 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransforming and Combining Rewards for Aligning Large Language Models
Feb 01, 2024A common approach for aligning language models to human preferences is to first learn a reward model from preference data, and then use this reward model to update the language model. We study two closely related problems that arise in this approach. First, any monotone transformation of the reward model preserves preference ranking; is there a choice that is ``better'' than others? Second, we often wish to align language models to multiple properties: how should we combine multiple reward models? Using a probabilistic interpretation of the alignment procedure, we identify a natural choice for transformation for (the common case of) rewards learned from Bradley-Terry preference models. This derived transformation has two important properties. First, it emphasizes improving poorly-performing outputs, rather than outputs that already score well. This mitigates both underfitting (where some prompts are not improved) and reward hacking (where the model learns to exploit misspecification of the reward model). Second, it enables principled aggregation of rewards by linking summation to logical conjunction: the sum of transformed rewards corresponds to the probability that the output is ``good'' in all measured properties, in a sense we make precise. Experiments aligning language models to be both helpful and harmless using RLHF show substantial improvements over the baseline (non-transformed) approach.
Theoretical guarantees on the best-of-n alignment policy
Jan 03, 2024


A simple and effective method for the alignment of generative models is the best-of-$n$ policy, where $n$ samples are drawn from a base policy, and ranked based on a reward function, and the highest ranking one is selected. A commonly used analytical expression in the literature claims that the KL divergence between the best-of-$n$ policy and the base policy is equal to $\log (n) - (n-1)/n.$ We disprove the validity of this claim, and show that it is an upper bound on the actual KL divergence. We also explore the tightness of this upper bound in different regimes. Finally, we propose a new estimator for the KL divergence and empirically show that it provides a tight approximation through a few examples.
Helping or Herding? Reward Model Ensembles Mitigate but do not Eliminate Reward Hacking
Dec 21, 2023



Reward models play a key role in aligning language model applications towards human preferences. However, this setup creates an incentive for the language model to exploit errors in the reward model to achieve high estimated reward, a phenomenon often termed \emph{reward hacking}. A natural mitigation is to train an ensemble of reward models, aggregating over model outputs to obtain a more robust reward estimate. We explore the application of reward ensembles to alignment at both training time (through reinforcement learning) and inference time (through reranking). First, we show that reward models are \emph{underspecified}: reward models that perform similarly in-distribution can yield very different rewards when used in alignment, due to distribution shift. Second, underspecification results in overoptimization, where alignment to one reward model does not improve reward as measured by another reward model trained on the same data. Third, overoptimization is mitigated by the use of reward ensembles, and ensembles that vary by their \emph{pretraining} seeds lead to better generalization than ensembles that differ only by their \emph{fine-tuning} seeds, with both outperforming individual reward models. However, even pretrain reward ensembles do not eliminate reward hacking: we show several qualitative reward hacking phenomena that are not mitigated by ensembling because all reward models in the ensemble exhibit similar error patterns.
Selectively Answering Ambiguous Questions
May 24, 2023Trustworthy language models should abstain from answering questions when they do not know the answer. However, the answer to a question can be unknown for a variety of reasons. Prior research has focused on the case in which the question is clear and the answer is unambiguous but possibly unknown. However, the answer to a question can also be unclear due to uncertainty of the questioner's intent or context. We investigate question answering from this perspective, focusing on answering a subset of questions with a high degree of accuracy, from a set of questions in which many are inherently ambiguous. In this setting, we find that the most reliable approach to calibration involves quantifying repetition within a set of sampled model outputs, rather than the model's likelihood or self-verification as used in prior work. % We find this to be the case across different types of uncertainty, varying model scales and both with or without instruction tuning. Our results suggest that sampling-based confidence scores help calibrate answers to relatively unambiguous questions, with more dramatic improvements on ambiguous questions.
MD3: The Multi-Dialect Dataset of Dialogues
May 19, 2023



We introduce a new dataset of conversational speech representing English from India, Nigeria, and the United States. The Multi-Dialect Dataset of Dialogues (MD3) strikes a new balance between open-ended conversational speech and task-oriented dialogue by prompting participants to perform a series of short information-sharing tasks. This facilitates quantitative cross-dialectal comparison, while avoiding the imposition of a restrictive task structure that might inhibit the expression of dialect features. Preliminary analysis of the dataset reveals significant differences in syntax and in the use of discourse markers. The dataset, which will be made publicly available with the publication of this paper, includes more than 20 hours of audio and more than 200,000 orthographically-transcribed tokens.
Attributed Question Answering: Evaluation and Modeling for Attributed Large Language Models
Dec 15, 2022



Large language models (LLMs) have shown impressive results across a variety of tasks while requiring little or no direct supervision. Further, there is mounting evidence that LLMs may have potential in information-seeking scenarios. We believe the ability of an LLM to attribute the text that it generates is likely to be crucial for both system developers and users in this setting. We propose and study Attributed QA as a key first step in the development of attributed LLMs. We develop a reproducable evaluation framework for the task, using human annotations as a gold standard and a correlated automatic metric that we show is suitable for development settings. We describe and benchmark a broad set of architectures for the task. Our contributions give some concrete answers to two key questions (How to measure attribution?, and How well do current state-of-the-art methods perform on attribution?), and give some hints as to how to address a third key question (How to build LLMs with attribution?).
Dialect-robust Evaluation of Generated Text
Nov 02, 2022



Evaluation metrics that are not robust to dialect variation make it impossible to tell how well systems perform for many groups of users, and can even penalize systems for producing text in lower-resource dialects. However, currently, there exists no way to quantify how metrics respond to change in the dialect of a generated utterance. We thus formalize dialect robustness and dialect awareness as goals for NLG evaluation metrics. We introduce a suite of methods and corresponding statistical tests one can use to assess metrics in light of the two goals. Applying the suite to current state-of-the-art metrics, we demonstrate that they are not dialect-robust and that semantic perturbations frequently lead to smaller decreases in a metric than the introduction of dialect features. As a first step to overcome this limitation, we propose a training schema, NANO, which introduces regional and language information to the pretraining process of a metric. We demonstrate that NANO provides a size-efficient way for models to improve the dialect robustness while simultaneously improving their performance on the standard metric benchmark.
Predicting Long-Term Citations from Short-Term Linguistic Influence
Oct 24, 2022



A standard measure of the influence of a research paper is the number of times it is cited. However, papers may be cited for many reasons, and citation count offers limited information about the extent to which a paper affected the content of subsequent publications. We therefore propose a novel method to quantify linguistic influence in timestamped document collections. There are two main steps: first, identify lexical and semantic changes using contextual embeddings and word frequencies; second, aggregate information about these changes into per-document influence scores by estimating a high-dimensional Hawkes process with a low-rank parameter matrix. We show that this measure of linguistic influence is predictive of $\textit{future}$ citations: the estimate of linguistic influence from the two years after a paper's publication is correlated with and predictive of its citation count in the following three years. This is demonstrated using an online evaluation with incremental temporal training/test splits, in comparison with a strong baseline that includes predictors for initial citation counts, topics, and lexical features.
Honest Students from Untrusted Teachers: Learning an Interpretable Question-Answering Pipeline from a Pretrained Language Model
Oct 05, 2022
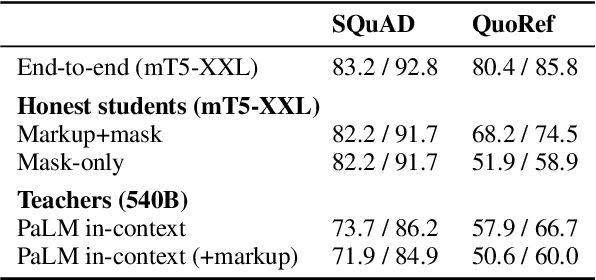


Explainable question answering systems should produce not only accurate answers but also rationales that justify their reasoning and allow humans to check their work. But what sorts of rationales are useful and how can we train systems to produce them? We propose a new style of rationale for open-book question answering, called \emph{markup-and-mask}, which combines aspects of extractive and free-text explanations. In the markup phase, the passage is augmented with free-text markup that enables each sentence to stand on its own outside the discourse context. In the masking phase, a sub-span of the marked-up passage is selected. To train a system to produce markup-and-mask rationales without annotations, we leverage in-context learning. Specifically, we generate silver annotated data by sending a series of prompts to a frozen pretrained language model, which acts as a teacher. We then fine-tune a smaller student model by training on the subset of rationales that led to correct answers. The student is "honest" in the sense that it is a pipeline: the rationale acts as a bottleneck between the passage and the answer, while the "untrusted" teacher operates under no such constraints. Thus, we offer a new way to build trustworthy pipeline systems from a combination of end-task annotations and frozen pretrained language models.
Uninformative Input Features and Counterfactual Invariance: Two Perspectives on Spurious Correlations in Natural Language
Apr 09, 2022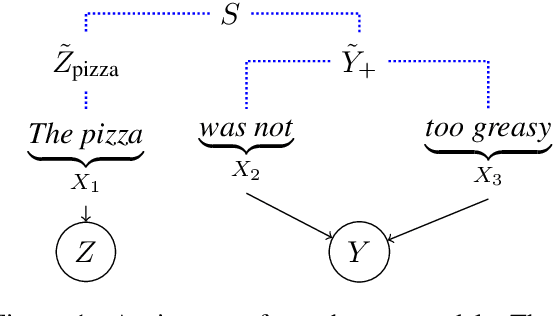
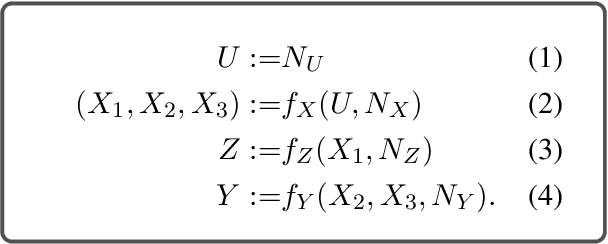
Spurious correlations are a threat to the trustworthiness of natural language processing systems, motivating research into methods for identifying and eliminating them. Gardner et al (2021) argue that the compositional nature of language implies that \emph{all} correlations between labels and individual input features are spurious. This paper analyzes this proposal in the context of a toy example, demonstrating three distinct conditions that can give rise to feature-label correlations in a simple PCFG. Linking the toy example to a structured causal model shows that (1) feature-label correlations can arise even when the label is invariant to interventions on the feature, and (2) feature-label correlations may be absent even when the label is sensitive to interventions on the feature. Because input features will be individually correlated with labels in all but very rare circumstances, domain knowledge must be applied to identify spurious correlations that pose genuine robustness threats.