 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe MultiBERTs: BERT Reproductions for Robustness Analysis
Paper and Code
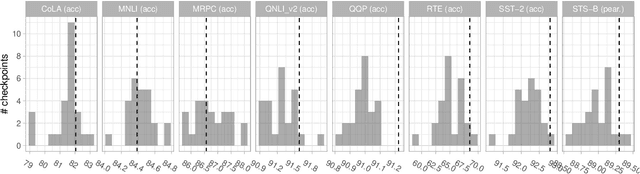
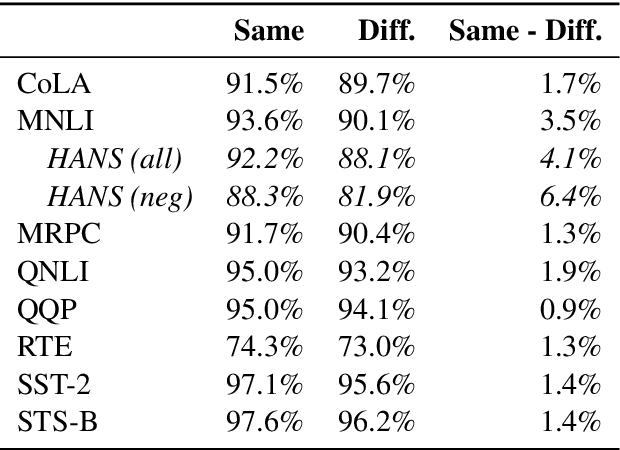
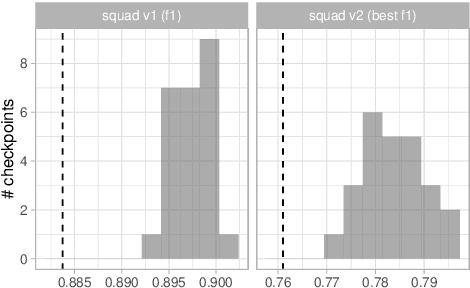
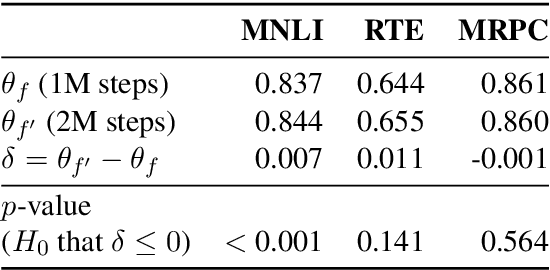
Experiments with pretrained models such as BERT are often based on a single checkpoint. While the conclusions drawn apply to the artifact (i.e., the particular instance of the model), it is not always clear whether they hold for the more general procedure (which includes the model architecture, training data, initialization scheme, and loss function). Recent work has shown that re-running pretraining can lead to substantially different conclusions about performance, suggesting that alternative evaluations are needed to make principled statements about procedures. To address this question, we introduce MultiBERTs: a set of 25 BERT-base checkpoints, trained with similar hyper-parameters as the original BERT model but differing in random initialization and data shuffling. The aim is to enable researchers to draw robust and statistically justified conclusions about pretraining procedures. The full release includes 25 fully trained checkpoints, as well as statistical guidelines and a code library implementing our recommended hypothesis testing methods. Finally, for five of these models we release a set of 28 intermediate checkpoints in order to support research on learning dynamics.