 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Impact of Depth and Width on Transformer Language Model Generalization
Oct 30, 2023



To process novel sentences, language models (LMs) must generalize compositionally -- combine familiar elements in new ways. What aspects of a model's structure promote compositional generalization? Focusing on transformers, we test the hypothesis, motivated by recent theoretical and empirical work, that transformers generalize more compositionally when they are deeper (have more layers). Because simply adding layers increases the total number of parameters, confounding depth and size, we construct three classes of models which trade off depth for width such that the total number of parameters is kept constant (41M, 134M and 374M parameters). We pretrain all models as LMs and fine-tune them on tasks that test for compositional generalization. We report three main conclusions: (1) after fine-tuning, deeper models generalize better out-of-distribution than shallower models do, but the relative benefit of additional layers diminishes rapidly; (2) within each family, deeper models show better language modeling performance, but returns are similarly diminishing; (3) the benefits of depth for compositional generalization cannot be attributed solely to better performance on language modeling or on in-distribution data.
Hierarchical reinforcement learning with natural language subgoals
Sep 20, 2023



Hierarchical reinforcement learning has been a compelling approach for achieving goal directed behavior over long sequences of actions. However, it has been challenging to implement in realistic or open-ended environments. A main challenge has been to find the right space of sub-goals over which to instantiate a hierarchy. We present a novel approach where we use data from humans solving these tasks to softly supervise the goal space for a set of long range tasks in a 3D embodied environment. In particular, we use unconstrained natural language to parameterize this space. This has two advantages: first, it is easy to generate this data from naive human participants; second, it is flexible enough to represent a vast range of sub-goals in human-relevant tasks. Our approach outperforms agents that clone expert behavior on these tasks, as well as HRL from scratch without this supervised sub-goal space. Our work presents a novel approach to combining human expert supervision with the benefits and flexibility of reinforcement learning.
Large Content And Behavior Models To Understand, Simulate, And Optimize Content And Behavior
Sep 08, 2023



Shannon, in his seminal paper introducing information theory, divided the communication into three levels: technical, semantic, and effectivenss. While the technical level is concerned with accurate reconstruction of transmitted symbols, the semantic and effectiveness levels deal with the inferred meaning and its effect on the receiver. Thanks to telecommunications, the first level problem has produced great advances like the internet. Large Language Models (LLMs) make some progress towards the second goal, but the third level still remains largely untouched. The third problem deals with predicting and optimizing communication for desired receiver behavior. LLMs, while showing wide generalization capabilities across a wide range of tasks, are unable to solve for this. One reason for the underperformance could be a lack of "behavior tokens" in LLMs' training corpora. Behavior tokens define receiver behavior over a communication, such as shares, likes, clicks, purchases, retweets, etc. While preprocessing data for LLM training, behavior tokens are often removed from the corpora as noise. Therefore, in this paper, we make some initial progress towards reintroducing behavior tokens in LLM training. The trained models, other than showing similar performance to LLMs on content understanding tasks, show generalization capabilities on behavior simulation, content simulation, behavior understanding, and behavior domain adaptation. Using a wide range of tasks on two corpora, we show results on all these capabilities. We call these models Large Content and Behavior Models (LCBMs). Further, to spur more research on LCBMs, we release our new Content Behavior Corpus (CBC), a repository containing communicator, message, and corresponding receiver behavior.
Passive learning of active causal strategies in agents and language models
May 25, 2023



What can be learned about causality and experimentation from passive data? This question is salient given recent successes of passively-trained language models in interactive domains such as tool use. Passive learning is inherently limited. However, we show that purely passive learning can in fact allow an agent to learn generalizable strategies for determining and using causal structures, as long as the agent can intervene at test time. We formally illustrate that learning a strategy of first experimenting, then seeking goals, can allow generalization from passive learning in principle. We then show empirically that agents trained via imitation on expert data can indeed generalize at test time to infer and use causal links which are never present in the training data; these agents can also generalize experimentation strategies to novel variable sets never observed in training. We then show that strategies for causal intervention and exploitation can be generalized from passive data even in a more complex environment with high-dimensional observations, with the support of natural language explanations. Explanations can even allow passive learners to generalize out-of-distribution from perfectly-confounded training data. Finally, we show that language models, trained only on passive next-word prediction, can generalize causal intervention strategies from a few-shot prompt containing examples of experimentation, together with explanations and reasoning. These results highlight the surprising power of passive learning of active causal strategies, and may help to understand the behaviors and capabilities of language models.
Meta-Learned Models of Cognition
Apr 12, 2023Meta-learning is a framework for learning learning algorithms through repeated interactions with an environment as opposed to designing them by hand. In recent years, this framework has established itself as a promising tool for building models of human cognition. Yet, a coherent research program around meta-learned models of cognition is still missing. The purpose of this article is to synthesize previous work in this field and establish such a research program. We rely on three key pillars to accomplish this goal. We first point out that meta-learning can be used to construct Bayes-optimal learning algorithms. This result not only implies that any behavioral phenomenon that can be explained by a Bayesian model can also be explained by a meta-learned model but also allows us to draw strong connections to the rational analysis of cognition. We then discuss several advantages of the meta-learning framework over traditional Bayesian methods. In particular, we argue that meta-learning can be applied to situations where Bayesian inference is impossible and that it enables us to make rational models of cognition more realistic, either by incorporating limited computational resources or neuroscientific knowledge. Finally, we reexamine prior studies from psychology and neuroscience that have applied meta-learning and put them into the context of these new insights. In summary, our work highlights that meta-learning considerably extends the scope of rational analysis and thereby of cognitive theories more generally.
Collaborating with language models for embodied reasoning
Feb 01, 2023Reasoning in a complex and ambiguous environment is a key goal for Reinforcement Learning (RL) agents. While some sophisticated RL agents can successfully solve difficult tasks, they require a large amount of training data and often struggle to generalize to new unseen environments and new tasks. On the other hand, Large Scale Language Models (LSLMs) have exhibited strong reasoning ability and the ability to to adapt to new tasks through in-context learning. However, LSLMs do not inherently have the ability to interrogate or intervene on the environment. In this work, we investigate how to combine these complementary abilities in a single system consisting of three parts: a Planner, an Actor, and a Reporter. The Planner is a pre-trained language model that can issue commands to a simple embodied agent (the Actor), while the Reporter communicates with the Planner to inform its next command. We present a set of tasks that require reasoning, test this system's ability to generalize zero-shot and investigate failure cases, and demonstrate how components of this system can be trained with reinforcement-learning to improve performance.
Distilling Internet-Scale Vision-Language Models into Embodied Agents
Jan 29, 2023



Instruction-following agents must ground language into their observation and action spaces. Learning to ground language is challenging, typically requiring domain-specific engineering or large quantities of human interaction data. To address this challenge, we propose using pretrained vision-language models (VLMs) to supervise embodied agents. We combine ideas from model distillation and hindsight experience replay (HER), using a VLM to retroactively generate language describing the agent's behavior. Simple prompting allows us to control the supervision signal, teaching an agent to interact with novel objects based on their names (e.g., planes) or their features (e.g., colors) in a 3D rendered environment. Fewshot prompting lets us teach abstract category membership, including pre-existing categories (food vs toys) and ad-hoc ones (arbitrary preferences over objects). Our work outlines a new and effective way to use internet-scale VLMs, repurposing the generic language grounding acquired by such models to teach task-relevant groundings to embodied agents.
Learning to Navigate Wikipedia by Taking Random Walks
Oct 31, 2022A fundamental ability of an intelligent web-based agent is seeking out and acquiring new information. Internet search engines reliably find the correct vicinity but the top results may be a few links away from the desired target. A complementary approach is navigation via hyperlinks, employing a policy that comprehends local content and selects a link that moves it closer to the target. In this paper, we show that behavioral cloning of randomly sampled trajectories is sufficient to learn an effective link selection policy. We demonstrate the approach on a graph version of Wikipedia with 38M nodes and 387M edges. The model is able to efficiently navigate between nodes 5 and 20 steps apart 96% and 92% of the time, respectively. We then use the resulting embeddings and policy in downstream fact verification and question answering tasks where, in combination with basic TF-IDF search and ranking methods, they are competitive results to the state-of-the-art methods.
Transformers generalize differently from information stored in context vs in weights
Oct 11, 2022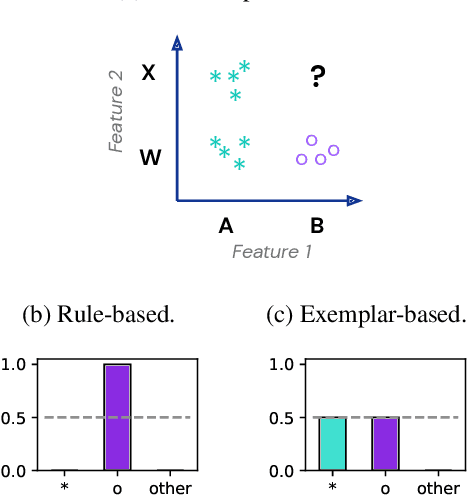
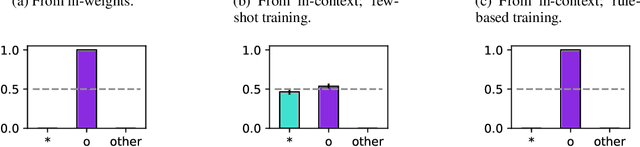
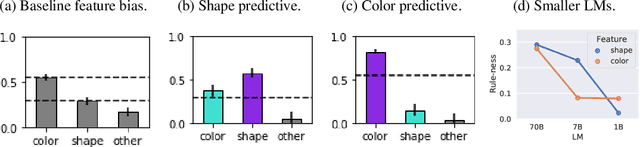
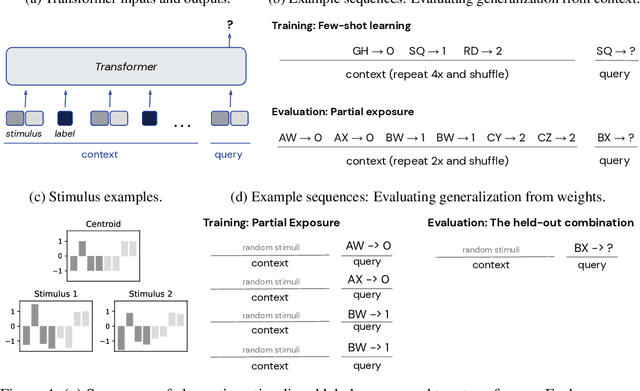
Transformer models can use two fundamentally different kinds of information: information stored in weights during training, and information provided ``in-context'' at inference time. In this work, we show that transformers exhibit different inductive biases in how they represent and generalize from the information in these two sources. In particular, we characterize whether they generalize via parsimonious rules (rule-based generalization) or via direct comparison with observed examples (exemplar-based generalization). This is of important practical consequence, as it informs whether to encode information in weights or in context, depending on how we want models to use that information. In transformers trained on controlled stimuli, we find that generalization from weights is more rule-based whereas generalization from context is largely exemplar-based. In contrast, we find that in transformers pre-trained on natural language, in-context learning is significantly rule-based, with larger models showing more rule-basedness. We hypothesise that rule-based generalization from in-context information might be an emergent consequence of large-scale training on language, which has sparse rule-like structure. Using controlled stimuli, we verify that transformers pretrained on data containing sparse rule-like structure exhibit more rule-based generalization.
Language models show human-like content effects on reasoning
Jul 14, 2022



Abstract reasoning is a key ability for an intelligent system. Large language models achieve above-chance performance on abstract reasoning tasks, but exhibit many imperfections. However, human abstract reasoning is also imperfect, and depends on our knowledge and beliefs about the content of the reasoning problem. For example, humans reason much more reliably about logical rules that are grounded in everyday situations than arbitrary rules about abstract attributes. The training experiences of language models similarly endow them with prior expectations that reflect human knowledge and beliefs. We therefore hypothesized that language models would show human-like content effects on abstract reasoning problems. We explored this hypothesis across three logical reasoning tasks: natural language inference, judging the logical validity of syllogisms, and the Wason selection task (Wason, 1968). We find that state of the art large language models (with 7 or 70 billion parameters; Hoffman et al., 2022) reflect many of the same patterns observed in humans across these tasks -- like humans, models reason more effectively about believable situations than unrealistic or abstract ones. Our findings have implications for understanding both these cognitive effects, and the factors that contribute to language model performance.