 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinguistically Conditioned Semantic Textual Similarity
Jun 06, 2024



Semantic textual similarity (STS) is a fundamental NLP task that measures the semantic similarity between a pair of sentences. In order to reduce the inherent ambiguity posed from the sentences, a recent work called Conditional STS (C-STS) has been proposed to measure the sentences' similarity conditioned on a certain aspect. Despite the popularity of C-STS, we find that the current C-STS dataset suffers from various issues that could impede proper evaluation on this task. In this paper, we reannotate the C-STS validation set and observe an annotator discrepancy on 55% of the instances resulting from the annotation errors in the original label, ill-defined conditions, and the lack of clarity in the task definition. After a thorough dataset analysis, we improve the C-STS task by leveraging the models' capability to understand the conditions under a QA task setting. With the generated answers, we present an automatic error identification pipeline that is able to identify annotation errors from the C-STS data with over 80% F1 score. We also propose a new method that largely improves the performance over baselines on the C-STS data by training the models with the answers. Finally we discuss the conditionality annotation based on the typed-feature structure (TFS) of entity types. We show in examples that the TFS is able to provide a linguistic foundation for constructing C-STS data with new conditions.
Designing Multimodal Datasets for NLP Challenges
May 12, 2021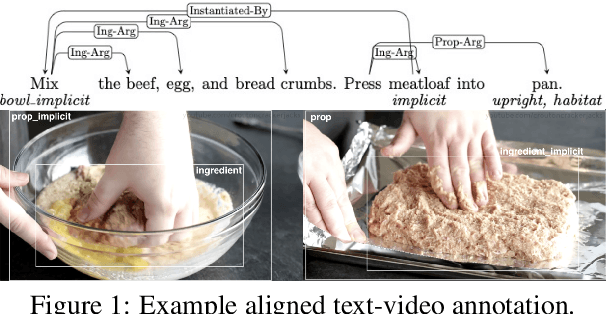


In this paper, we argue that the design and development of multimodal datasets for natural language processing (NLP) challenges should be enhanced in two significant respects: to more broadly represent commonsense semantic inferences; and to better reflect the dynamics of actions and events, through a substantive alignment of textual and visual information. We identify challenges and tasks that are reflective of linguistic and cognitive competencies that humans have when speaking and reasoning, rather than merely the performance of systems on isolated tasks. We introduce the distinction between challenge-based tasks and competence-based performance, and describe a diagnostic dataset, Recipe-to-Video Questions (R2VQ), designed for testing competence-based comprehension over a multimodal recipe collection (http://r2vq.org/). The corpus contains detailed annotation supporting such inferencing tasks and facilitating a rich set of question families that we use to evaluate NLP systems.
Multimodal Interactive Learning of Primitive Actions
Oct 01, 2018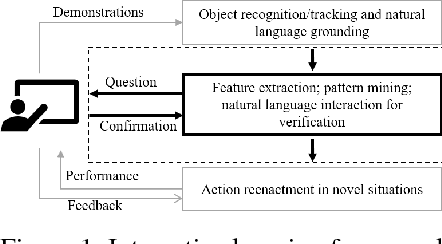

We describe an ongoing project in learning to perform primitive actions from demonstrations using an interactive interface. In our previous work, we have used demonstrations captured from humans performing actions as training samples for a neural network-based trajectory model of actions to be performed by a computational agent in novel setups. We found that our original framework had some limitations that we hope to overcome by incorporating communication between the human and the computational agent, using the interaction between them to fine-tune the model learned by the machine. We propose a framework that uses multimodal human-computer interaction to teach action concepts to machines, making use of both live demonstration and communication through natural language, as two distinct teaching modalities, while requiring few training samples.