 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExamining Modality Incongruity in Multimodal Federated Learning for Medical Vision and Language-based Disease Detection
Feb 07, 2024Multimodal Federated Learning (MMFL) utilizes multiple modalities in each client to build a more powerful Federated Learning (FL) model than its unimodal counterpart. However, the impact of missing modality in different clients, also called modality incongruity, has been greatly overlooked. This paper, for the first time, analyses the impact of modality incongruity and reveals its connection with data heterogeneity across participating clients. We particularly inspect whether incongruent MMFL with unimodal and multimodal clients is more beneficial than unimodal FL. Furthermore, we examine three potential routes of addressing this issue. Firstly, we study the effectiveness of various self-attention mechanisms towards incongruity-agnostic information fusion in MMFL. Secondly, we introduce a modality imputation network (MIN) pre-trained in a multimodal client for modality translation in unimodal clients and investigate its potential towards mitigating the missing modality problem. Thirdly, we assess the capability of client-level and server-level regularization techniques towards mitigating modality incongruity effects. Experiments are conducted under several MMFL settings on two publicly available real-world datasets, MIMIC-CXR and Open-I, with Chest X-Ray and radiology reports.
Dual Conditioned Diffusion Models for Out-Of-Distribution Detection: Application to Fetal Ultrasound Videos
Nov 01, 2023Out-of-distribution (OOD) detection is essential to improve the reliability of machine learning models by detecting samples that do not belong to the training distribution. Detecting OOD samples effectively in certain tasks can pose a challenge because of the substantial heterogeneity within the in-distribution (ID), and the high structural similarity between ID and OOD classes. For instance, when detecting heart views in fetal ultrasound videos there is a high structural similarity between the heart and other anatomies such as the abdomen, and large in-distribution variance as a heart has 5 distinct views and structural variations within each view. To detect OOD samples in this context, the resulting model should generalise to the intra-anatomy variations while rejecting similar OOD samples. In this paper, we introduce dual-conditioned diffusion models (DCDM) where we condition the model on in-distribution class information and latent features of the input image for reconstruction-based OOD detection. This constrains the generative manifold of the model to generate images structurally and semantically similar to those within the in-distribution. The proposed model outperforms reference methods with a 12% improvement in accuracy, 22% higher precision, and an 8% better F1 score.
Rethinking Semi-Supervised Federated Learning: How to co-train fully-labeled and fully-unlabeled client imaging data
Oct 28, 2023The most challenging, yet practical, setting of semi-supervised federated learning (SSFL) is where a few clients have fully labeled data whereas the other clients have fully unlabeled data. This is particularly common in healthcare settings where collaborating partners (typically hospitals) may have images but not annotations. The bottleneck in this setting is the joint training of labeled and unlabeled clients as the objective function for each client varies based on the availability of labels. This paper investigates an alternative way for effective training with labeled and unlabeled clients in a federated setting. We propose a novel learning scheme specifically designed for SSFL which we call Isolated Federated Learning (IsoFed) that circumvents the problem by avoiding simple averaging of supervised and semi-supervised models together. In particular, our training approach consists of two parts - (a) isolated aggregation of labeled and unlabeled client models, and (b) local self-supervised pretraining of isolated global models in all clients. We evaluate our model performance on medical image datasets of four different modalities publicly available within the biomedical image classification benchmark MedMNIST. We further vary the proportion of labeled clients and the degree of heterogeneity to demonstrate the effectiveness of the proposed method under varied experimental settings.
Show from Tell: Audio-Visual Modelling in Clinical Settings
Oct 25, 2023



Auditory and visual signals usually present together and correlate with each other, not only in natural environments but also in clinical settings. However, the audio-visual modelling in the latter case can be more challenging, due to the different sources of audio/video signals and the noise (both signal-level and semantic-level) in auditory signals -- usually speech. In this paper, we consider audio-visual modelling in a clinical setting, providing a solution to learn medical representations that benefit various clinical tasks, without human expert annotation. A simple yet effective multi-modal self-supervised learning framework is proposed for this purpose. The proposed approach is able to localise anatomical regions of interest during ultrasound imaging, with only speech audio as a reference. Experimental evaluations on a large-scale clinical multi-modal ultrasound video dataset show that the proposed self-supervised method learns good transferable anatomical representations that boost the performance of automated downstream clinical tasks, even outperforming fully-supervised solutions.
Prototypical few-shot segmentation for cross-institution male pelvic structures with spatial registration
Sep 13, 2022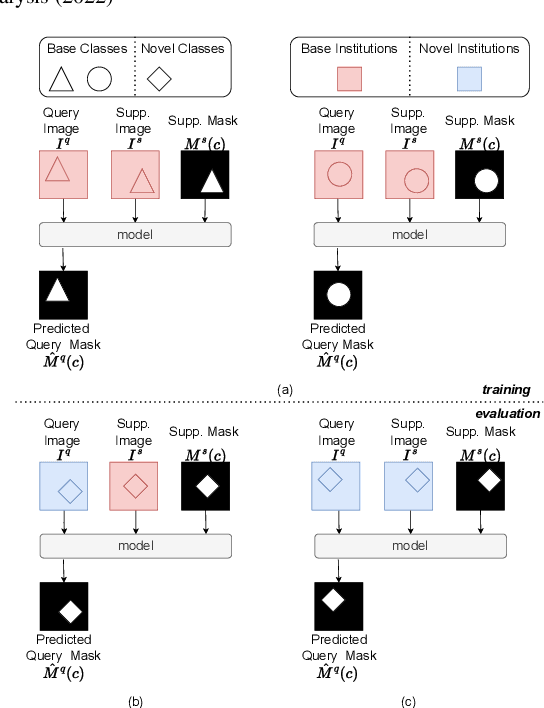

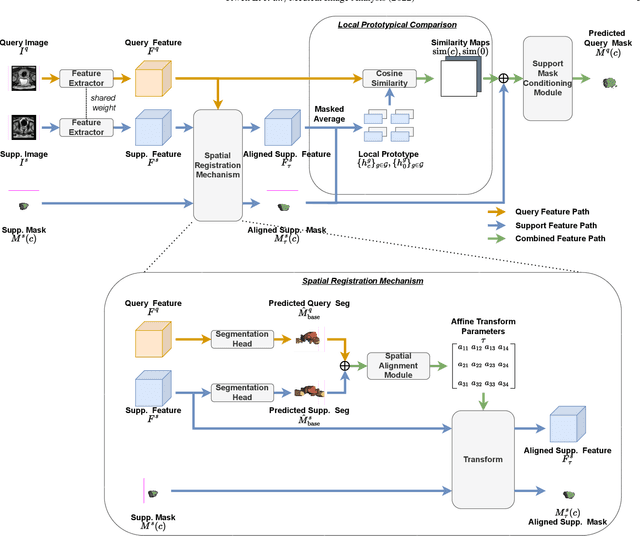

The prowess that makes few-shot learning desirable in medical image analysis is the efficient use of the support image data, which are labelled to classify or segment new classes, a task that otherwise requires substantially more training images and expert annotations. This work describes a fully 3D prototypical few-shot segmentation algorithm, such that the trained networks can be effectively adapted to clinically interesting structures that are absent in training, using only a few labelled images from a different institute. First, to compensate for the widely recognised spatial variability between institutions in episodic adaptation of novel classes, a novel spatial registration mechanism is integrated into prototypical learning, consisting of a segmentation head and an spatial alignment module. Second, to assist the training with observed imperfect alignment, support mask conditioning module is proposed to further utilise the annotation available from the support images. Extensive experiments are presented in an application of segmenting eight anatomical structures important for interventional planning, using a data set of 589 pelvic T2-weighted MR images, acquired at seven institutes. The results demonstrate the efficacy in each of the 3D formulation, the spatial registration, and the support mask conditioning, all of which made positive contributions independently or collectively. Compared with the previously proposed 2D alternatives, the few-shot segmentation performance was improved with statistical significance, regardless whether the support data come from the same or different institutes.
Anatomy-Aware Contrastive Representation Learning for Fetal Ultrasound
Aug 22, 2022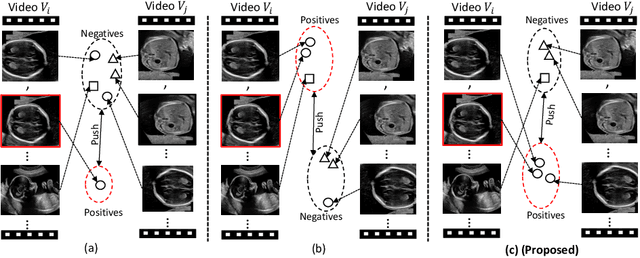

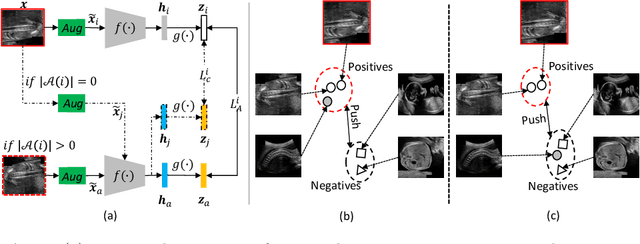
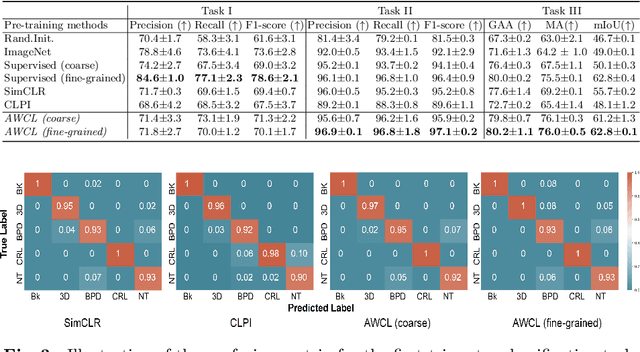
Self-supervised contrastive representation learning offers the advantage of learning meaningful visual representations from unlabeled medical datasets for transfer learning. However, applying current contrastive learning approaches to medical data without considering its domain-specific anatomical characteristics may lead to visual representations that are inconsistent in appearance and semantics. In this paper, we propose to improve visual representations of medical images via anatomy-aware contrastive learning (AWCL), which incorporates anatomy information to augment the positive/negative pair sampling in a contrastive learning manner. The proposed approach is demonstrated for automated fetal ultrasound imaging tasks, enabling the positive pairs from the same or different ultrasound scans that are anatomically similar to be pulled together and thus improving the representation learning. We empirically investigate the effect of inclusion of anatomy information with coarse- and fine-grained granularity, for contrastive learning and find that learning with fine-grained anatomy information which preserves intra-class difference is more effective than its counterpart. We also analyze the impact of anatomy ratio on our AWCL framework and find that using more distinct but anatomically similar samples to compose positive pairs results in better quality representations. Experiments on a large-scale fetal ultrasound dataset demonstrate that our approach is effective for learning representations that transfer well to three clinical downstream tasks, and achieves superior performance compared to ImageNet supervised and the current state-of-the-art contrastive learning methods. In particular, AWCL outperforms ImageNet supervised method by 13.8% and state-of-the-art contrastive-based method by 7.1% on a cross-domain segmentation task.
Multimodal-GuideNet: Gaze-Probe Bidirectional Guidance in Obstetric Ultrasound Scanning
Jul 26, 2022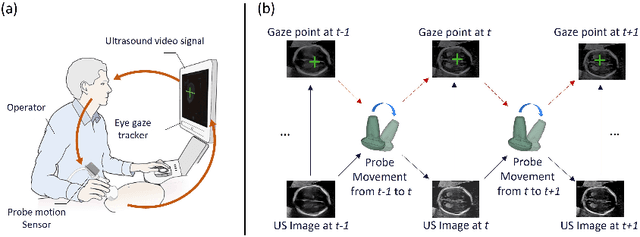
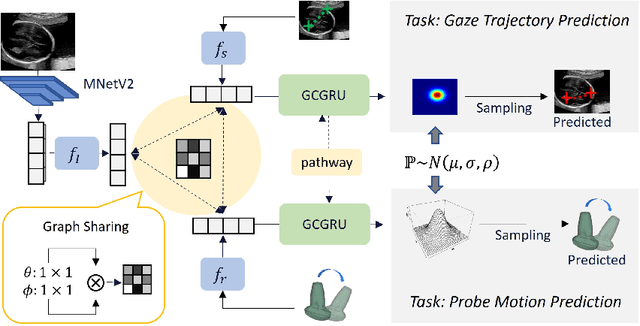
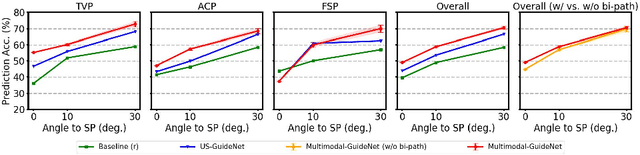
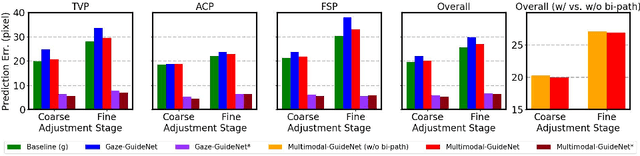
Eye trackers can provide visual guidance to sonographers during ultrasound (US) scanning. Such guidance is potentially valuable for less experienced operators to improve their scanning skills on how to manipulate the probe to achieve the desired plane. In this paper, a multimodal guidance approach (Multimodal-GuideNet) is proposed to capture the stepwise dependency between a real-world US video signal, synchronized gaze, and probe motion within a unified framework. To understand the causal relationship between gaze movement and probe motion, our model exploits multitask learning to jointly learn two related tasks: predicting gaze movements and probe signals that an experienced sonographer would perform in routine obstetric scanning. The two tasks are associated by a modality-aware spatial graph to detect the co-occurrence among the multi-modality inputs and share useful cross-modal information. Instead of a deterministic scanning path, Multimodal-GuideNet allows for scanning diversity by estimating the probability distribution of real scans. Experiments performed with three typical obstetric scanning examinations show that the new approach outperforms single-task learning for both probe motion guidance and gaze movement prediction. Multimodal-GuideNet also provides a visual guidance signal with an error rate of less than 10 pixels for a 224x288 US image.
Image quality assessment for machine learning tasks using meta-reinforcement learning
Mar 27, 2022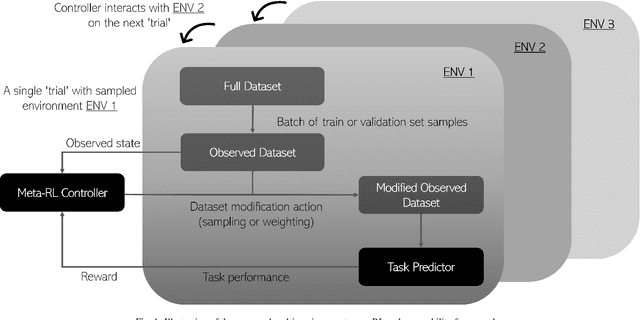
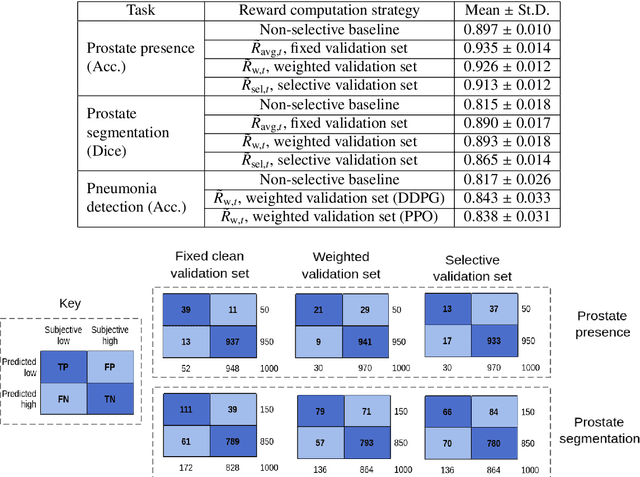
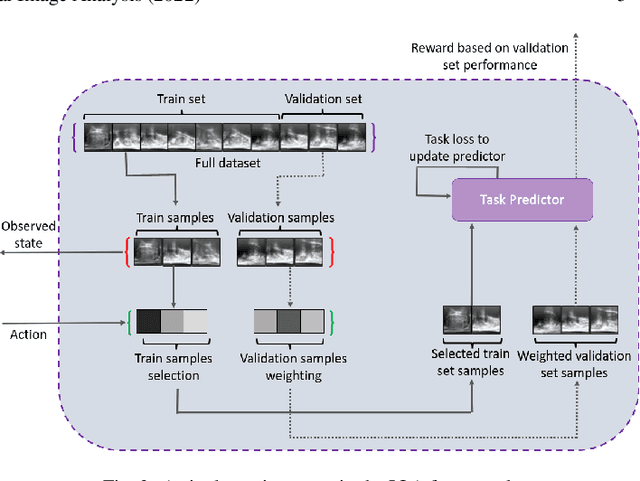
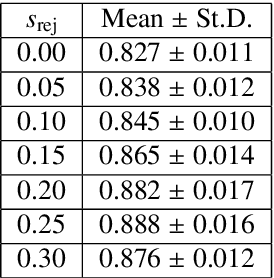
In this paper, we consider image quality assessment (IQA) as a measure of how images are amenable with respect to a given downstream task, or task amenability. When the task is performed using machine learning algorithms, such as a neural-network-based task predictor for image classification or segmentation, the performance of the task predictor provides an objective estimate of task amenability. In this work, we use an IQA controller to predict the task amenability which, itself being parameterised by neural networks, can be trained simultaneously with the task predictor. We further develop a meta-reinforcement learning framework to improve the adaptability for both IQA controllers and task predictors, such that they can be fine-tuned efficiently on new datasets or meta-tasks. We demonstrate the efficacy of the proposed task-specific, adaptable IQA approach, using two clinical applications for ultrasound-guided prostate intervention and pneumonia detection on X-ray images.
* Accepted to Medical Image Analysis; Final published version available at: https://doi.org/10.1016/j.media.2022.102427
Facial Anatomical Landmark Detection using Regularized Transfer Learning with Application to Fetal Alcohol Syndrome Recognition
Sep 12, 2021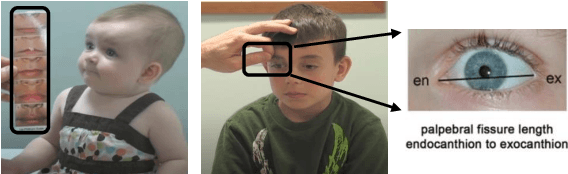
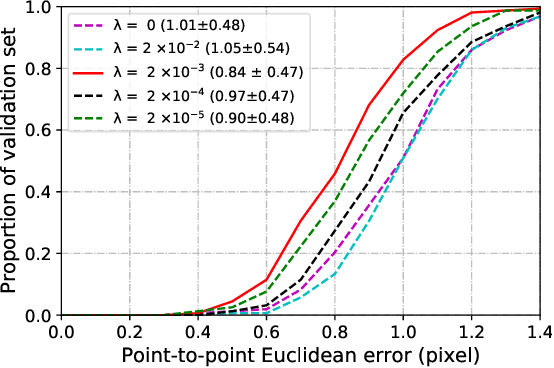
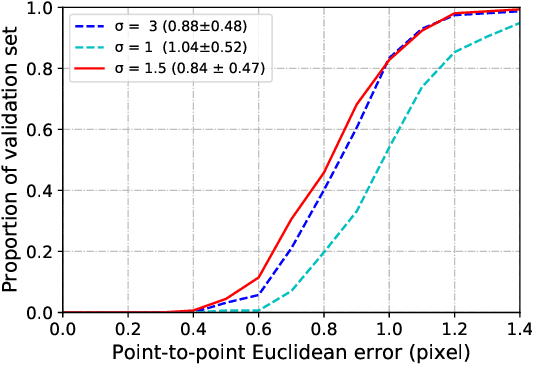
Fetal alcohol syndrome (FAS) caused by prenatal alcohol exposure can result in a series of cranio-facial anomalies, and behavioral and neurocognitive problems. Current diagnosis of FAS is typically done by identifying a set of facial characteristics, which are often obtained by manual examination. Anatomical landmark detection, which provides rich geometric information, is important to detect the presence of FAS associated facial anomalies. This imaging application is characterized by large variations in data appearance and limited availability of labeled data. Current deep learning-based heatmap regression methods designed for facial landmark detection in natural images assume availability of large datasets and are therefore not wellsuited for this application. To address this restriction, we develop a new regularized transfer learning approach that exploits the knowledge of a network learned on large facial recognition datasets. In contrast to standard transfer learning which focuses on adjusting the pre-trained weights, the proposed learning approach regularizes the model behavior. It explicitly reuses the rich visual semantics of a domain-similar source model on the target task data as an additional supervisory signal for regularizing landmark detection optimization. Specifically, we develop four regularization constraints for the proposed transfer learning, including constraining the feature outputs from classification and intermediate layers, as well as matching activation attention maps in both spatial and channel levels. Experimental evaluation on a collected clinical imaging dataset demonstrate that the proposed approach can effectively improve model generalizability under limited training samples, and is advantageous to other approaches in the literature.
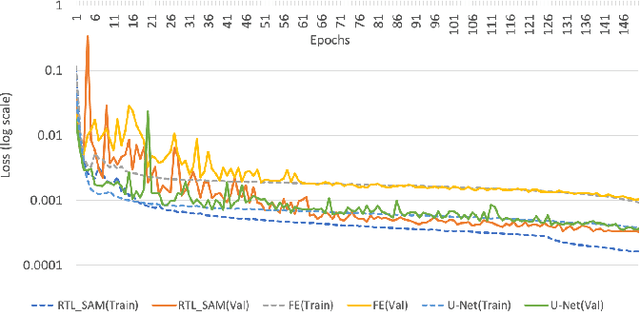
Adaptable image quality assessment using meta-reinforcement learning of task amenability
Jul 31, 2021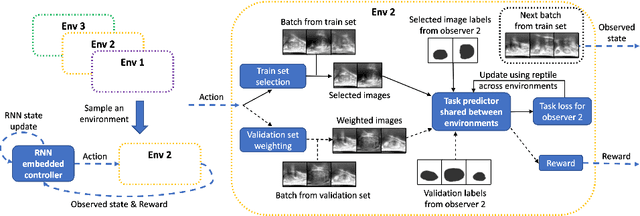
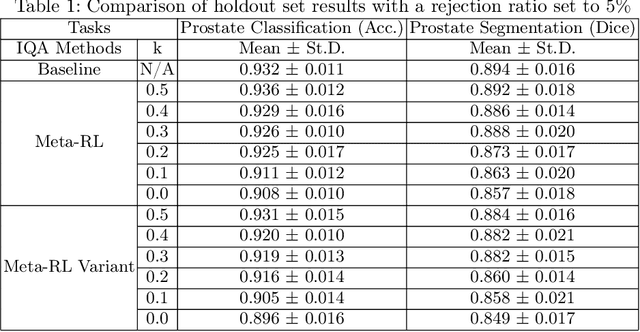
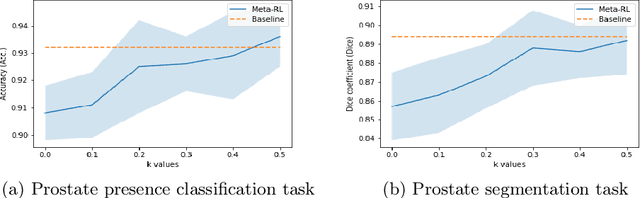
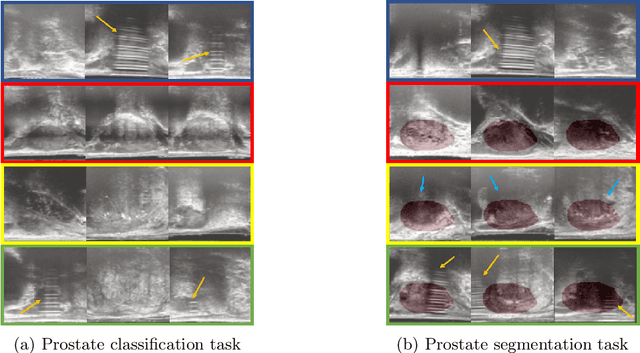
The performance of many medical image analysis tasks are strongly associated with image data quality. When developing modern deep learning algorithms, rather than relying on subjective (human-based) image quality assessment (IQA), task amenability potentially provides an objective measure of task-specific image quality. To predict task amenability, an IQA agent is trained using reinforcement learning (RL) with a simultaneously optimised task predictor, such as a classification or segmentation neural network. In this work, we develop transfer learning or adaptation strategies to increase the adaptability of both the IQA agent and the task predictor so that they are less dependent on high-quality, expert-labelled training data. The proposed transfer learning strategy re-formulates the original RL problem for task amenability in a meta-reinforcement learning (meta-RL) framework. The resulting algorithm facilitates efficient adaptation of the agent to different definitions of image quality, each with its own Markov decision process environment including different images, labels and an adaptable task predictor. Our work demonstrates that the IQA agents pre-trained on non-expert task labels can be adapted to predict task amenability as defined by expert task labels, using only a small set of expert labels. Using 6644 clinical ultrasound images from 249 prostate cancer patients, our results for image classification and segmentation tasks show that the proposed IQA method can be adapted using data with as few as respective 19.7% and 29.6% expert-reviewed consensus labels and still achieve comparable IQA and task performance, which would otherwise require a training dataset with 100% expert labels.