 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFactors affecting the in-context learning abilities of LLMs for dialogue state tracking
Jun 10, 2025This study explores the application of in-context learning (ICL) to the dialogue state tracking (DST) problem and investigates the factors that influence its effectiveness. We use a sentence embedding based k-nearest neighbour method to retrieve the suitable demonstrations for ICL. The selected demonstrations, along with the test samples, are structured within a template as input to the LLM. We then conduct a systematic study to analyse the impact of factors related to demonstration selection and prompt context on DST performance. This work is conducted using the MultiWoZ2.4 dataset and focuses primarily on the OLMo-7B-instruct, Mistral-7B-Instruct-v0.3, and Llama3.2-3B-Instruct models. Our findings provide several useful insights on in-context learning abilities of LLMs for dialogue state tracking.
Approaching Dialogue State Tracking via Aligning Speech Encoders and LLMs
Jun 10, 2025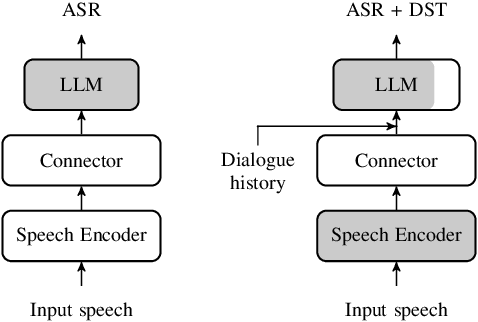
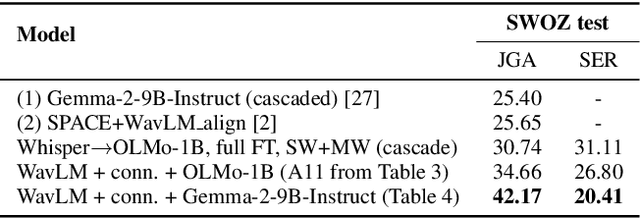
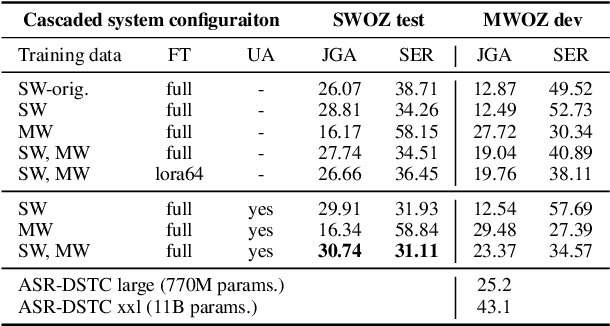
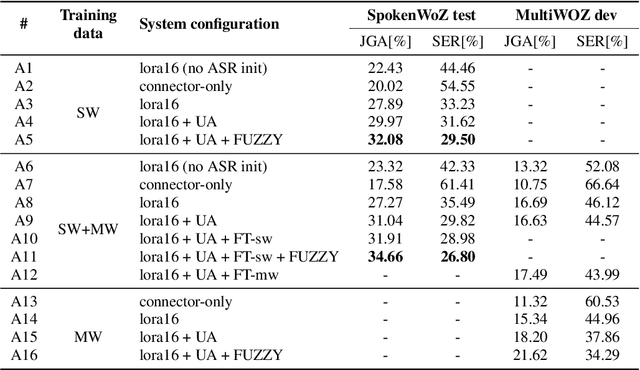
In this work, we approach spoken Dialogue State Tracking (DST) by bridging the representation spaces of speech encoders and LLMs via a small connector module, with a focus on fully open-sourced and open-data components (WavLM-large, OLMo). We focus on ablating different aspects of such systems including full/LoRA adapter fine-tuning, the effect of agent turns in the dialogue history, as well as fuzzy matching-based output post-processing, which greatly improves performance of our systems on named entities in the dialogue slot values. We conduct our experiments on the SpokenWOZ dataset, and additionally utilize the Speech-Aware MultiWOZ dataset to augment our training data. Ultimately, our best-performing WavLM + connector + OLMo-1B aligned models achieve state of the art on the SpokenWOZ test set (34.66% JGA), and our system with Gemma-2-9B-instruct further surpasses this result, reaching 42.17% JGA on SpokenWOZ test.
The Second DISPLACE Challenge : DIarization of SPeaker and LAnguage in Conversational Environments
Jun 13, 2024



The DIarization of SPeaker and LAnguage in Conversational Environments (DISPLACE) 2024 challenge is the second in the series of DISPLACE challenges, which involves tasks of speaker diarization (SD) and language diarization (LD) on a challenging multilingual conversational speech dataset. In the DISPLACE 2024 challenge, we also introduced the task of automatic speech recognition (ASR) on this dataset. The dataset containing 158 hours of speech, consisting of both supervised and unsupervised mono-channel far-field recordings, was released for LD and SD tracks. Further, 12 hours of close-field mono-channel recordings were provided for the ASR track conducted on 5 Indian languages. The details of the dataset, baseline systems and the leader board results are highlighted in this paper. We have also compared our baseline models and the team's performances on evaluation data of DISPLACE-2023 to emphasize the advancements made in this second version of the challenge.