 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Dresden Dataset for 4D Reconstruction of Non-Rigid Abdominal Surgical Scenes
Mar 03, 2026The D4D Dataset provides paired endoscopic video and high-quality structured-light geometry for evaluating 3D reconstruction of deforming abdominal soft tissue in realistic surgical conditions. Data were acquired from six porcine cadaver sessions using a da Vinci Xi stereo endoscope and a Zivid structured-light camera, registered via optical tracking and manually curated iterative alignment methods. Three sequence types - whole deformations, incremental deformations, and moved-camera clips - probe algorithm robustness to non-rigid motion, deformation magnitude, and out-of-view updates. Each clip provides rectified stereo images, per-frame instrument masks, stereo depth, start/end structured-light point clouds, curated camera poses and camera intrinsics. In postprocessing, ICP and semi-automatic registration techniques are used to register data, and instrument masks are created. The dataset enables quantitative geometric evaluation in both visible and occluded regions, alongside photometric view-synthesis baselines. Comprising over 300,000 frames and 369 point clouds across 98 curated recordings, this resource can serve as a comprehensive benchmark for developing and evaluating non-rigid SLAM, 4D reconstruction, and depth estimation methods.
Long-Term Temporally Consistent Unpaired Video Translation from Simulated Surgical 3D Data
Mar 31, 2021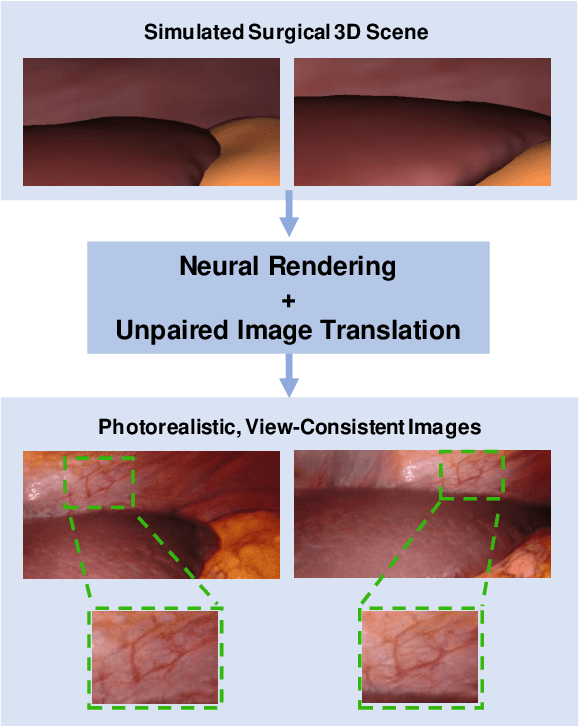
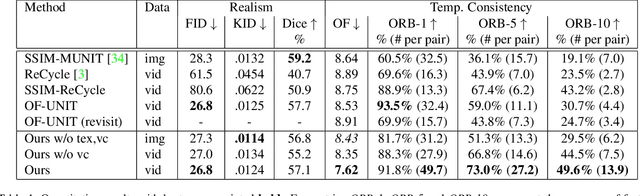
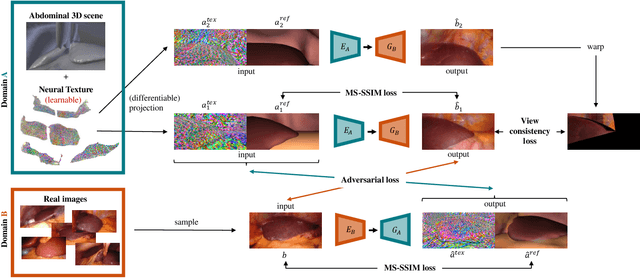
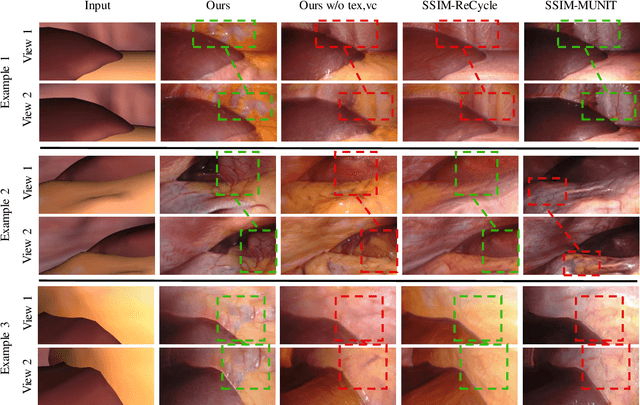
Research in unpaired video translation has mainly focused on short-term temporal consistency by conditioning on neighboring frames. However for transfer from simulated to photorealistic sequences, available information on the underlying geometry offers potential for achieving global consistency across views. We propose a novel approach which combines unpaired image translation with neural rendering to transfer simulated to photorealistic surgical abdominal scenes. By introducing global learnable textures and a lighting-invariant view-consistency loss, our method produces consistent translations of arbitrary views and thus enables long-term consistent video synthesis. We design and test our model to generate video sequences from minimally-invasive surgical abdominal scenes. Because labeled data is often limited in this domain, photorealistic data where ground truth information from the simulated domain is preserved is especially relevant. By extending existing image-based methods to view-consistent videos, we aim to impact the applicability of simulated training and evaluation environments for surgical applications. Code and data will be made publicly available soon.