 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSteerable Vision-Language-Action Policies for Embodied Reasoning and Hierarchical Control
Feb 13, 2026Pretrained vision-language models (VLMs) can make semantic and visual inferences across diverse settings, providing valuable common-sense priors for robotic control. However, effectively grounding this knowledge in robot behaviors remains an open challenge. Prior methods often employ a hierarchical approach where VLMs reason over high-level commands to be executed by separate low-level policies, e.g., vision-language-action models (VLAs). The interface between VLMs and VLAs is usually natural language task instructions, which fundamentally limits how much VLM reasoning can steer low-level behavior. We thus introduce Steerable Policies: VLAs trained on rich synthetic commands at various levels of abstraction, like subtasks, motions, and grounded pixel coordinates. By improving low-level controllability, Steerable Policies can unlock pretrained knowledge in VLMs, enabling improved task generalization. We demonstrate this benefit by controlling our Steerable Policies with both a learned high-level embodied reasoner and an off-the-shelf VLM prompted to reason over command abstractions via in-context learning. Across extensive real-world manipulation experiments, these two novel methods outperform prior embodied reasoning VLAs and VLM-based hierarchical baselines, including on challenging generalization and long-horizon tasks. Website: steerable-policies.github.io
DexHub and DART: Towards Internet Scale Robot Data Collection
Nov 04, 2024



The quest to build a generalist robotic system is impeded by the scarcity of diverse and high-quality data. While real-world data collection effort exist, requirements for robot hardware, physical environment setups, and frequent resets significantly impede the scalability needed for modern learning frameworks. We introduce DART, a teleoperation platform designed for crowdsourcing that reimagines robotic data collection by leveraging cloud-based simulation and augmented reality (AR) to address many limitations of prior data collection efforts. Our user studies highlight that DART enables higher data collection throughput and lower physical fatigue compared to real-world teleoperation. We also demonstrate that policies trained using DART-collected datasets successfully transfer to reality and are robust to unseen visual disturbances. All data collected through DART is automatically stored in our cloud-hosted database, DexHub, which will be made publicly available upon curation, paving the path for DexHub to become an ever-growing data hub for robot learning. Videos are available at: https://dexhub.ai/project
Exploiting and Defending Against the Approximate Linearity of Apple's NeuralHash
Jul 28, 2022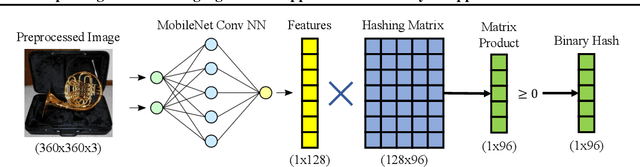

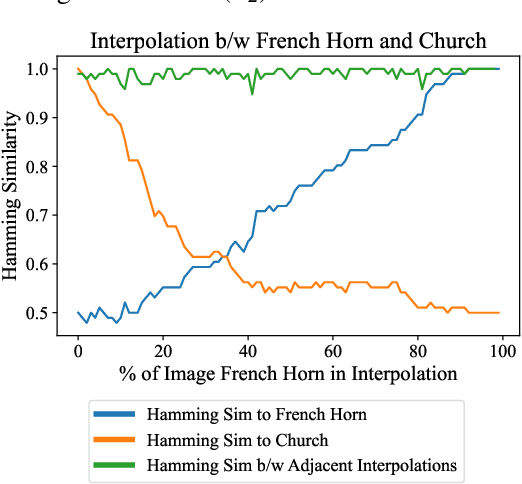
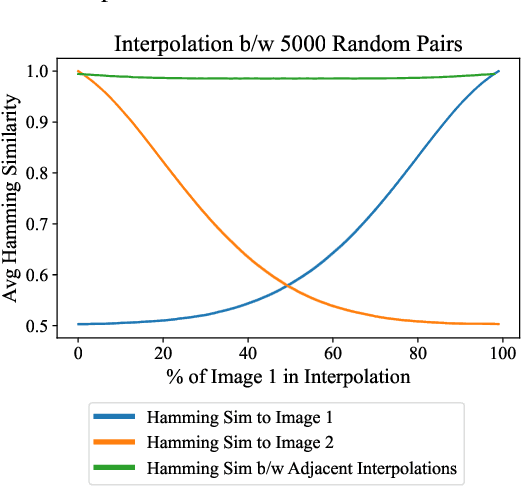
Perceptual hashes map images with identical semantic content to the same $n$-bit hash value, while mapping semantically-different images to different hashes. These algorithms carry important applications in cybersecurity such as copyright infringement detection, content fingerprinting, and surveillance. Apple's NeuralHash is one such system that aims to detect the presence of illegal content on users' devices without compromising consumer privacy. We make the surprising discovery that NeuralHash is approximately linear, which inspires the development of novel black-box attacks that can (i) evade detection of "illegal" images, (ii) generate near-collisions, and (iii) leak information about hashed images, all without access to model parameters. These vulnerabilities pose serious threats to NeuralHash's security goals; to address them, we propose a simple fix using classical cryptographic standards.
Evolution Gym: A Large-Scale Benchmark for Evolving Soft Robots
Jan 24, 2022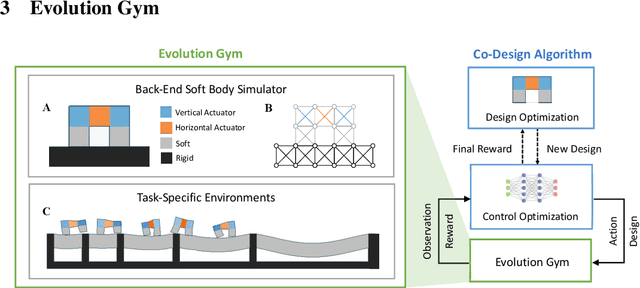
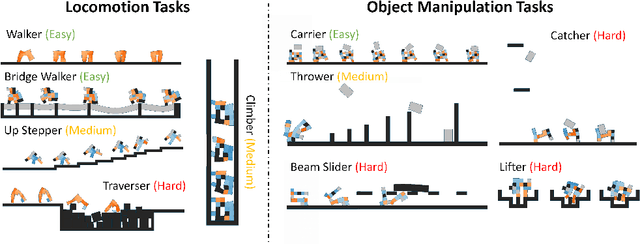
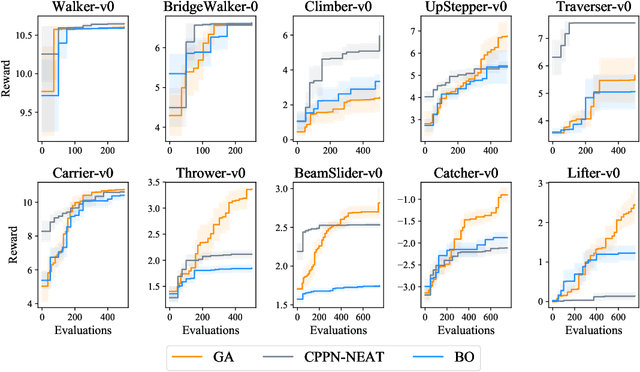
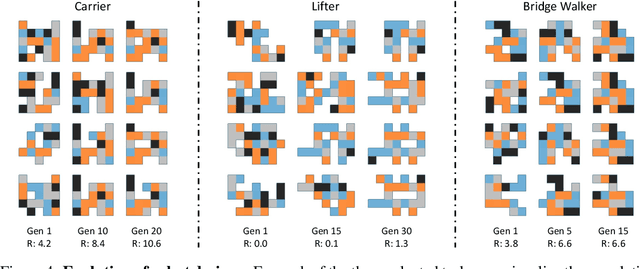
Both the design and control of a robot play equally important roles in its task performance. However, while optimal control is well studied in the machine learning and robotics community, less attention is placed on finding the optimal robot design. This is mainly because co-optimizing design and control in robotics is characterized as a challenging problem, and more importantly, a comprehensive evaluation benchmark for co-optimization does not exist. In this paper, we propose Evolution Gym, the first large-scale benchmark for co-optimizing the design and control of soft robots. In our benchmark, each robot is composed of different types of voxels (e.g., soft, rigid, actuators), resulting in a modular and expressive robot design space. Our benchmark environments span a wide range of tasks, including locomotion on various types of terrains and manipulation. Furthermore, we develop several robot co-evolution algorithms by combining state-of-the-art design optimization methods and deep reinforcement learning techniques. Evaluating the algorithms on our benchmark platform, we observe robots exhibiting increasingly complex behaviors as evolution progresses, with the best evolved designs solving many of our proposed tasks. Additionally, even though robot designs are evolved autonomously from scratch without prior knowledge, they often grow to resemble existing natural creatures while outperforming hand-designed robots. Nevertheless, all tested algorithms fail to find robots that succeed in our hardest environments. This suggests that more advanced algorithms are required to explore the high-dimensional design space and evolve increasingly intelligent robots -- an area of research in which we hope Evolution Gym will accelerate progress. Our website with code, environments, documentation, and tutorials is available at http://evogym.csail.mit.edu.