 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTARGET: Benchmarking Table Retrieval for Generative Tasks
May 14, 2025The data landscape is rich with structured data, often of high value to organizations, driving important applications in data analysis and machine learning. Recent progress in representation learning and generative models for such data has led to the development of natural language interfaces to structured data, including those leveraging text-to-SQL. Contextualizing interactions, either through conversational interfaces or agentic components, in structured data through retrieval-augmented generation can provide substantial benefits in the form of freshness, accuracy, and comprehensiveness of answers. The key question is: how do we retrieve the right table(s) for the analytical query or task at hand? To this end, we introduce TARGET: a benchmark for evaluating TAble Retrieval for GEnerative Tasks. With TARGET we analyze the retrieval performance of different retrievers in isolation, as well as their impact on downstream tasks. We find that dense embedding-based retrievers far outperform a BM25 baseline which is less effective than it is for retrieval over unstructured text. We also surface the sensitivity of retrievers across various metadata (e.g., missing table titles), and demonstrate a stark variation of retrieval performance across datasets and tasks. TARGET is available at https://target-benchmark.github.io.
BlendSQL: A Scalable Dialect for Unifying Hybrid Question Answering in Relational Algebra
Feb 27, 2024Many existing end-to-end systems for hybrid question answering tasks can often be boiled down to a "prompt-and-pray" paradigm, where the user has limited control and insight into the intermediate reasoning steps used to achieve the final result. Additionally, due to the context size limitation of many transformer-based LLMs, it is often not reasonable to expect that the full structured and unstructured context will fit into a given prompt in a zero-shot setting, let alone a few-shot setting. We introduce BlendSQL, a superset of SQLite to act as a unified dialect for orchestrating reasoning across both unstructured and structured data. For hybrid question answering tasks involving multi-hop reasoning, we encode the full decomposed reasoning roadmap into a single interpretable BlendSQL query. Notably, we show that BlendSQL can scale to massive datasets and improve the performance of end-to-end systems while using 35% fewer tokens. Our code is available and installable as a package at https://github.com/parkervg/blendsql.
Correcting Semantic Parses with Natural Language through Dynamic Schema Encoding
May 31, 2023



In addressing the task of converting natural language to SQL queries, there are several semantic and syntactic challenges. It becomes increasingly important to understand and remedy the points of failure as the performance of semantic parsing systems improve. We explore semantic parse correction with natural language feedback, proposing a new solution built on the success of autoregressive decoders in text-to-SQL tasks. By separating the semantic and syntactic difficulties of the task, we show that the accuracy of text-to-SQL parsers can be boosted by up to 26% with only one turn of correction with natural language. Additionally, we show that a T5-base model is capable of correcting the errors of a T5-large model in a zero-shot, cross-parser setting.
Designing Multimodal Datasets for NLP Challenges
May 12, 2021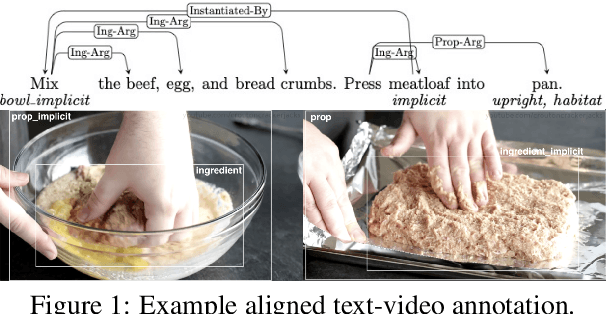


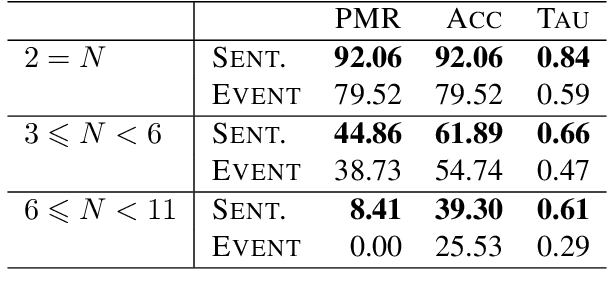
In this paper, we argue that the design and development of multimodal datasets for natural language processing (NLP) challenges should be enhanced in two significant respects: to more broadly represent commonsense semantic inferences; and to better reflect the dynamics of actions and events, through a substantive alignment of textual and visual information. We identify challenges and tasks that are reflective of linguistic and cognitive competencies that humans have when speaking and reasoning, rather than merely the performance of systems on isolated tasks. We introduce the distinction between challenge-based tasks and competence-based performance, and describe a diagnostic dataset, Recipe-to-Video Questions (R2VQ), designed for testing competence-based comprehension over a multimodal recipe collection (http://r2vq.org/). The corpus contains detailed annotation supporting such inferencing tasks and facilitating a rich set of question families that we use to evaluate NLP systems.