 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a Diagnostic and Predictive Evaluation Methodology for Sequence Labeling Tasks
Feb 13, 2026Standard evaluation in NLP typically indicates that system A is better on average than system B, but it provides little info on how to improve performance and, what is worse, it should not come as a surprise if B ends up being better than A on outside data. We propose an evaluation methodology for sequence labeling tasks grounded on error analysis that provides both quantitative and qualitative information on where systems must be improved and predicts how models will perform on a different distribution. The key is to create test sets that, contrary to common practice, do not rely on gathering large amounts of real-world in-distribution scraped data, but consists in handcrafting a small set of linguistically motivated examples that exhaustively cover the range of span attributes (such as shape, length, casing, sentence position, etc.) a system may encounter in the wild. We demonstrate this methodology on a benchmark for anglicism identification in Spanish. Our methodology provides results that are diagnostic (because they help identify systematic weaknesses in performance), actionable (because they can inform which model is better suited for a given scenario) and predictive: our method predicts model performance on external datasets with a median correlation of 0.85.
Overview of ADoBo at IberLEF 2025: Automatic Detection of Anglicisms in Spanish
Jul 29, 2025This paper summarizes the main findings of ADoBo 2025, the shared task on anglicism identification in Spanish proposed in the context of IberLEF 2025. Participants of ADoBo 2025 were asked to detect English lexical borrowings (or anglicisms) from a collection of Spanish journalistic texts. Five teams submitted their solutions for the test phase. Proposed systems included LLMs, deep learning models, Transformer-based models and rule-based systems. The results range from F1 scores of 0.17 to 0.99, which showcases the variability in performance different systems can have for this task.
Assessing the Efficacy of Clinical Sentiment Analysis and Topic Extraction in Psychiatric Readmission Risk Prediction
Oct 09, 2019

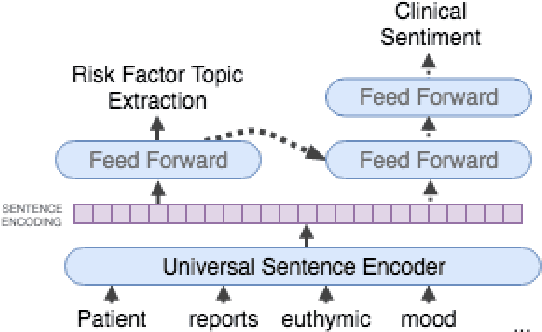
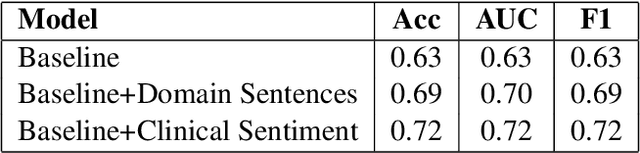
Predicting which patients are more likely to be readmitted to a hospital within 30 days after discharge is a valuable piece of information in clinical decision-making. Building a successful readmission risk classifier based on the content of Electronic Health Records (EHRs) has proved, however, to be a challenging task. Previously explored features include mainly structured information, such as sociodemographic data, comorbidity codes and physiological variables. In this paper we assess incorporating additional clinically interpretable NLP-based features such as topic extraction and clinical sentiment analysis to predict early readmission risk in psychiatry patients.