 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Oct 11, 2018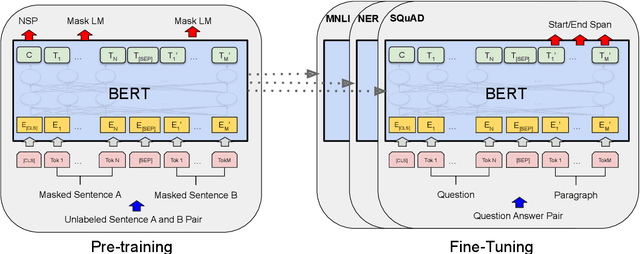
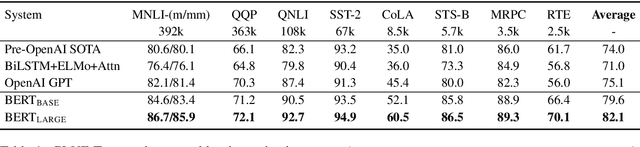
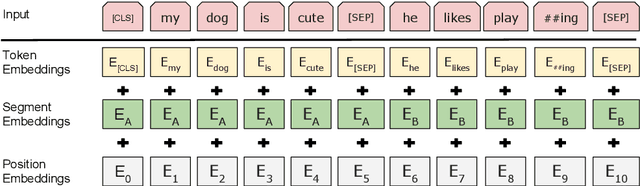
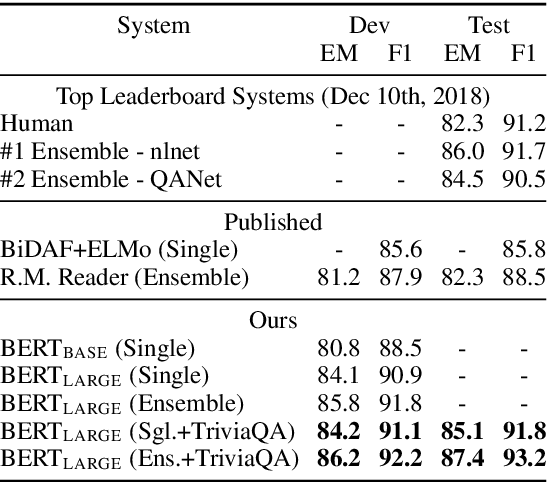
We introduce a new language representation model called BERT, which stands for Bidirectional Encoder Representations from Transformers. Unlike recent language representation models, BERT is designed to pre-train deep bidirectional representations by jointly conditioning on both left and right context in all layers. As a result, the pre-trained BERT representations can be fine-tuned with just one additional output layer to create state-of-the-art models for a wide range of tasks, such as question answering and language inference, without substantial task-specific architecture modifications. BERT is conceptually simple and empirically powerful. It obtains new state-of-the-art results on eleven natural language processing tasks, including pushing the GLUE benchmark to 80.4% (7.6% absolute improvement), MultiNLI accuracy to 86.7 (5.6% absolute improvement) and the SQuAD v1.1 question answering Test F1 to 93.2 (1.5% absolute improvement), outperforming human performance by 2.0%.
Leveraging Grammar and Reinforcement Learning for Neural Program Synthesis
May 22, 2018
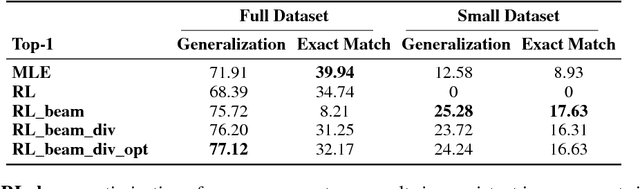
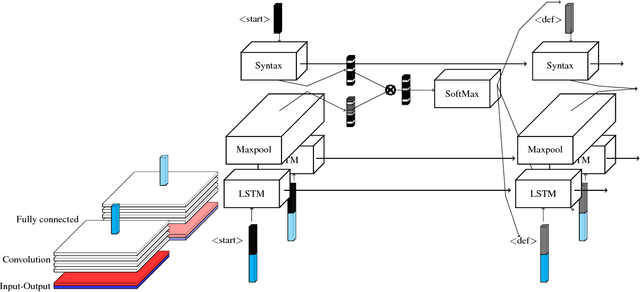
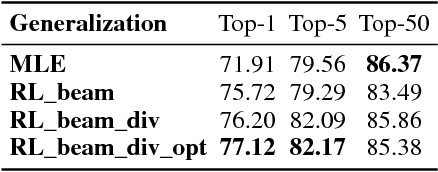
Program synthesis is the task of automatically generating a program consistent with a specification. Recent years have seen proposal of a number of neural approaches for program synthesis, many of which adopt a sequence generation paradigm similar to neural machine translation, in which sequence-to-sequence models are trained to maximize the likelihood of known reference programs. While achieving impressive results, this strategy has two key limitations. First, it ignores Program Aliasing: the fact that many different programs may satisfy a given specification (especially with incomplete specifications such as a few input-output examples). By maximizing the likelihood of only a single reference program, it penalizes many semantically correct programs, which can adversely affect the synthesizer performance. Second, this strategy overlooks the fact that programs have a strict syntax that can be efficiently checked. To address the first limitation, we perform reinforcement learning on top of a supervised model with an objective that explicitly maximizes the likelihood of generating semantically correct programs. For addressing the second limitation, we introduce a training procedure that directly maximizes the probability of generating syntactically correct programs that fulfill the specification. We show that our contributions lead to improved accuracy of the models, especially in cases where the training data is limited.
Universal Neural Machine Translation for Extremely Low Resource Languages
Apr 17, 2018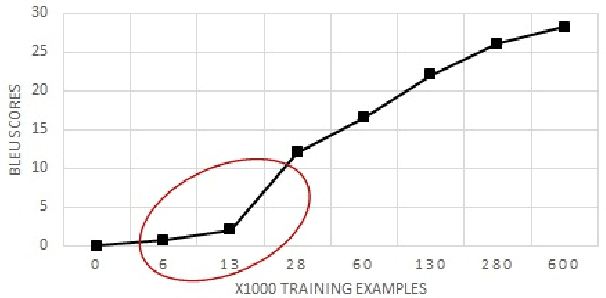

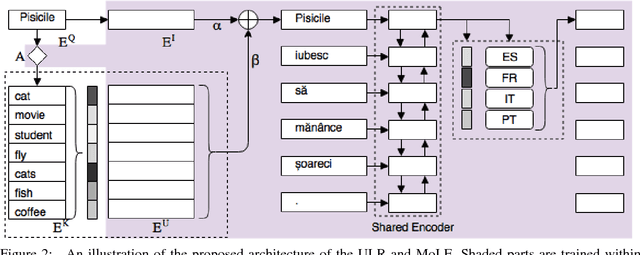

In this paper, we propose a new universal machine translation approach focusing on languages with a limited amount of parallel data. Our proposed approach utilizes a transfer-learning approach to share lexical and sentence level representations across multiple source languages into one target language. The lexical part is shared through a Universal Lexical Representation to support multilingual word-level sharing. The sentence-level sharing is represented by a model of experts from all source languages that share the source encoders with all other languages. This enables the low-resource language to utilize the lexical and sentence representations of the higher resource languages. Our approach is able to achieve 23 BLEU on Romanian-English WMT2016 using a tiny parallel corpus of 6k sentences, compared to the 18 BLEU of strong baseline system which uses multilingual training and back-translation. Furthermore, we show that the proposed approach can achieve almost 20 BLEU on the same dataset through fine-tuning a pre-trained multi-lingual system in a zero-shot setting.
Semantic Code Repair using Neuro-Symbolic Transformation Networks
Oct 30, 2017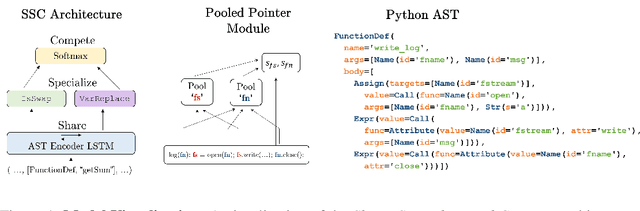

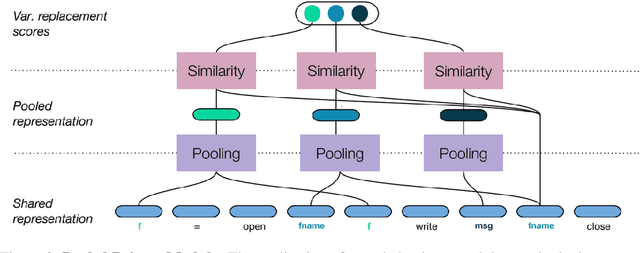
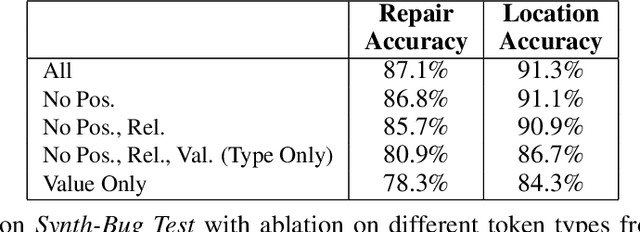
We study the problem of semantic code repair, which can be broadly defined as automatically fixing non-syntactic bugs in source code. The majority of past work in semantic code repair assumed access to unit tests against which candidate repairs could be validated. In contrast, the goal here is to develop a strong statistical model to accurately predict both bug locations and exact fixes without access to information about the intended correct behavior of the program. Achieving such a goal requires a robust contextual repair model, which we train on a large corpus of real-world source code that has been augmented with synthetically injected bugs. Our framework adopts a two-stage approach where first a large set of repair candidates are generated by rule-based processors, and then these candidates are scored by a statistical model using a novel neural network architecture which we refer to as Share, Specialize, and Compete. Specifically, the architecture (1) generates a shared encoding of the source code using an RNN over the abstract syntax tree, (2) scores each candidate repair using specialized network modules, and (3) then normalizes these scores together so they can compete against one another in comparable probability space. We evaluate our model on a real-world test set gathered from GitHub containing four common categories of bugs. Our model is able to predict the exact correct repair 41\% of the time with a single guess, compared to 13\% accuracy for an attentional sequence-to-sequence model.
Neural Program Meta-Induction
Oct 11, 2017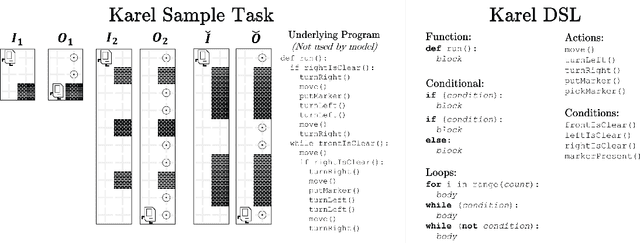

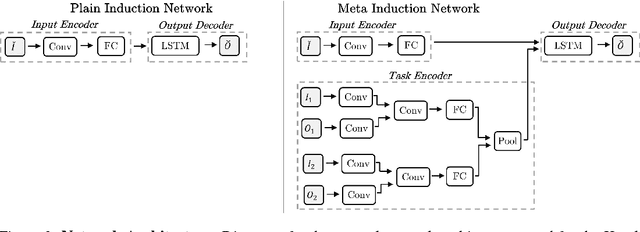

Most recently proposed methods for Neural Program Induction work under the assumption of having a large set of input/output (I/O) examples for learning any underlying input-output mapping. This paper aims to address the problem of data and computation efficiency of program induction by leveraging information from related tasks. Specifically, we propose two approaches for cross-task knowledge transfer to improve program induction in limited-data scenarios. In our first proposal, portfolio adaptation, a set of induction models is pretrained on a set of related tasks, and the best model is adapted towards the new task using transfer learning. In our second approach, meta program induction, a $k$-shot learning approach is used to make a model generalize to new tasks without additional training. To test the efficacy of our methods, we constructed a new benchmark of programs written in the Karel programming language. Using an extensive experimental evaluation on the Karel benchmark, we demonstrate that our proposals dramatically outperform the baseline induction method that does not use knowledge transfer. We also analyze the relative performance of the two approaches and study conditions in which they perform best. In particular, meta induction outperforms all existing approaches under extreme data sparsity (when a very small number of examples are available), i.e., fewer than ten. As the number of available I/O examples increase (i.e. a thousand or more), portfolio adapted program induction becomes the best approach. For intermediate data sizes, we demonstrate that the combined method of adapted meta program induction has the strongest performance.
Sharp Models on Dull Hardware: Fast and Accurate Neural Machine Translation Decoding on the CPU
May 04, 2017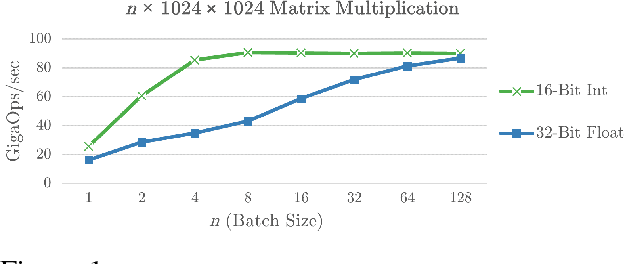
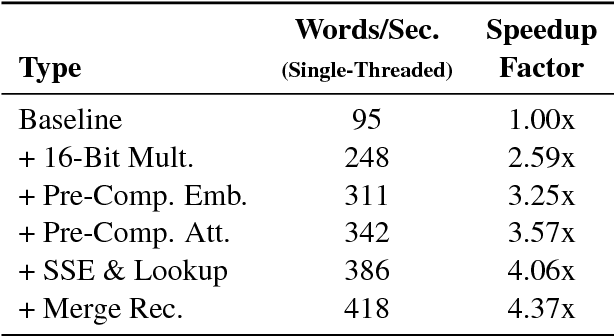

Attentional sequence-to-sequence models have become the new standard for machine translation, but one challenge of such models is a significant increase in training and decoding cost compared to phrase-based systems. Here, we focus on efficient decoding, with a goal of achieving accuracy close the state-of-the-art in neural machine translation (NMT), while achieving CPU decoding speed/throughput close to that of a phrasal decoder. We approach this problem from two angles: First, we describe several techniques for speeding up an NMT beam search decoder, which obtain a 4.4x speedup over a very efficient baseline decoder without changing the decoder output. Second, we propose a simple but powerful network architecture which uses an RNN (GRU/LSTM) layer at bottom, followed by a series of stacked fully-connected layers applied at every timestep. This architecture achieves similar accuracy to a deep recurrent model, at a small fraction of the training and decoding cost. By combining these techniques, our best system achieves a very competitive accuracy of 38.3 BLEU on WMT English-French NewsTest2014, while decoding at 100 words/sec on single-threaded CPU. We believe this is the best published accuracy/speed trade-off of an NMT system.
RobustFill: Neural Program Learning under Noisy I/O
Mar 21, 2017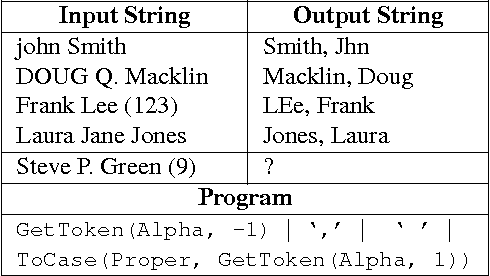

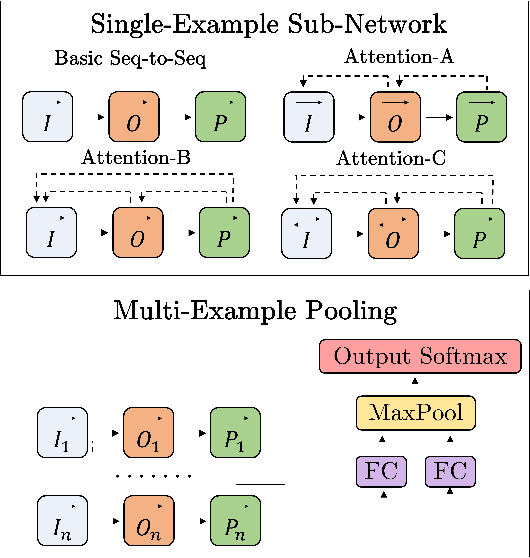
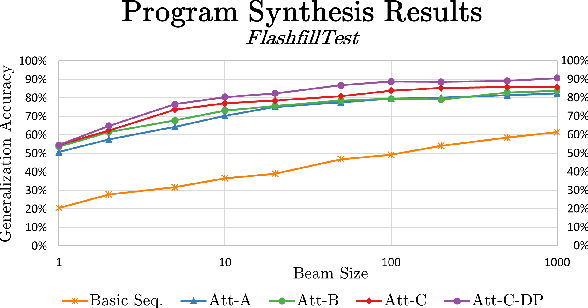
The problem of automatically generating a computer program from some specification has been studied since the early days of AI. Recently, two competing approaches for automatic program learning have received significant attention: (1) neural program synthesis, where a neural network is conditioned on input/output (I/O) examples and learns to generate a program, and (2) neural program induction, where a neural network generates new outputs directly using a latent program representation. Here, for the first time, we directly compare both approaches on a large-scale, real-world learning task. We additionally contrast to rule-based program synthesis, which uses hand-crafted semantics to guide the program generation. Our neural models use a modified attention RNN to allow encoding of variable-sized sets of I/O pairs. Our best synthesis model achieves 92% accuracy on a real-world test set, compared to the 34% accuracy of the previous best neural synthesis approach. The synthesis model also outperforms a comparable induction model on this task, but we more importantly demonstrate that the strength of each approach is highly dependent on the evaluation metric and end-user application. Finally, we show that we can train our neural models to remain very robust to the type of noise expected in real-world data (e.g., typos), while a highly-engineered rule-based system fails entirely.
Generating Natural Questions About an Image
Jun 09, 2016



There has been an explosion of work in the vision & language community during the past few years from image captioning to video transcription, and answering questions about images. These tasks have focused on literal descriptions of the image. To move beyond the literal, we choose to explore how questions about an image are often directed at commonsense inference and the abstract events evoked by objects in the image. In this paper, we introduce the novel task of Visual Question Generation (VQG), where the system is tasked with asking a natural and engaging question when shown an image. We provide three datasets which cover a variety of images from object-centric to event-centric, with considerably more abstract training data than provided to state-of-the-art captioning systems thus far. We train and test several generative and retrieval models to tackle the task of VQG. Evaluation results show that while such models ask reasonable questions for a variety of images, there is still a wide gap with human performance which motivates further work on connecting images with commonsense knowledge and pragmatics. Our proposed task offers a new challenge to the community which we hope furthers interest in exploring deeper connections between vision & language.
Visual Storytelling
Apr 13, 2016

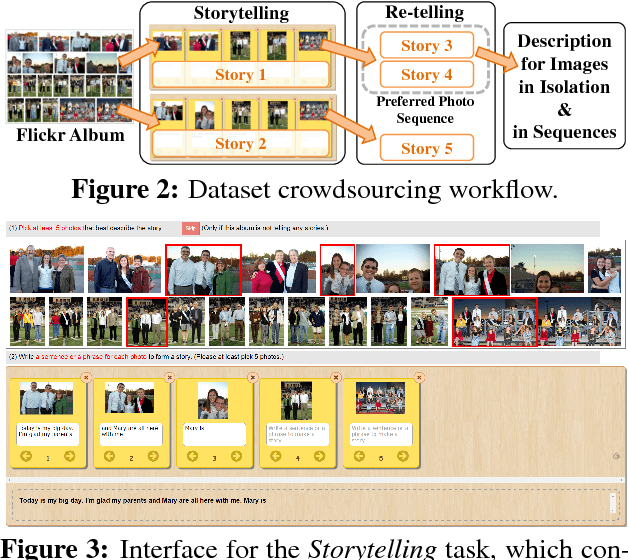
We introduce the first dataset for sequential vision-to-language, and explore how this data may be used for the task of visual storytelling. The first release of this dataset, SIND v.1, includes 81,743 unique photos in 20,211 sequences, aligned to both descriptive (caption) and story language. We establish several strong baselines for the storytelling task, and motivate an automatic metric to benchmark progress. Modelling concrete description as well as figurative and social language, as provided in this dataset and the storytelling task, has the potential to move artificial intelligence from basic understandings of typical visual scenes towards more and more human-like understanding of grounded event structure and subjective expression.
Detecting Interrogative Utterances with Recurrent Neural Networks
Nov 16, 2015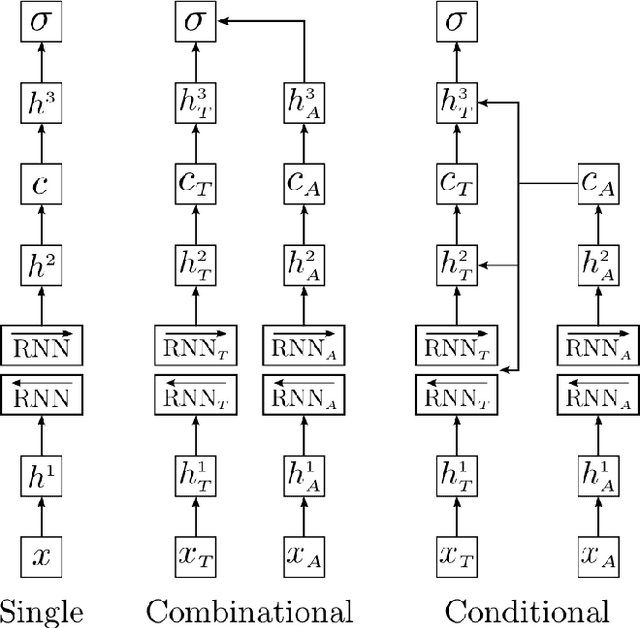
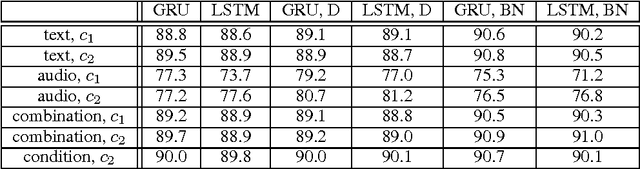
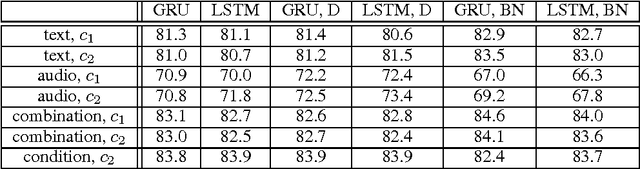

In this paper, we explore different neural network architectures that can predict if a speaker of a given utterance is asking a question or making a statement. We com- pare the outcomes of regularization methods that are popularly used to train deep neural networks and study how different context functions can affect the classification performance. We also compare the efficacy of gated activation functions that are favorably used in recurrent neural networks and study how to combine multimodal inputs. We evaluate our models on two multimodal datasets: MSR-Skype and CALLHOME.