 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCSTNet: Contrastive Speech Translation Network for Self-Supervised Speech Representation Learning
Paper and Code
Jun 04, 2020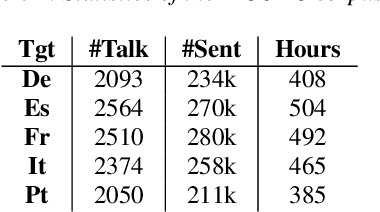
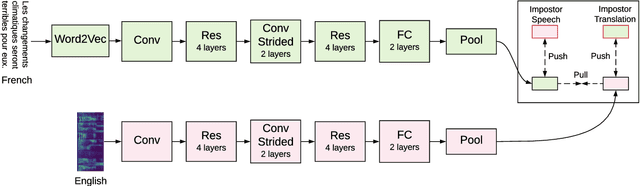
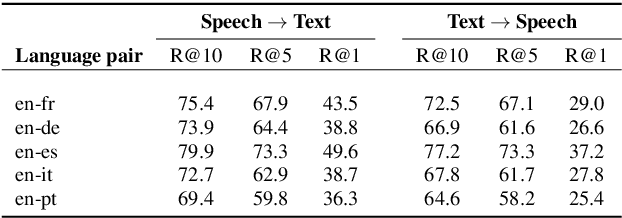
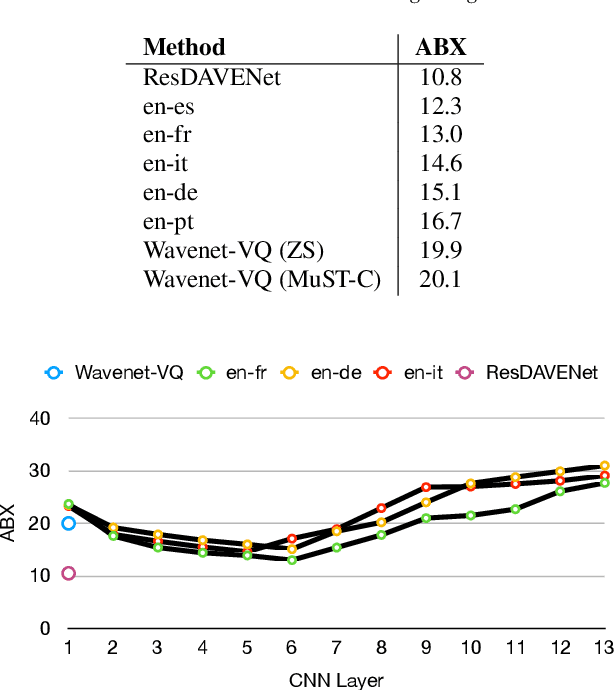
More than half of the 7,000 languages in the world are in imminent danger of going extinct. Traditional methods of documenting language proceed by collecting audio data followed by manual annotation by trained linguists at different levels of granularity. This time consuming and painstaking process could benefit from machine learning. Many endangered languages do not have any orthographic form but usually have speakers that are bi-lingual and trained in a high resource language. It is relatively easy to obtain textual translations corresponding to speech. In this work, we provide a multimodal machine learning framework for speech representation learning by exploiting the correlations between the two modalities namely speech and its corresponding text translation. Here, we construct a convolutional neural network audio encoder capable of extracting linguistic representations from speech. The audio encoder is trained to perform a speech-translation retrieval task in a contrastive learning framework. By evaluating the learned representations on a phone recognition task, we demonstrate that linguistic representations emerge in the audio encoder's internal representations as a by-product of learning to perform the retrieval task.