 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesigning Multimodal Datasets for NLP Challenges
May 12, 2021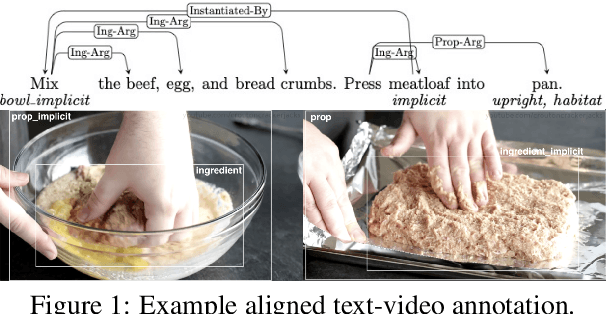


In this paper, we argue that the design and development of multimodal datasets for natural language processing (NLP) challenges should be enhanced in two significant respects: to more broadly represent commonsense semantic inferences; and to better reflect the dynamics of actions and events, through a substantive alignment of textual and visual information. We identify challenges and tasks that are reflective of linguistic and cognitive competencies that humans have when speaking and reasoning, rather than merely the performance of systems on isolated tasks. We introduce the distinction between challenge-based tasks and competence-based performance, and describe a diagnostic dataset, Recipe-to-Video Questions (R2VQ), designed for testing competence-based comprehension over a multimodal recipe collection (http://r2vq.org/). The corpus contains detailed annotation supporting such inferencing tasks and facilitating a rich set of question families that we use to evaluate NLP systems.
Neurosymbolic AI for Situated Language Understanding
Dec 05, 2020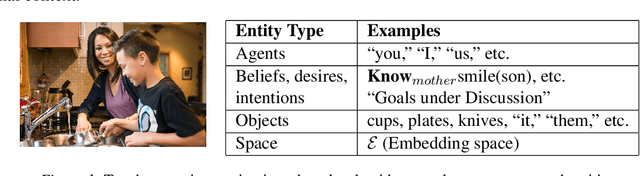

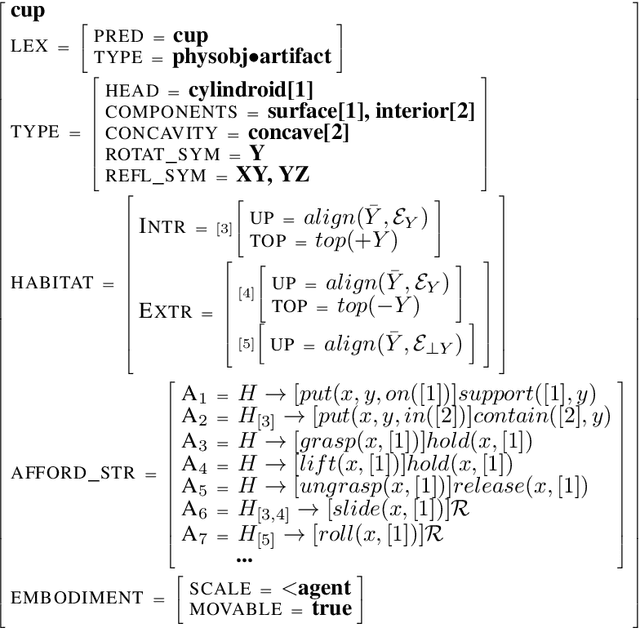
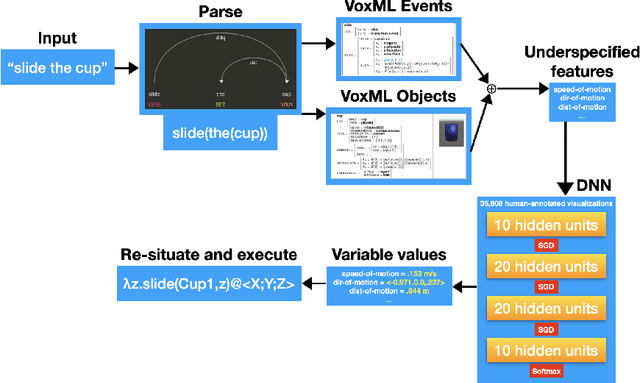
In recent years, data-intensive AI, particularly the domain of natural language processing and understanding, has seen significant progress driven by the advent of large datasets and deep neural networks that have sidelined more classic AI approaches to the field. These systems can apparently demonstrate sophisticated linguistic understanding or generation capabilities, but often fail to transfer their skills to situations they have not encountered before. We argue that computational situated grounding provides a solution to some of these learning challenges by creating situational representations that both serve as a formal model of the salient phenomena, and contain rich amounts of exploitable, task-appropriate data for training new, flexible computational models. Our model reincorporates some ideas of classic AI into a framework of neurosymbolic intelligence, using multimodal contextual modeling of interactive situations, events, and object properties. We discuss how situated grounding provides diverse data and multiple levels of modeling for a variety of AI learning challenges, including learning how to interact with object affordances, learning semantics for novel structures and configurations, and transferring such learned knowledge to new objects and situations.
Situated Multimodal Control of a Mobile Robot: Navigation through a Virtual Environment
Jul 13, 2020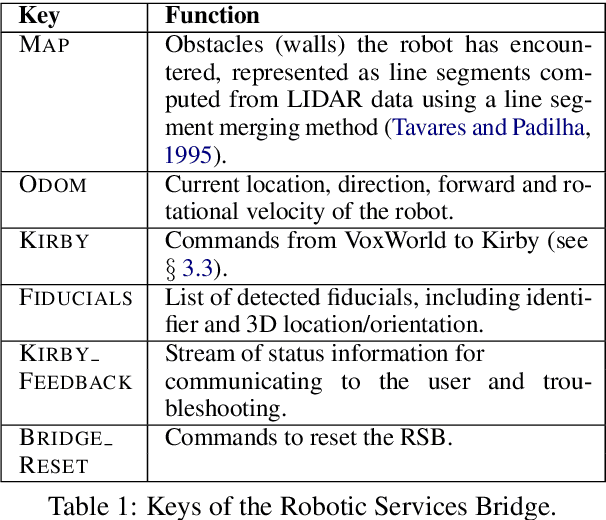

We present a new interface for controlling a navigation robot in novel environments using coordinated gesture and language. We use a TurtleBot3 robot with a LIDAR and a camera, an embodied simulation of what the robot has encountered while exploring, and a cross-platform bridge facilitating generic communication. A human partner can deliver instructions to the robot using spoken English and gestures relative to the simulated environment, to guide the robot through navigation tasks.
COVID-19 Literature Knowledge Graph Construction and Drug Repurposing Report Generation
Jul 06, 2020
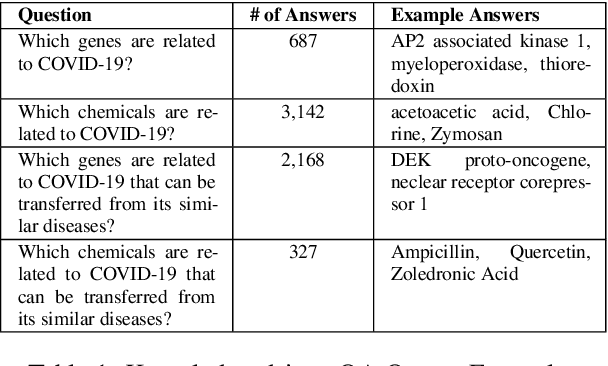
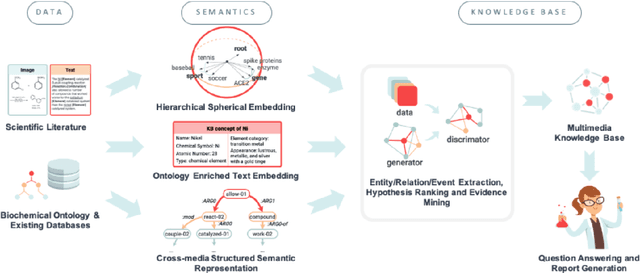
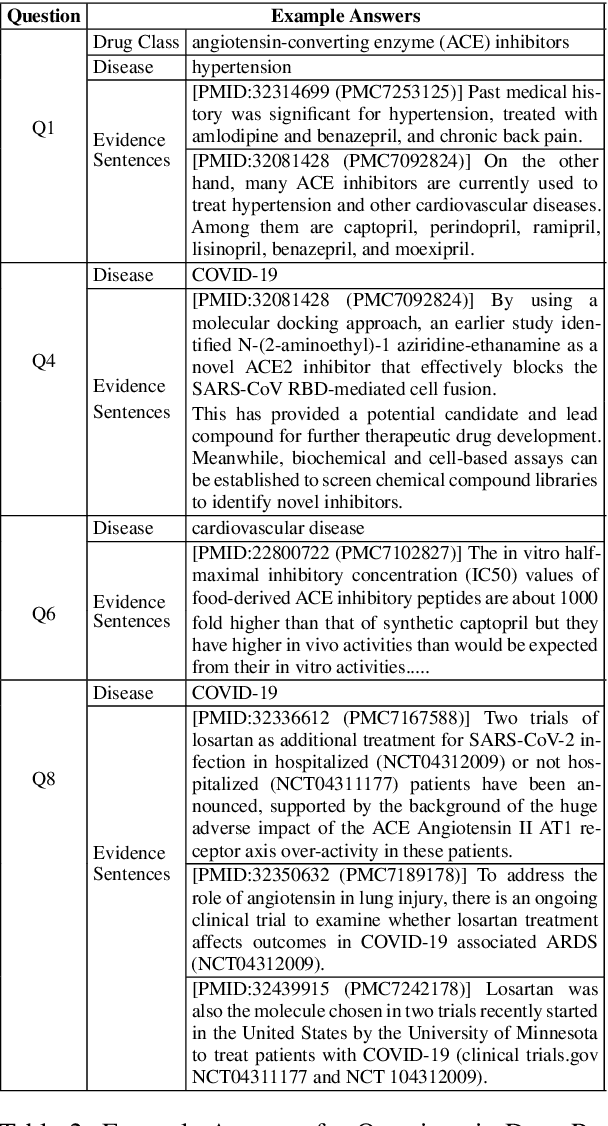
To combat COVID-19, clinicians and scientists all need to digest the vast amount of relevant biomedical knowledge in literature to understand the disease mechanism and the related biological functions. We have developed a novel and comprehensive knowledge discovery framework, COVID-KG, which leverages novel semantic representation and external ontologies to represent text and images in the input literature data, and then performs various extraction components to extract fine-grained multimedia knowledge elements (entities, relations and events). We then exploit the constructed multimedia KGs for question answering and report generation, using drug repurposing as a case study. Our framework also provides detailed contextual sentences, subfigures and knowledge subgraphs as evidence. All of the data, KGs, resources, and shared services are publicly available.
Exploration and Discovery of the COVID-19 Literature through Semantic Visualization
Jul 03, 2020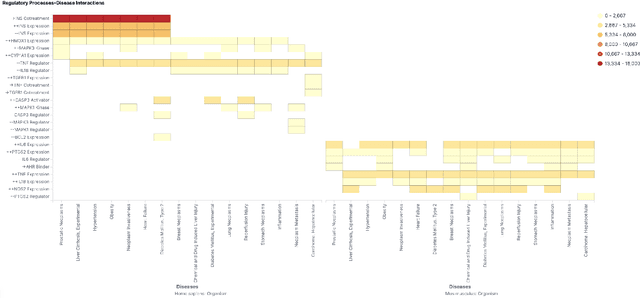

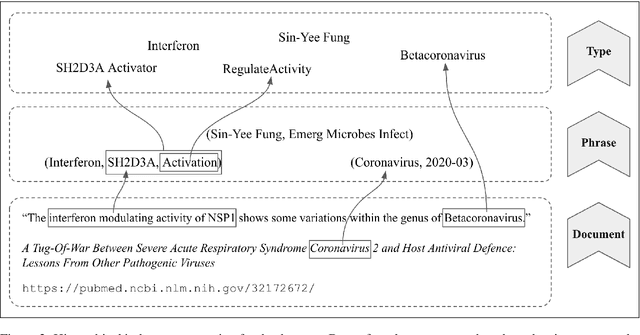
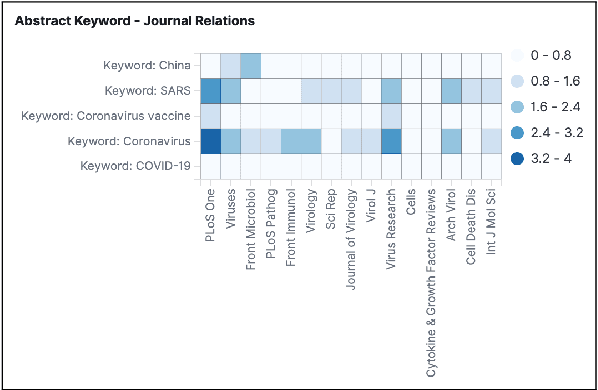
We are developing semantic visualization techniques in order to enhance exploration and enable discovery over large datasets of complex networks of relations. Semantic visualization is a method of enabling exploration and discovery over large datasets of complex networks by exploiting the semantics of the relations in them. This involves (i) NLP to extract named entities, relations and knowledge graphs from the original data; (ii) indexing the output and creating representations for all relevant entities and relations that can be visualized in many different ways, e.g., as tag clouds, heat maps, graphs, etc.; (iii) applying parameter reduction operations to the extracted relations, creating "relation containers", or functional entities that can also be visualized using the same methods, allowing the visualization of multiple relations, partial pathways, and exploration across multiple dimensions. Our hope is that this will enable the discovery of novel inferences over relations in complex data that otherwise would go unnoticed. We have applied this to analysis of the recently released CORD-19 dataset.
A Formal Analysis of Multimodal Referring Strategies Under Common Ground
Mar 16, 2020
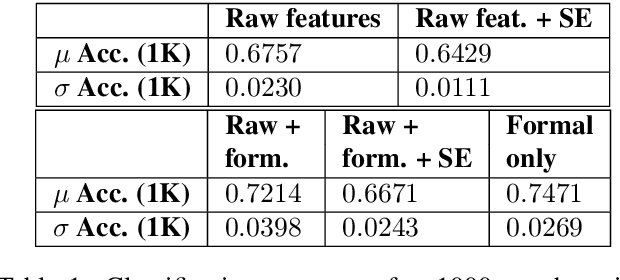
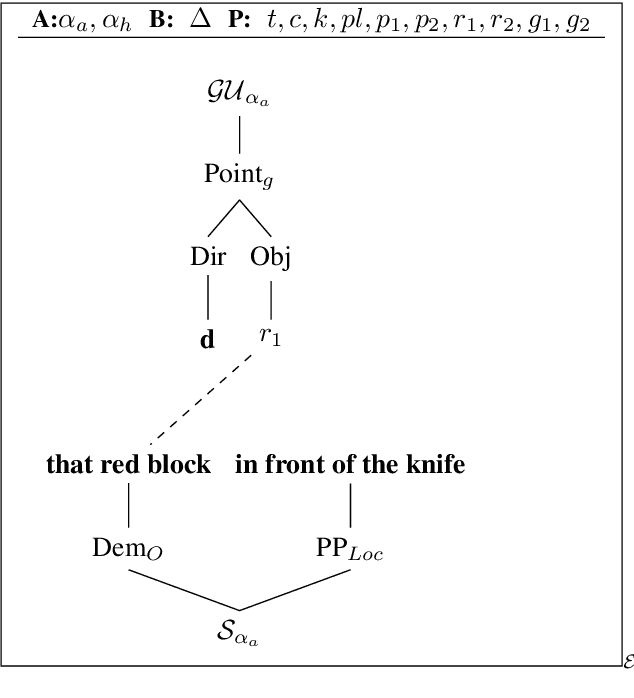
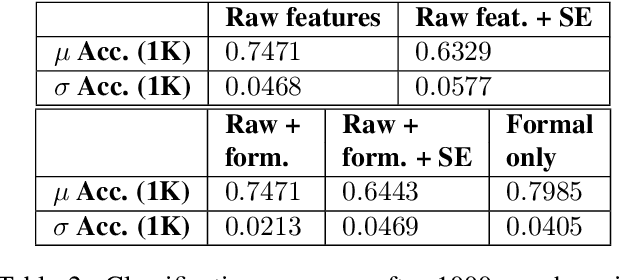
In this paper, we present an analysis of computationally generated mixed-modality definite referring expressions using combinations of gesture and linguistic descriptions. In doing so, we expose some striking formal semantic properties of the interactions between gesture and language, conditioned on the introduction of content into the common ground between the (computational) speaker and (human) viewer, and demonstrate how these formal features can contribute to training better models to predict viewer judgment of referring expressions, and potentially to the generation of more natural and informative referring expressions.
Assessing the Efficacy of Clinical Sentiment Analysis and Topic Extraction in Psychiatric Readmission Risk Prediction
Oct 09, 2019

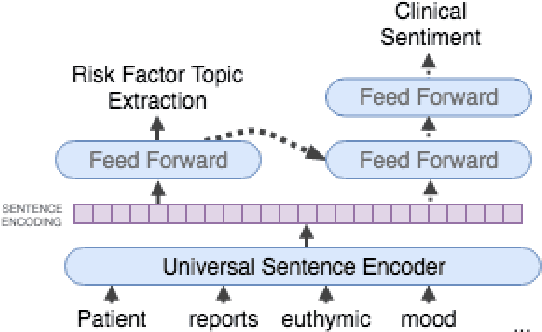
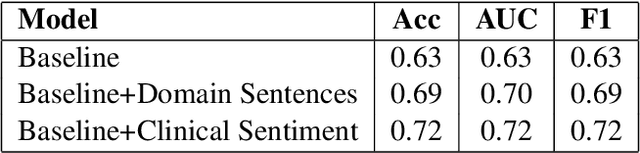
Predicting which patients are more likely to be readmitted to a hospital within 30 days after discharge is a valuable piece of information in clinical decision-making. Building a successful readmission risk classifier based on the content of Electronic Health Records (EHRs) has proved, however, to be a challenging task. Previously explored features include mainly structured information, such as sociodemographic data, comorbidity codes and physiological variables. In this paper we assess incorporating additional clinically interpretable NLP-based features such as topic extraction and clinical sentiment analysis to predict early readmission risk in psychiatry patients.
Multimodal Continuation-style Architectures for Human-Robot Interaction
Sep 18, 2019

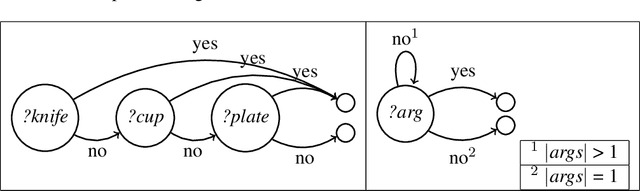
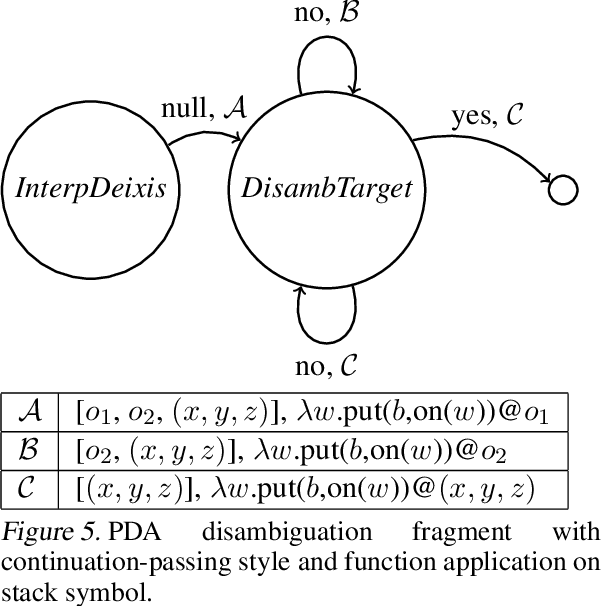
We present an architecture for integrating real-time, multimodal input into a computational agent's contextual model. Using a human-avatar interaction in a virtual world, we treat aligned gesture and speech as an ensemble where content may be communicated by either modality. With a modified nondeterministic pushdown automaton architecture, the computer system: (1) consumes input incrementally using continuation-passing style until it achieves sufficient understanding the user's aim; (2) constructs and asks questions where necessary using established contextual information; and (3) maintains track of prior discourse items using multimodal cues. This type of architecture supports special cases of pushdown and finite state automata as well as integrating outputs from machine learning models. We present examples of this architecture's use in multimodal one-shot learning interactions of novel gestures and live action composition.
Distinguishing Clinical Sentiment: The Importance of Domain Adaptation in Psychiatric Patient Health Records
Apr 05, 2019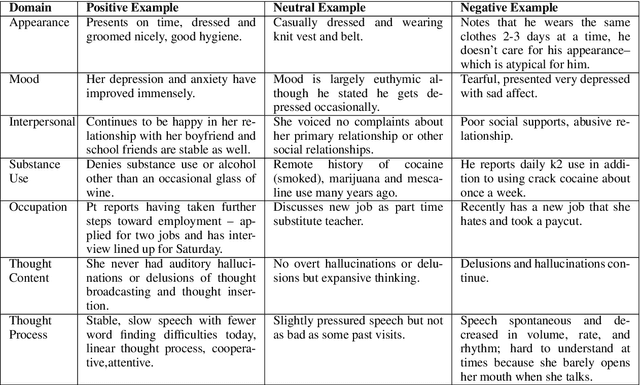
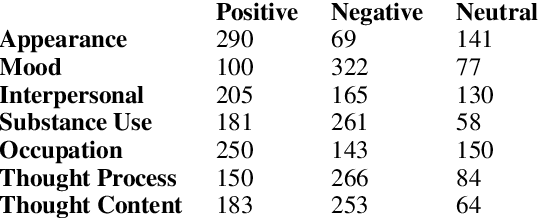
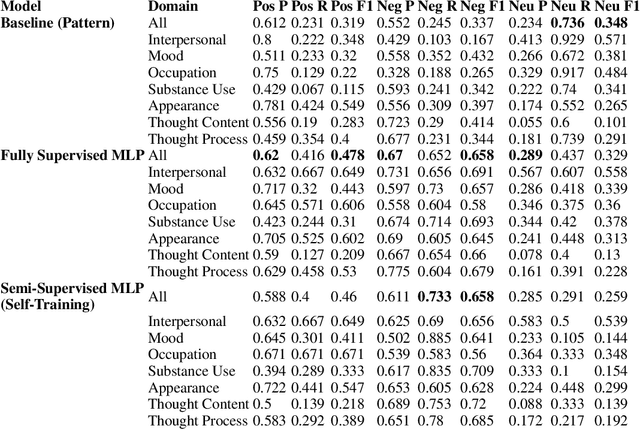

Recently natural language processing (NLP) tools have been developed to identify and extract salient risk indicators in electronic health records (EHRs). Sentiment analysis, although widely used in non-medical areas for improving decision making, has been studied minimally in the clinical setting. In this study, we undertook, to our knowledge, the first domain adaptation of sentiment analysis to psychiatric EHRs by defining psychiatric clinical sentiment, performing an annotation project, and evaluating multiple sentence-level sentiment machine learning (ML) models. Results indicate that off-the-shelf sentiment analysis tools fail in identifying clinically positive or negative polarity, and that the definition of clinical sentiment that we provide is learnable with relatively small amounts of training data. This project is an initial step towards further refining sentiment analysis methods for clinical use. Our long-term objective is to incorporate the results of this project as part of a machine learning model that predicts inpatient readmission risk. We hope that this work will initiate a discussion concerning domain adaptation of sentiment analysis to the clinical setting.
Situational Grounding within Multimodal Simulations
Feb 05, 2019



In this paper, we argue that simulation platforms enable a novel type of embodied spatial reasoning, one facilitated by a formal model of object and event semantics that renders the continuous quantitative search space of an open-world, real-time environment tractable. We provide examples for how a semantically-informed AI system can exploit the precise, numerical information provided by a game engine to perform qualitative reasoning about objects and events, facilitate learning novel concepts from data, and communicate with a human to improve its models and demonstrate its understanding. We argue that simulation environments, and game engines in particular, bring together many different notions of "simulation" and many different technologies to provide a highly-effective platform for developing both AI systems and tools to experiment in both machine and human intelligence.