 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOXSeg: Multidimensional attention UNet-based lip segmentation using semi-supervised lip contours
May 08, 2025



Lip segmentation plays a crucial role in various domains, such as lip synchronization, lipreading, and diagnostics. However, the effectiveness of supervised lip segmentation is constrained by the availability of lip contour in the training phase. A further challenge with lip segmentation is its reliance on image quality , lighting, and skin tone, leading to inaccuracies in the detected boundaries. To address these challenges, we propose a sequential lip segmentation method that integrates attention UNet and multidimensional input. We unravel the micro-patterns in facial images using local binary patterns to build multidimensional inputs. Subsequently, the multidimensional inputs are fed into sequential attention UNets, where the lip contour is reconstructed. We introduce a mask generation method that uses a few anatomical landmarks and estimates the complete lip contour to improve segmentation accuracy. This mask has been utilized in the training phase for lip segmentation. To evaluate the proposed method, we use facial images to segment the upper lips and subsequently assess lip-related facial anomalies in subjects with fetal alcohol syndrome (FAS). Using the proposed lip segmentation method, we achieved a mean dice score of 84.75%, and a mean pixel accuracy of 99.77% in upper lip segmentation. To further evaluate the method, we implemented classifiers to identify those with FAS. Using a generative adversarial network (GAN), we reached an accuracy of 98.55% in identifying FAS in one of the study populations. This method could be used to improve lip segmentation accuracy, especially around Cupid's bow, and shed light on distinct lip-related characteristics of FAS.
Facial Anatomical Landmark Detection using Regularized Transfer Learning with Application to Fetal Alcohol Syndrome Recognition
Sep 12, 2021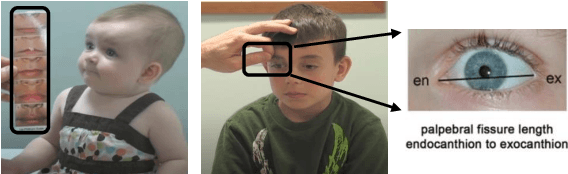
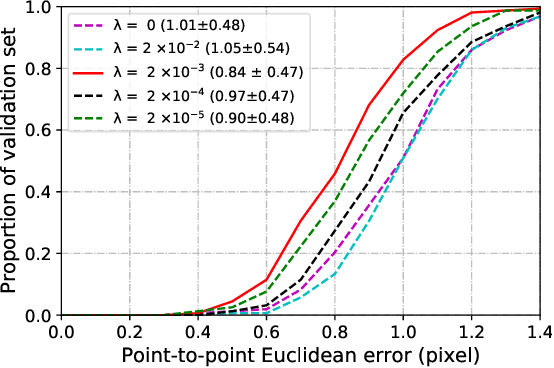
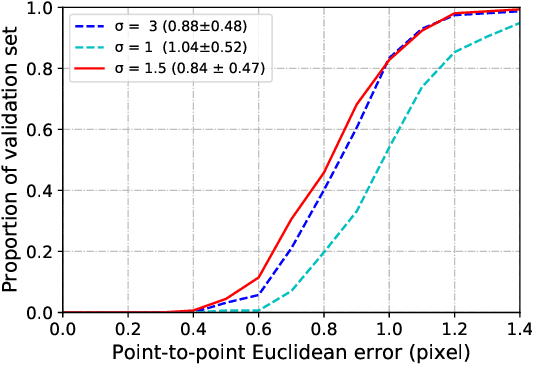
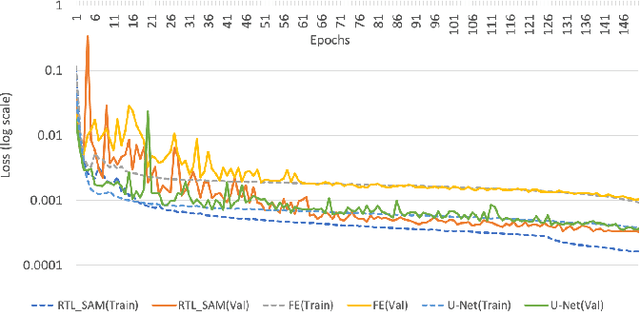
Fetal alcohol syndrome (FAS) caused by prenatal alcohol exposure can result in a series of cranio-facial anomalies, and behavioral and neurocognitive problems. Current diagnosis of FAS is typically done by identifying a set of facial characteristics, which are often obtained by manual examination. Anatomical landmark detection, which provides rich geometric information, is important to detect the presence of FAS associated facial anomalies. This imaging application is characterized by large variations in data appearance and limited availability of labeled data. Current deep learning-based heatmap regression methods designed for facial landmark detection in natural images assume availability of large datasets and are therefore not wellsuited for this application. To address this restriction, we develop a new regularized transfer learning approach that exploits the knowledge of a network learned on large facial recognition datasets. In contrast to standard transfer learning which focuses on adjusting the pre-trained weights, the proposed learning approach regularizes the model behavior. It explicitly reuses the rich visual semantics of a domain-similar source model on the target task data as an additional supervisory signal for regularizing landmark detection optimization. Specifically, we develop four regularization constraints for the proposed transfer learning, including constraining the feature outputs from classification and intermediate layers, as well as matching activation attention maps in both spatial and channel levels. Experimental evaluation on a collected clinical imaging dataset demonstrate that the proposed approach can effectively improve model generalizability under limited training samples, and is advantageous to other approaches in the literature.
Cross-Task Representation Learning for Anatomical Landmark Detection
Sep 28, 2020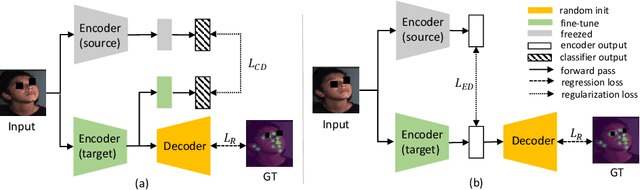


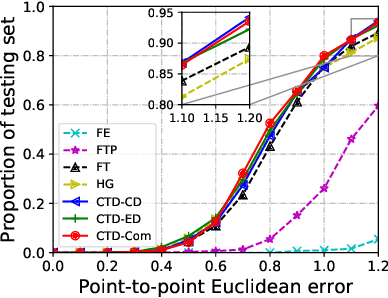
Recently, there is an increasing demand for automatically detecting anatomical landmarks which provide rich structural information to facilitate subsequent medical image analysis. Current methods related to this task often leverage the power of deep neural networks, while a major challenge in fine tuning such models in medical applications arises from insufficient number of labeled samples. To address this, we propose to regularize the knowledge transfer across source and target tasks through cross-task representation learning. The proposed method is demonstrated for extracting facial anatomical landmarks which facilitate the diagnosis of fetal alcohol syndrome. The source and target tasks in this work are face recognition and landmark detection, respectively. The main idea of the proposed method is to retain the feature representations of the source model on the target task data, and to leverage them as an additional source of supervisory signals for regularizing the target model learning, thereby improving its performance under limited training samples. Concretely, we present two approaches for the proposed representation learning by constraining either final or intermediate model features on the target model. Experimental results on a clinical face image dataset demonstrate that the proposed approach works well with few labeled data, and outperforms other compared approaches.