 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformer-Based Multi-Aspect Multi-Granularity Non-Native English Speaker Pronunciation Assessment
May 06, 2022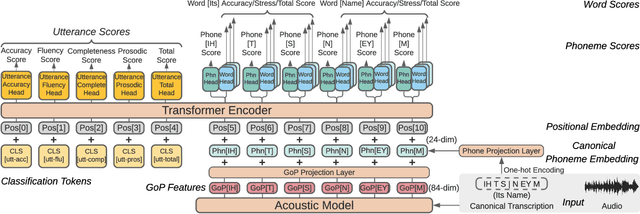
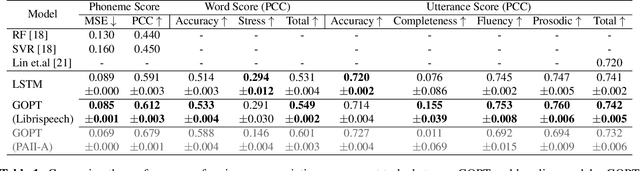
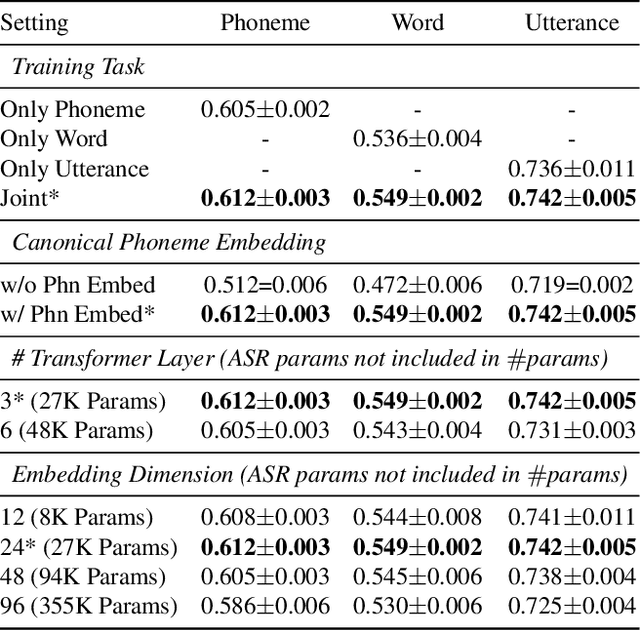

Automatic pronunciation assessment is an important technology to help self-directed language learners. While pronunciation quality has multiple aspects including accuracy, fluency, completeness, and prosody, previous efforts typically only model one aspect (e.g., accuracy) at one granularity (e.g., at the phoneme-level). In this work, we explore modeling multi-aspect pronunciation assessment at multiple granularities. Specifically, we train a Goodness Of Pronunciation feature-based Transformer (GOPT) with multi-task learning. Experiments show that GOPT achieves the best results on speechocean762 with a public automatic speech recognition (ASR) acoustic model trained on Librispeech.
DiffCSE: Difference-based Contrastive Learning for Sentence Embeddings
Apr 21, 2022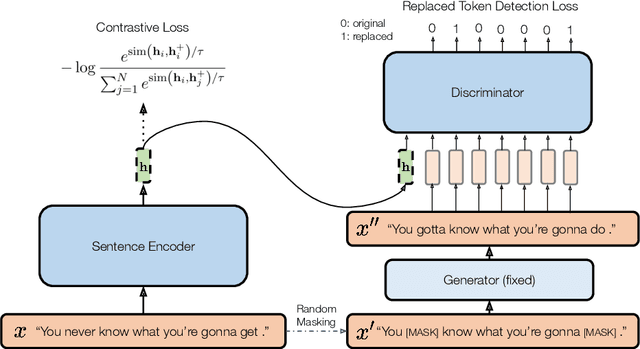
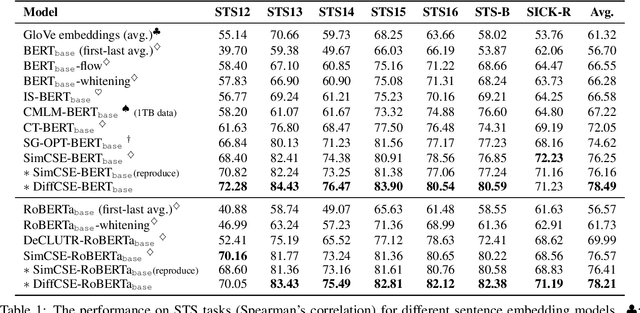
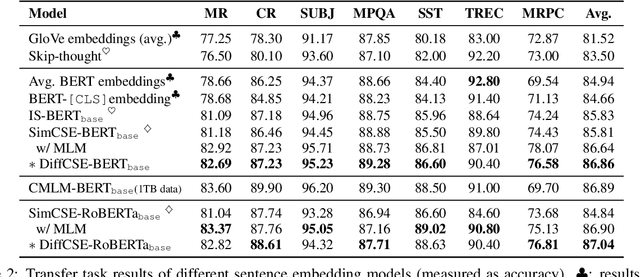
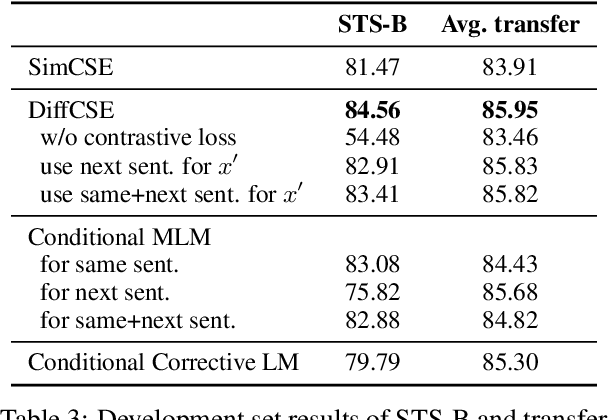
We propose DiffCSE, an unsupervised contrastive learning framework for learning sentence embeddings. DiffCSE learns sentence embeddings that are sensitive to the difference between the original sentence and an edited sentence, where the edited sentence is obtained by stochastically masking out the original sentence and then sampling from a masked language model. We show that DiffSCE is an instance of equivariant contrastive learning (Dangovski et al., 2021), which generalizes contrastive learning and learns representations that are insensitive to certain types of augmentations and sensitive to other "harmful" types of augmentations. Our experiments show that DiffCSE achieves state-of-the-art results among unsupervised sentence representation learning methods, outperforming unsupervised SimCSE by 2.3 absolute points on semantic textual similarity tasks.
Simple and Effective Unsupervised Speech Synthesis
Apr 20, 2022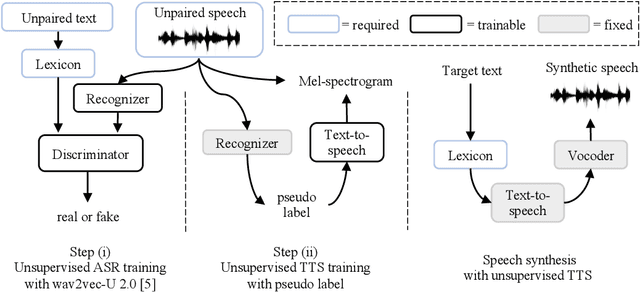
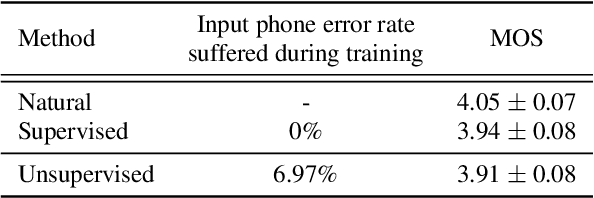
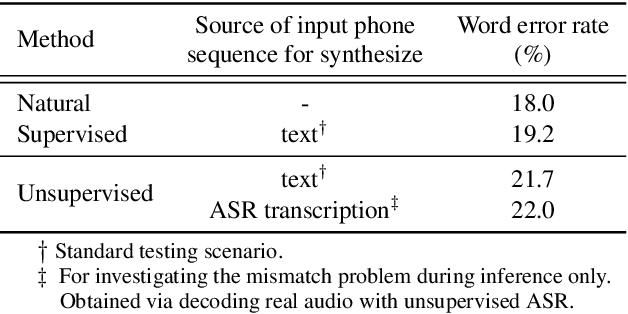

We introduce the first unsupervised speech synthesis system based on a simple, yet effective recipe. The framework leverages recent work in unsupervised speech recognition as well as existing neural-based speech synthesis. Using only unlabeled speech audio and unlabeled text as well as a lexicon, our method enables speech synthesis without the need for a human-labeled corpus. Experiments demonstrate the unsupervised system can synthesize speech similar to a supervised counterpart in terms of naturalness and intelligibility measured by human evaluation.
CMKD: CNN/Transformer-Based Cross-Model Knowledge Distillation for Audio Classification
Mar 13, 2022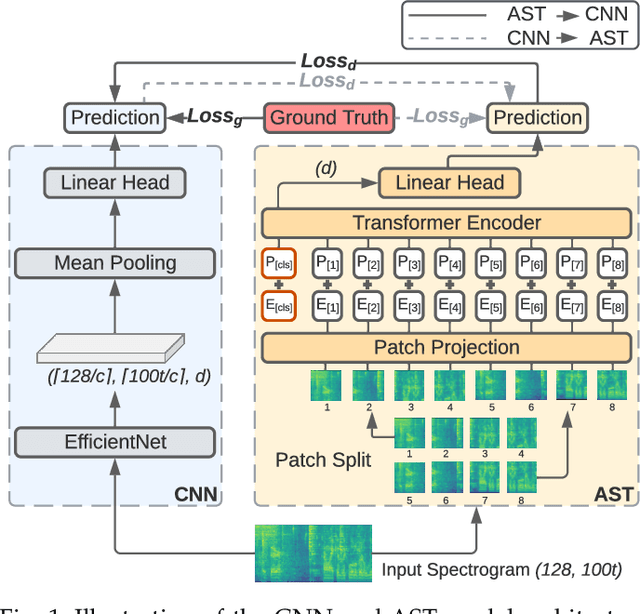
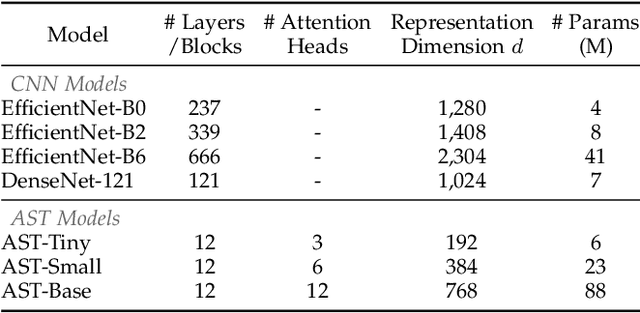
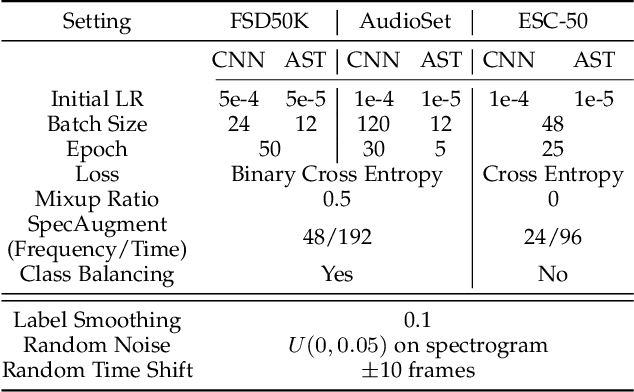
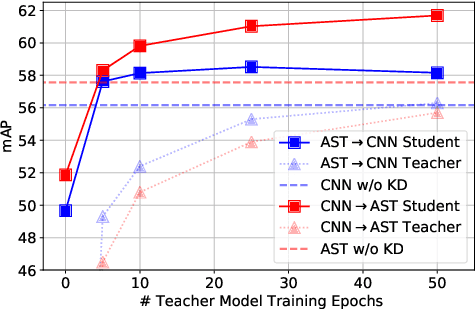
Audio classification is an active research area with a wide range of applications. Over the past decade, convolutional neural networks (CNNs) have been the de-facto standard building block for end-to-end audio classification models. Recently, neural networks based solely on self-attention mechanisms such as the Audio Spectrogram Transformer (AST) have been shown to outperform CNNs. In this paper, we find an intriguing interaction between the two very different models - CNN and AST models are good teachers for each other. When we use either of them as the teacher and train the other model as the student via knowledge distillation (KD), the performance of the student model noticeably improves, and in many cases, is better than the teacher model. In our experiments with this CNN/Transformer Cross-Model Knowledge Distillation (CMKD) method we achieve new state-of-the-art performance on FSD50K, AudioSet, and ESC-50.
Controlling the Focus of Pretrained Language Generation Models
Mar 02, 2022



The finetuning of pretrained transformer-based language generation models are typically conducted in an end-to-end manner, where the model learns to attend to relevant parts of the input by itself. However, there does not exist a mechanism to directly control the model's focus. This work aims to develop a control mechanism by which a user can select spans of context as "highlights" for the model to focus on, and generate relevant output. To achieve this goal, we augment a pretrained model with trainable "focus vectors" that are directly applied to the model's embeddings, while the model itself is kept fixed. These vectors, trained on automatic annotations derived from attribution methods, act as indicators for context importance. We test our approach on two core generation tasks: dialogue response generation and abstractive summarization. We also collect evaluation data where the highlight-generation pairs are annotated by humans. Our experiments show that the trained focus vectors are effective in steering the model to generate outputs that are relevant to user-selected highlights.
Everything at Once -- Multi-modal Fusion Transformer for Video Retrieval
Dec 08, 2021

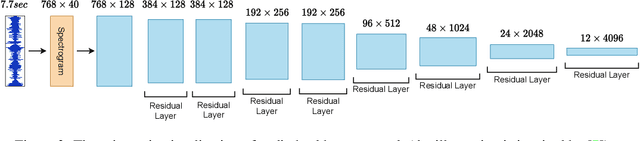
Multi-modal learning from video data has seen increased attention recently as it allows to train semantically meaningful embeddings without human annotation enabling tasks like zero-shot retrieval and classification. In this work, we present a multi-modal, modality agnostic fusion transformer approach that learns to exchange information between multiple modalities, such as video, audio, and text, and integrate them into a joined multi-modal representation to obtain an embedding that aggregates multi-modal temporal information. We propose to train the system with a combinatorial loss on everything at once, single modalities as well as pairs of modalities, explicitly leaving out any add-ons such as position or modality encoding. At test time, the resulting model can process and fuse any number of input modalities. Moreover, the implicit properties of the transformer allow to process inputs of different lengths. To evaluate the proposed approach, we train the model on the large scale HowTo100M dataset and evaluate the resulting embedding space on four challenging benchmark datasets obtaining state-of-the-art results in zero-shot video retrieval and zero-shot video action localization.
Routing with Self-Attention for Multimodal Capsule Networks
Dec 01, 2021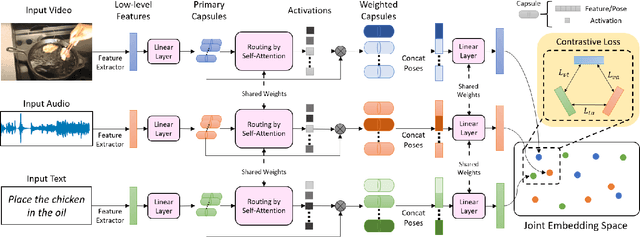
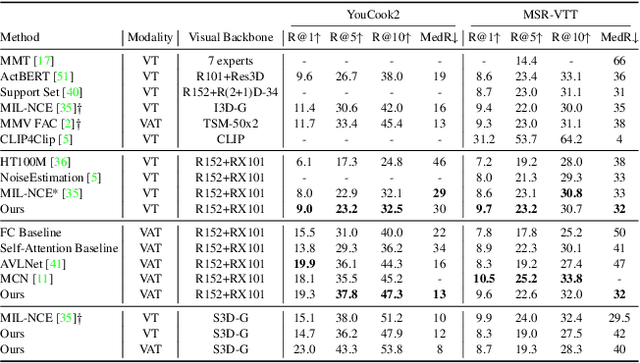
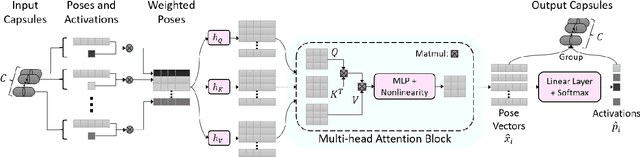
The task of multimodal learning has seen a growing interest recently as it allows for training neural architectures based on different modalities such as vision, text, and audio. One challenge in training such models is that they need to jointly learn semantic concepts and their relationships across different input representations. Capsule networks have been shown to perform well in context of capturing the relation between low-level input features and higher-level concepts. However, capsules have so far mainly been used only in small-scale fully supervised settings due to the resource demand of conventional routing algorithms. We present a new multimodal capsule network that allows us to leverage the strength of capsules in the context of a multimodal learning framework on large amounts of video data. To adapt the capsules to large-scale input data, we propose a novel routing by self-attention mechanism that selects relevant capsules which are then used to generate a final joint multimodal feature representation. This allows not only for robust training with noisy video data, but also to scale up the size of the capsule network compared to traditional routing methods while still being computationally efficient. We evaluate the proposed architecture by pretraining it on a large-scale multimodal video dataset and applying it on four datasets in two challenging downstream tasks. Results show that the proposed multimodal capsule network is not only able to improve results compared to other routing techniques, but also achieves competitive performance on the task of multimodal learning.
Cascaded Multilingual Audio-Visual Learning from Videos
Nov 08, 2021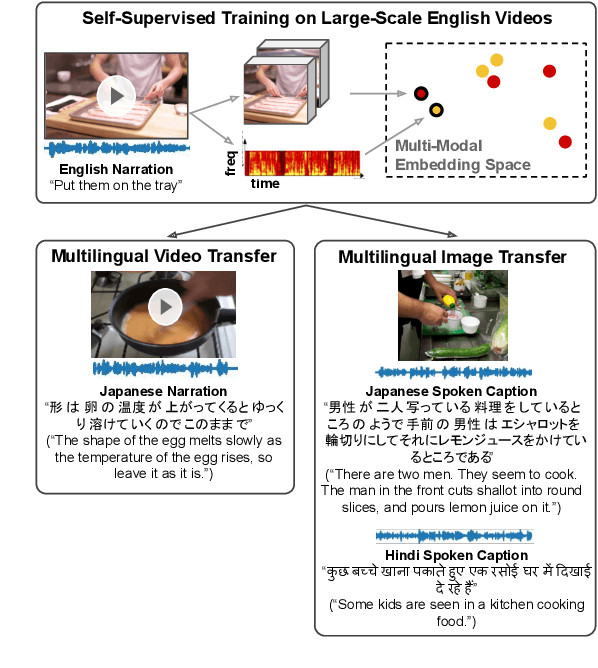
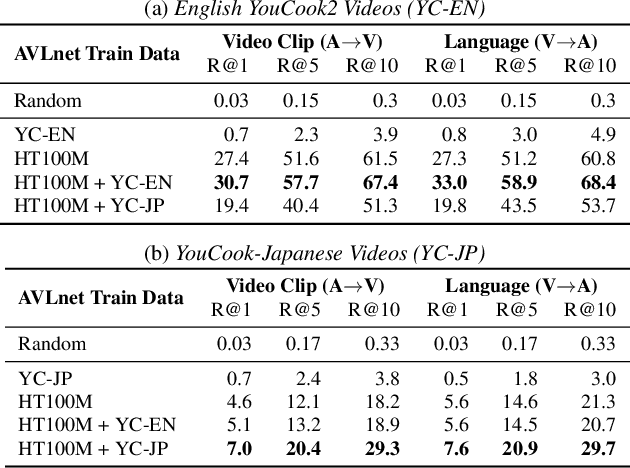

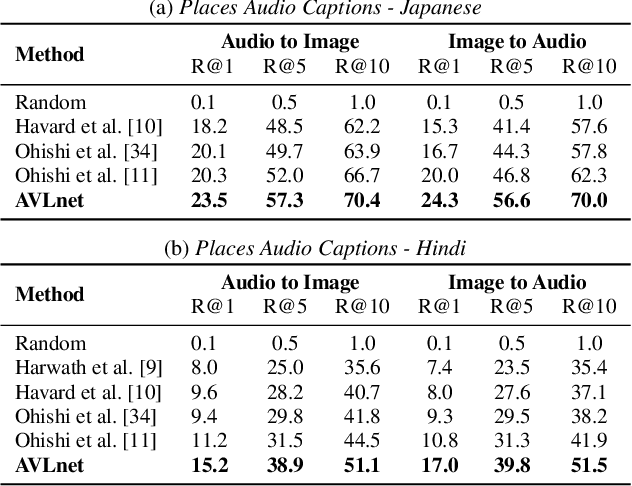
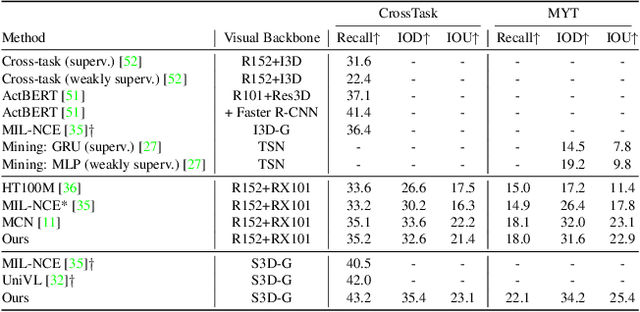
In this paper, we explore self-supervised audio-visual models that learn from instructional videos. Prior work has shown that these models can relate spoken words and sounds to visual content after training on a large-scale dataset of videos, but they were only trained and evaluated on videos in English. To learn multilingual audio-visual representations, we propose a cascaded approach that leverages a model trained on English videos and applies it to audio-visual data in other languages, such as Japanese videos. With our cascaded approach, we show an improvement in retrieval performance of nearly 10x compared to training on the Japanese videos solely. We also apply the model trained on English videos to Japanese and Hindi spoken captions of images, achieving state-of-the-art performance.
SSAST: Self-Supervised Audio Spectrogram Transformer
Oct 19, 2021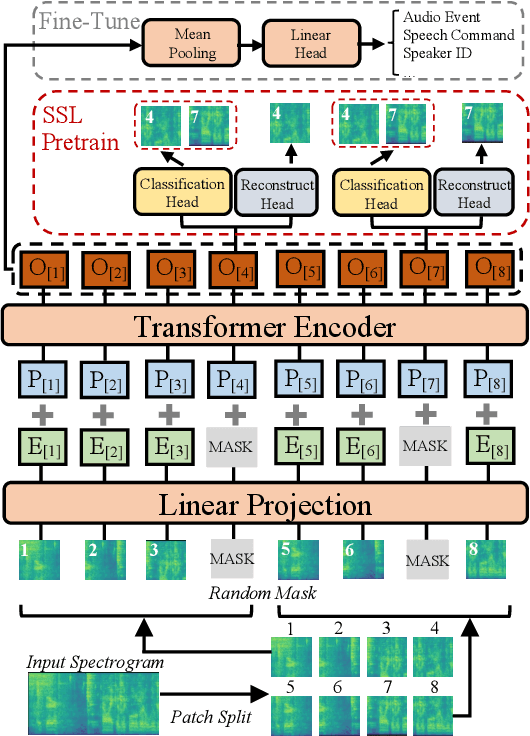
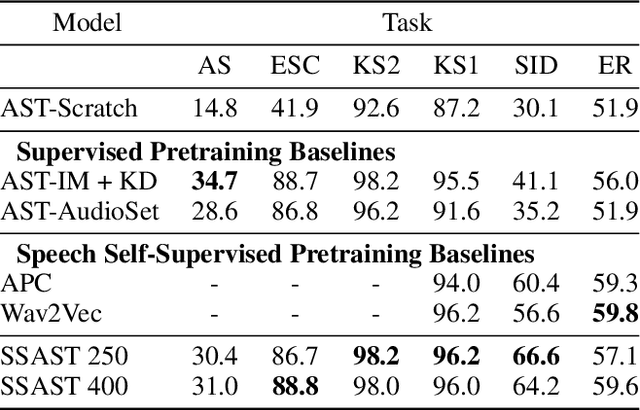
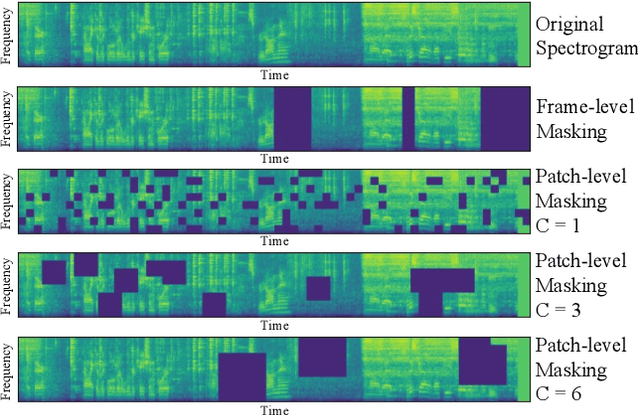
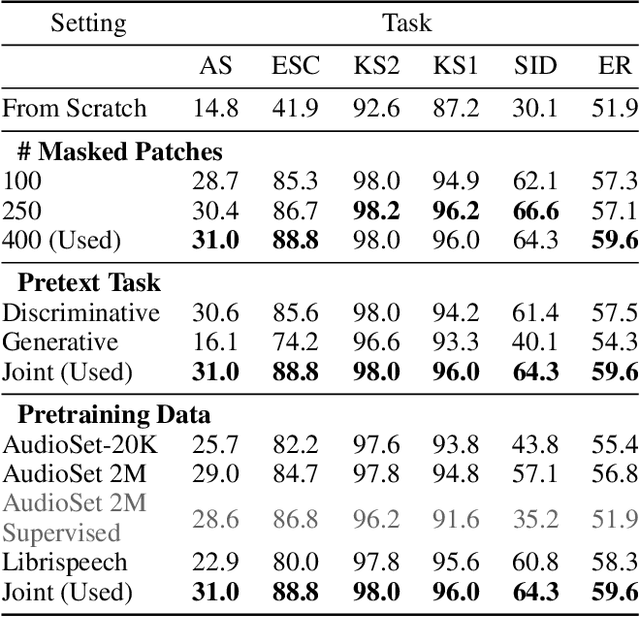
Recently, neural networks based purely on self-attention, such as the Vision Transformer (ViT), have been shown to outperform deep learning models constructed with convolutional neural networks (CNNs) on various vision tasks, thus extending the success of Transformers, which were originally developed for language processing, to the vision domain. A recent study showed that a similar methodology can also be applied to the audio domain. Specifically, the Audio Spectrogram Transformer (AST) achieves state-of-the-art results on various audio classification benchmarks. However, pure Transformer models tend to require more training data compared to CNNs, and the success of the AST relies on supervised pretraining that requires a large amount of labeled data and a complex training pipeline, thus limiting the practical usage of AST. This paper focuses on audio and speech classification, and aims to alleviate the data requirement issues with the AST by leveraging self-supervised learning using unlabeled data. Specifically, we propose to pretrain the AST model with joint discriminative and generative masked spectrogram patch modeling (MSPM) using unlabeled audio from AudioSet and Librispeech. We evaluate our pretrained models on both audio and speech classification tasks including audio event classification, keyword spotting, emotion recognition, and speaker identification. The proposed self-supervised framework significantly boosts AST performance on all tasks, with an average improvement of 60.9%, leading to similar or even better results than a supervised pretrained AST. To the best of our knowledge, it is the first patch-based self-supervised learning framework in the audio and speech domain, and also the first self-supervised learning framework for AST.
Spoken ObjectNet: A Bias-Controlled Spoken Caption Dataset
Oct 14, 2021
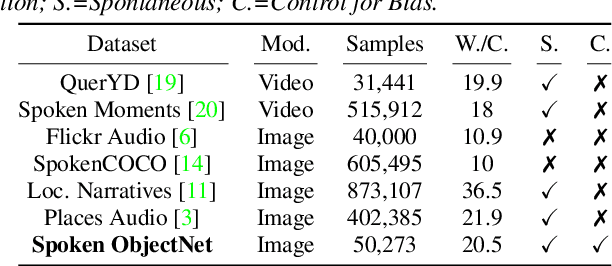


Visually-grounded spoken language datasets can enable models to learn cross-modal correspondences with very weak supervision. However, modern audio-visual datasets contain biases that undermine the real-world performance of models trained on that data. We introduce Spoken ObjectNet, which is designed to remove some of these biases and provide a way to better evaluate how effectively models will perform in real-world scenarios. This dataset expands upon ObjectNet, which is a bias-controlled image dataset that features similar image classes to those present in ImageNet. We detail our data collection pipeline, which features several methods to improve caption quality, including automated language model checks. Lastly, we show baseline results on image retrieval and audio retrieval tasks. These results show that models trained on other datasets and then evaluated on Spoken ObjectNet tend to perform poorly due to biases in other datasets that the models have learned. We also show evidence that the performance decrease is due to the dataset controls, and not the transfer setting.