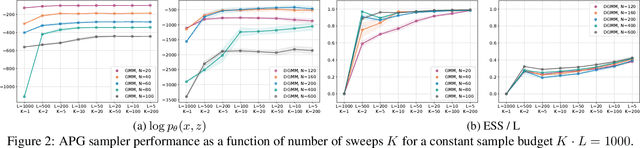

We develop amortized population Gibbs (APG) samplers, a new class of autoencoding variational methods for deep probabilistic models. APG samplers construct high-dimensional proposals by iterating over updates to lower-dimensional blocks of variables. Each conditional update is a neural proposal, which we train by minimizing the inclusive KL divergence relative to the conditional posterior. To appropriately account for the size of the input data, we develop a new parameterization in terms of neural sufficient statistics, resulting in quasi-conjugate variational approximations. Experiments demonstrate that learned proposals converge to the known analytical conditional posterior in conjugate models, and that APG samplers can learn inference networks for highly-structured deep generative models when the conditional posteriors are intractable. Here APG samplers offer a path toward scaling up stochastic variational methods to models in which standard autoencoding architectures fail to produce accurate samples.
Neural Topographic Factor Analysis for fMRI Data
Jun 21, 2019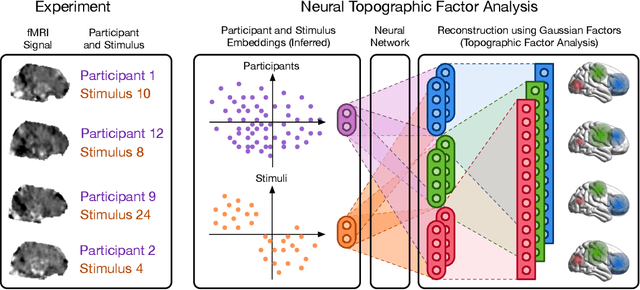

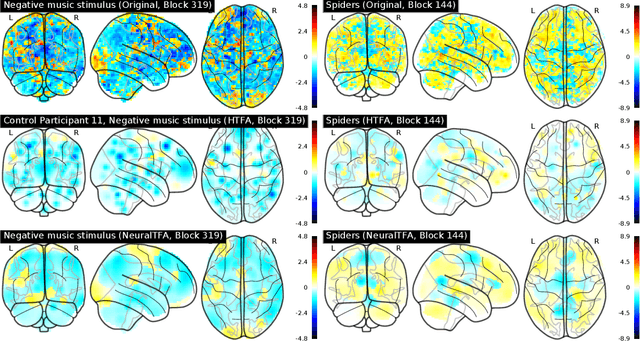
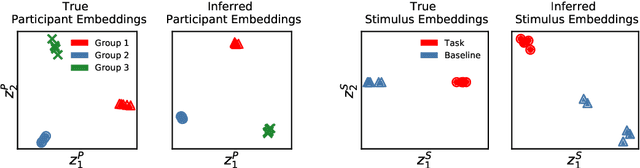
Neuroimaging experiments produce a large volume (gigabytes) of high-dimensional spatio-temporal data for a small number of sampled participants and stimuli. Analyses of this data commonly compute averages over all trials, ignoring variation within groups of participants and stimuli. To enable the analysis of fMRI data without this implicit assumption of uniformity, we propose Neural Topographic Factor Analysis (NTFA), a deep generative model that parameterizes factors as functions of embeddings for participants and stimuli. We evaluate NTFA on a synthetically generated dataset as well as on three datasets from fMRI experiments. Our results demonstrate that NTFA yields more accurate reconstructions than a state-of-the-art method with fewer parameters. Moreover, learned embeddings uncover latent categories of participants and stimuli, which suggests that NTFA takes a first step towards reasoning about individual variation in fMRI experiments.
Structured Neural Topic Models for Reviews
Jan 02, 2019
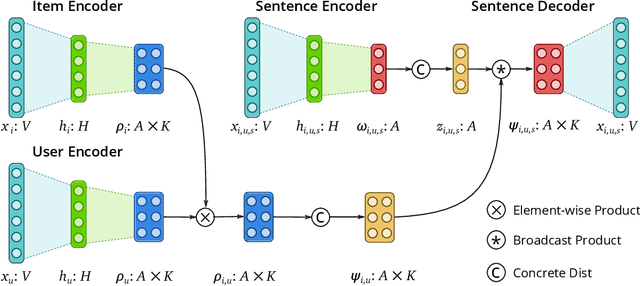

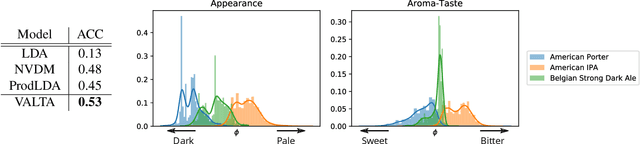
We present Variational Aspect-based Latent Topic Allocation (VALTA), a family of autoencoding topic models that learn aspect-based representations of reviews. VALTA defines a user-item encoder that maps bag-of-words vectors for combined reviews associated with each paired user and item onto structured embeddings, which in turn define per-aspect topic weights. We model individual reviews in a structured manner by inferring an aspect assignment for each sentence in a given review, where the per-aspect topic weights obtained by the user-item encoder serve to define a mixture over topics, conditioned on the aspect. The result is an autoencoding neural topic model for reviews, which can be trained in a fully unsupervised manner to learn topics that are structured into aspects. Experimental evaluation on large number of datasets demonstrates that aspects are interpretable, yield higher coherence scores than non-structured autoencoding topic model variants, and can be utilized to perform aspect-based comparison and genre discovery.