 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision Models Are More Robust And Fair When Pretrained On Uncurated Images Without Supervision
Feb 22, 2022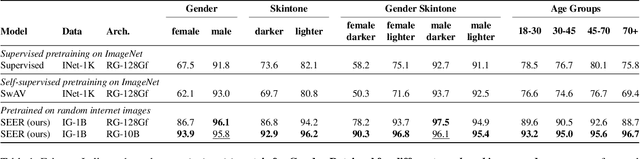
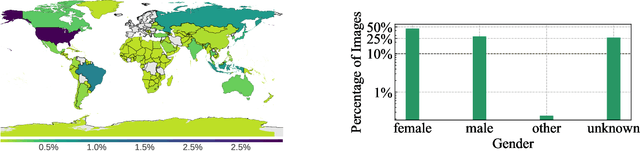
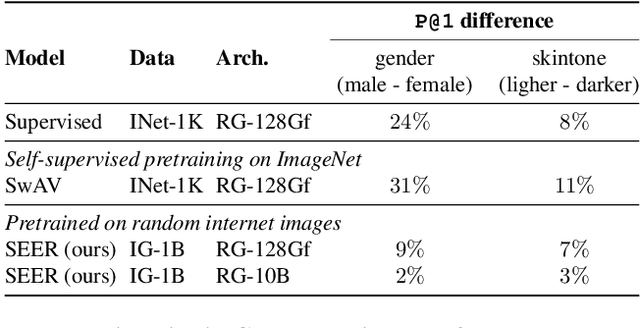
Discriminative self-supervised learning allows training models on any random group of internet images, and possibly recover salient information that helps differentiate between the images. Applied to ImageNet, this leads to object centric features that perform on par with supervised features on most object-centric downstream tasks. In this work, we question if using this ability, we can learn any salient and more representative information present in diverse unbounded set of images from across the globe. To do so, we train models on billions of random images without any data pre-processing or prior assumptions about what we want the model to learn. We scale our model size to dense 10 billion parameters to avoid underfitting on a large data size. We extensively study and validate our model performance on over 50 benchmarks including fairness, robustness to distribution shift, geographical diversity, fine grained recognition, image copy detection and many image classification datasets. The resulting model, not only captures well semantic information, it also captures information about artistic style and learns salient information such as geolocations and multilingual word embeddings based on visual content only. More importantly, we discover that such model is more robust, more fair, less harmful and less biased than supervised models or models trained on object centric datasets such as ImageNet.
A Data-Augmentation Is Worth A Thousand Samples: Exact Quantification From Analytical Augmented Sample Moments
Feb 16, 2022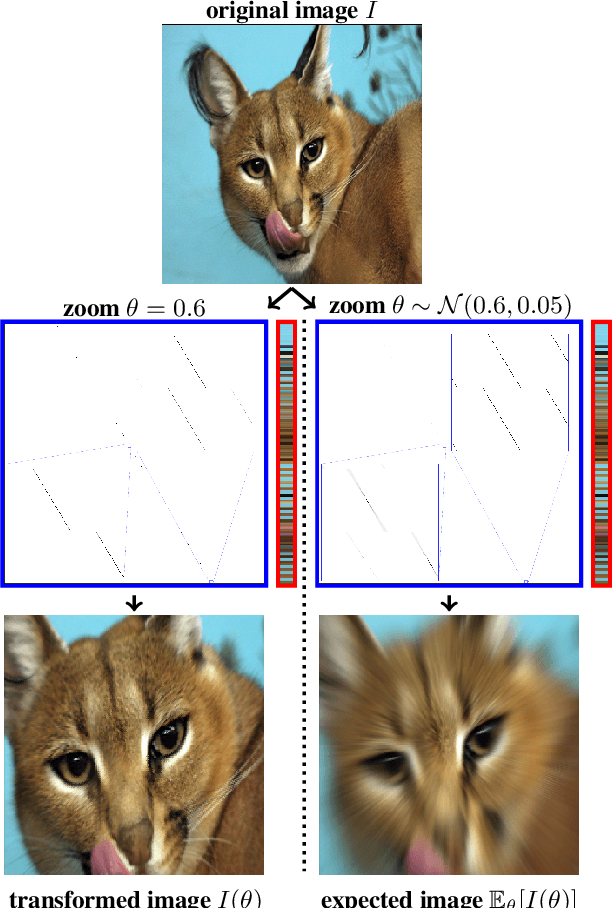
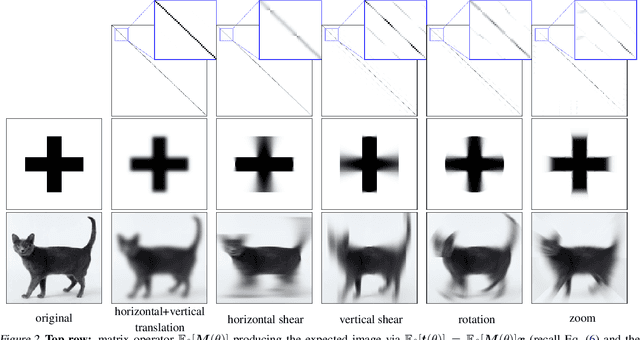
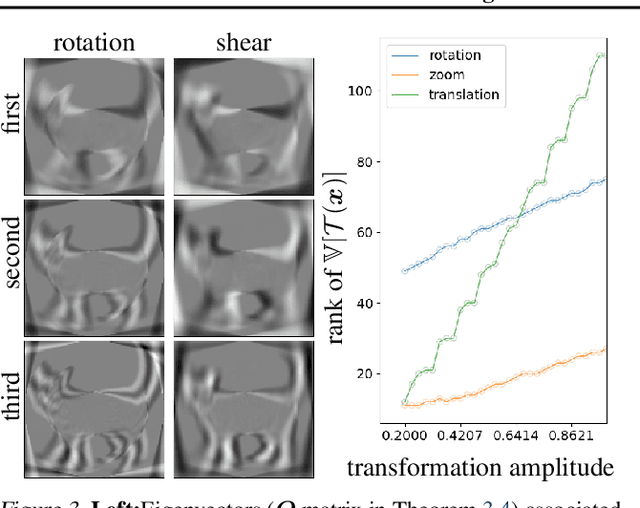
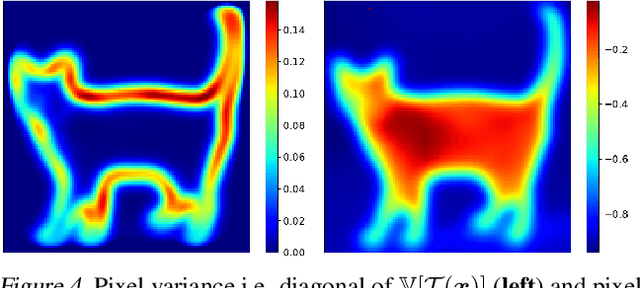
Data-Augmentation (DA) is known to improve performance across tasks and datasets. We propose a method to theoretically analyze the effect of DA and study questions such as: how many augmented samples are needed to correctly estimate the information encoded by that DA? How does the augmentation policy impact the final parameters of a model? We derive several quantities in close-form, such as the expectation and variance of an image, loss, and model's output under a given DA distribution. Those derivations open new avenues to quantify the benefits and limitations of DA. For example, we show that common DAs require tens of thousands of samples for the loss at hand to be correctly estimated and for the model training to converge. We show that for a training loss to be stable under DA sampling, the model's saliency map (gradient of the loss with respect to the model's input) must align with the smallest eigenvector of the sample variance under the considered DA augmentation, hinting at a possible explanation on why models tend to shift their focus from edges to textures.
Omnivore: A Single Model for Many Visual Modalities
Jan 20, 2022
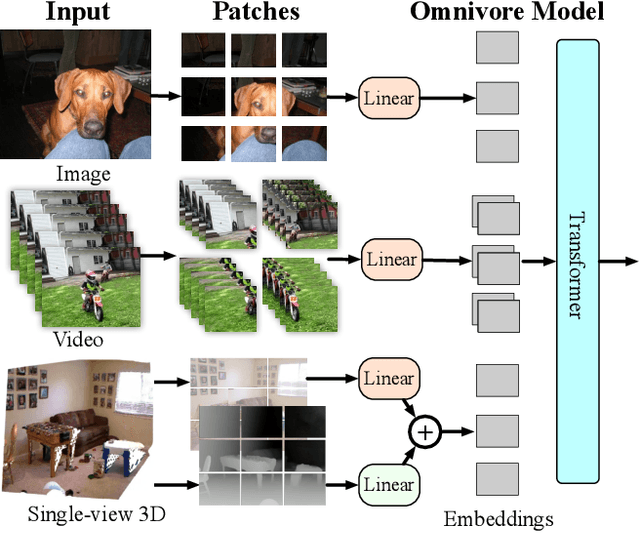
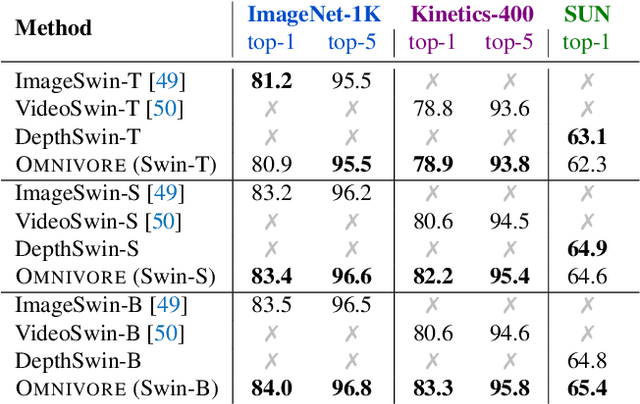
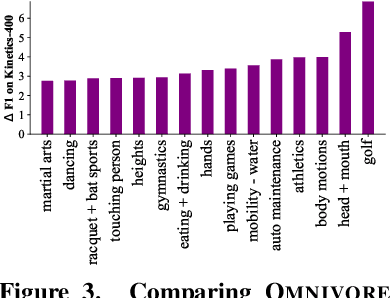
Prior work has studied different visual modalities in isolation and developed separate architectures for recognition of images, videos, and 3D data. Instead, in this paper, we propose a single model which excels at classifying images, videos, and single-view 3D data using exactly the same model parameters. Our 'Omnivore' model leverages the flexibility of transformer-based architectures and is trained jointly on classification tasks from different modalities. Omnivore is simple to train, uses off-the-shelf standard datasets, and performs at-par or better than modality-specific models of the same size. A single Omnivore model obtains 86.0% on ImageNet, 84.1% on Kinetics, and 67.1% on SUN RGB-D. After finetuning, our models outperform prior work on a variety of vision tasks and generalize across modalities. Omnivore's shared visual representation naturally enables cross-modal recognition without access to correspondences between modalities. We hope our results motivate researchers to model visual modalities together.
Detecting Twenty-thousand Classes using Image-level Supervision
Jan 10, 2022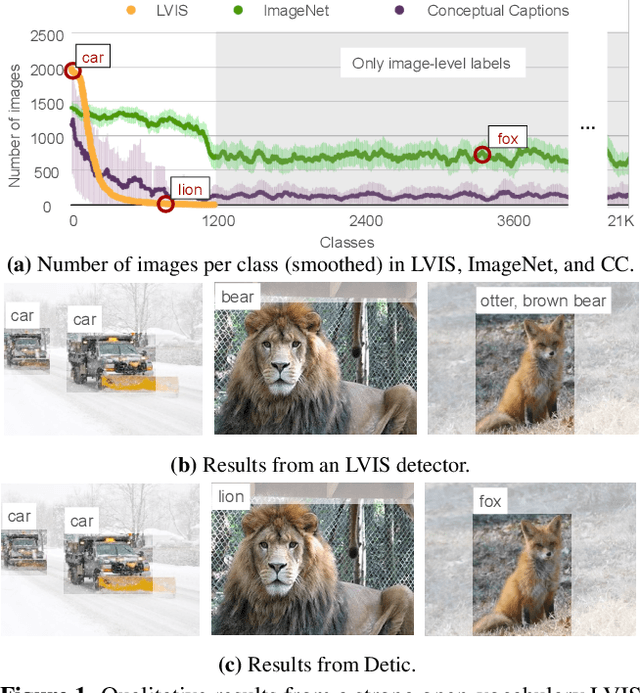
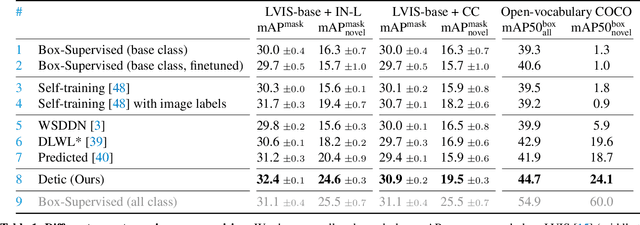


Current object detectors are limited in vocabulary size due to the small scale of detection datasets. Image classifiers, on the other hand, reason about much larger vocabularies, as their datasets are larger and easier to collect. We propose Detic, which simply trains the classifiers of a detector on image classification data and thus expands the vocabulary of detectors to tens of thousands of concepts. Unlike prior work, Detic does not assign image labels to boxes based on model predictions, making it much easier to implement and compatible with a range of detection architectures and backbones. Our results show that Detic yields excellent detectors even for classes without box annotations. It outperforms prior work on both open-vocabulary and long-tail detection benchmarks. Detic provides a gain of 2.4 mAP for all classes and 8.3 mAP for novel classes on the open-vocabulary LVIS benchmark. On the standard LVIS benchmark, Detic reaches 41.7 mAP for all classes and 41.7 mAP for rare classes. For the first time, we train a detector with all the twenty-one-thousand classes of the ImageNet dataset and show that it generalizes to new datasets without fine-tuning. Code is available at https://github.com/facebookresearch/Detic.
Mask2Former for Video Instance Segmentation
Dec 20, 2021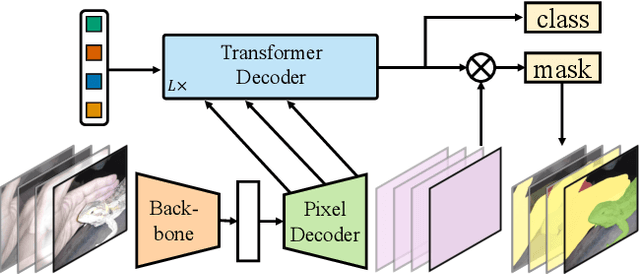
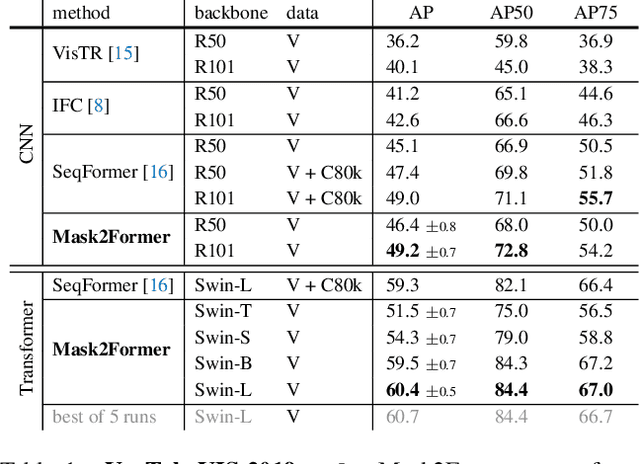
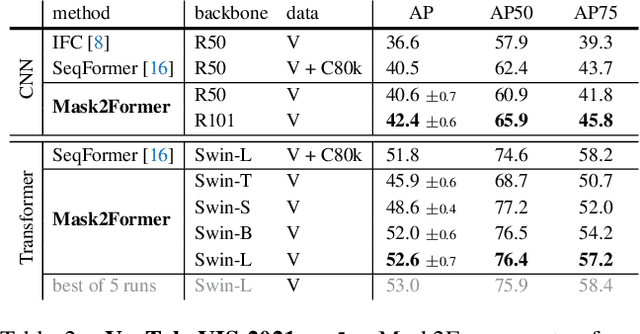
We find Mask2Former also achieves state-of-the-art performance on video instance segmentation without modifying the architecture, the loss or even the training pipeline. In this report, we show universal image segmentation architectures trivially generalize to video segmentation by directly predicting 3D segmentation volumes. Specifically, Mask2Former sets a new state-of-the-art of 60.4 AP on YouTubeVIS-2019 and 52.6 AP on YouTubeVIS-2021. We believe Mask2Former is also capable of handling video semantic and panoptic segmentation, given its versatility in image segmentation. We hope this will make state-of-the-art video segmentation research more accessible and bring more attention to designing universal image and video segmentation architectures.
Masked-attention Mask Transformer for Universal Image Segmentation
Dec 10, 2021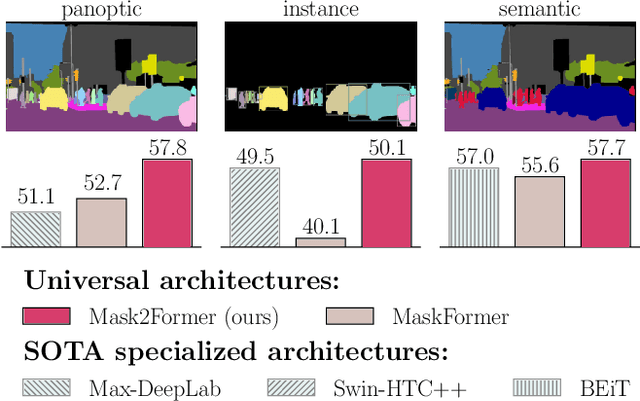
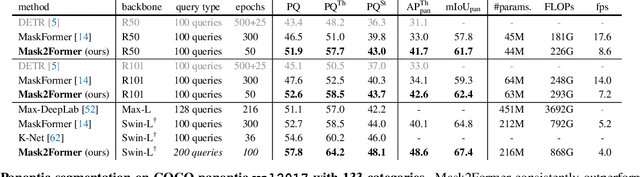
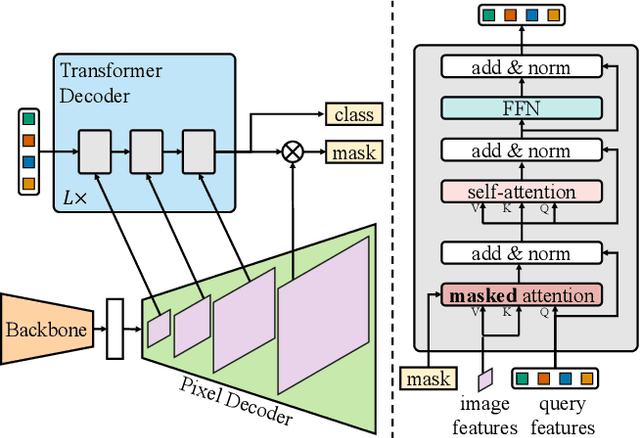
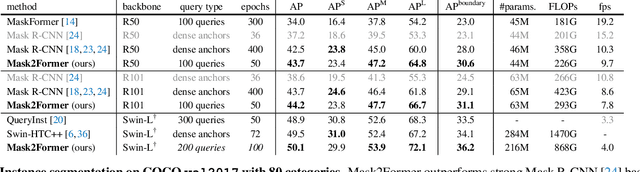
Image segmentation is about grouping pixels with different semantics, e.g., category or instance membership, where each choice of semantics defines a task. While only the semantics of each task differ, current research focuses on designing specialized architectures for each task. We present Masked-attention Mask Transformer (Mask2Former), a new architecture capable of addressing any image segmentation task (panoptic, instance or semantic). Its key components include masked attention, which extracts localized features by constraining cross-attention within predicted mask regions. In addition to reducing the research effort by at least three times, it outperforms the best specialized architectures by a significant margin on four popular datasets. Most notably, Mask2Former sets a new state-of-the-art for panoptic segmentation (57.8 PQ on COCO), instance segmentation (50.1 AP on COCO) and semantic segmentation (57.7 mIoU on ADE20K).
Frame Averaging for Invariant and Equivariant Network Design
Oct 07, 2021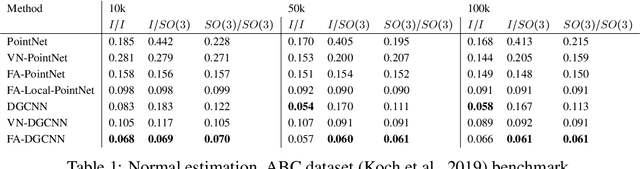
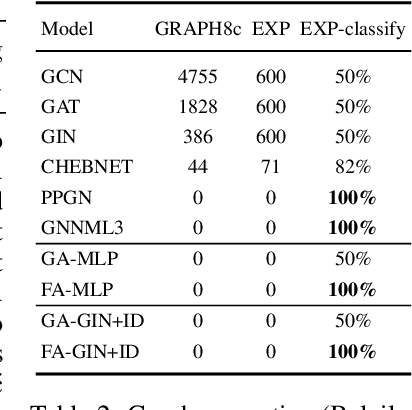
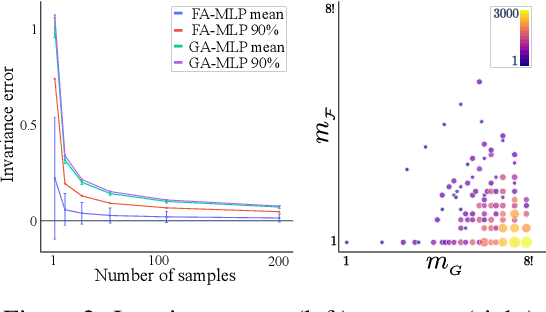
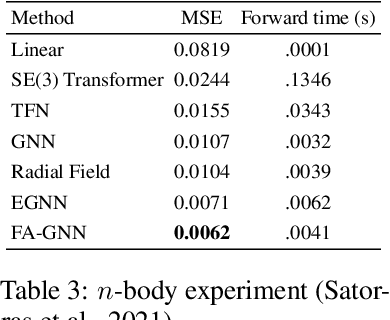
Many machine learning tasks involve learning functions that are known to be invariant or equivariant to certain symmetries of the input data. However, it is often challenging to design neural network architectures that respect these symmetries while being expressive and computationally efficient. For example, Euclidean motion invariant/equivariant graph or point cloud neural networks. We introduce Frame Averaging (FA), a general purpose and systematic framework for adapting known (backbone) architectures to become invariant or equivariant to new symmetry types. Our framework builds on the well known group averaging operator that guarantees invariance or equivariance but is intractable. In contrast, we observe that for many important classes of symmetries, this operator can be replaced with an averaging operator over a small subset of the group elements, called a frame. We show that averaging over a frame guarantees exact invariance or equivariance while often being much simpler to compute than averaging over the entire group. Furthermore, we prove that FA-based models have maximal expressive power in a broad setting and in general preserve the expressive power of their backbone architectures. Using frame averaging, we propose a new class of universal Graph Neural Networks (GNNs), universal Euclidean motion invariant point cloud networks, and Euclidean motion invariant Message Passing (MP) GNNs. We demonstrate the practical effectiveness of FA on several applications including point cloud normal estimation, beyond $2$-WL graph separation, and $n$-body dynamics prediction, achieving state-of-the-art results in all of these benchmarks.
An End-to-End Transformer Model for 3D Object Detection
Sep 16, 2021
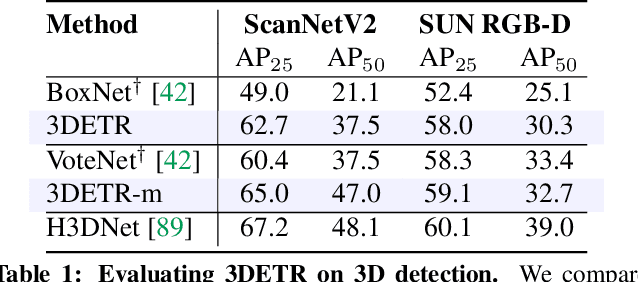


We propose 3DETR, an end-to-end Transformer based object detection model for 3D point clouds. Compared to existing detection methods that employ a number of 3D-specific inductive biases, 3DETR requires minimal modifications to the vanilla Transformer block. Specifically, we find that a standard Transformer with non-parametric queries and Fourier positional embeddings is competitive with specialized architectures that employ libraries of 3D-specific operators with hand-tuned hyperparameters. Nevertheless, 3DETR is conceptually simple and easy to implement, enabling further improvements by incorporating 3D domain knowledge. Through extensive experiments, we show 3DETR outperforms the well-established and highly optimized VoteNet baselines on the challenging ScanNetV2 dataset by 9.5%. Furthermore, we show 3DETR is applicable to 3D tasks beyond detection, and can serve as a building block for future research.
Emerging Properties in Self-Supervised Vision Transformers
May 24, 2021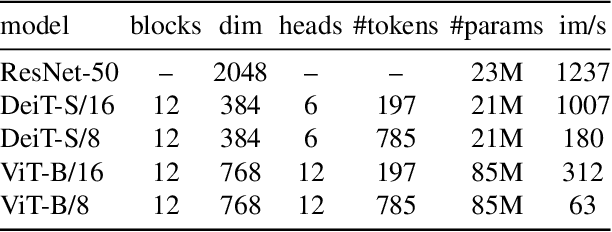
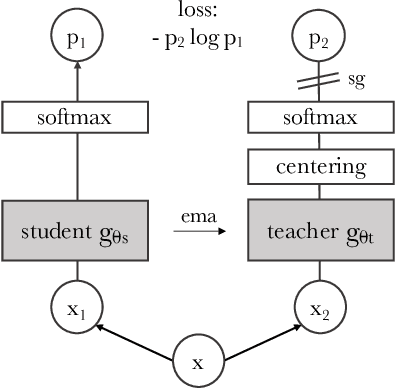
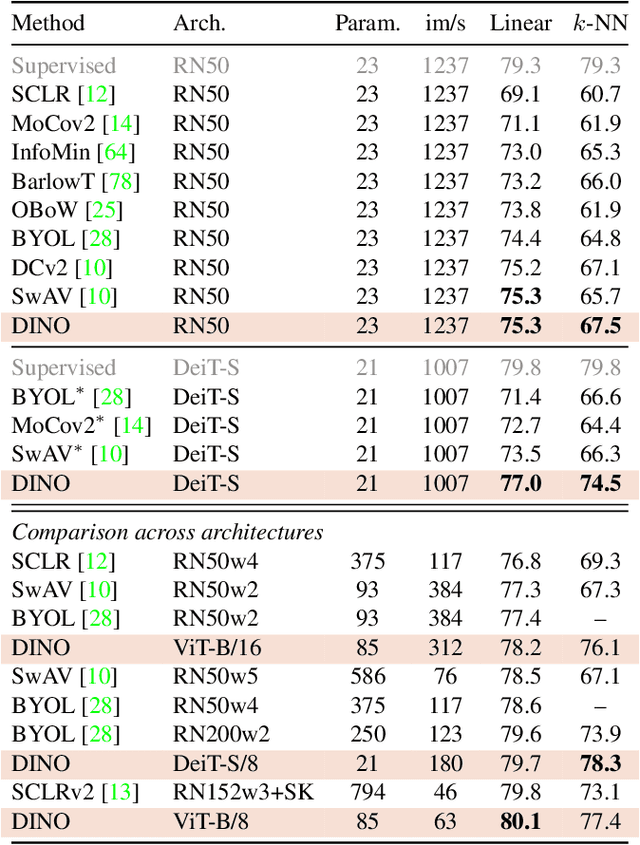
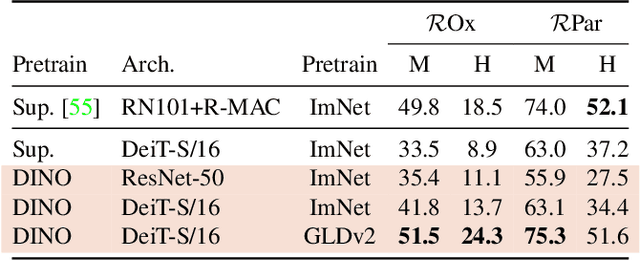
In this paper, we question if self-supervised learning provides new properties to Vision Transformer (ViT) that stand out compared to convolutional networks (convnets). Beyond the fact that adapting self-supervised methods to this architecture works particularly well, we make the following observations: first, self-supervised ViT features contain explicit information about the semantic segmentation of an image, which does not emerge as clearly with supervised ViTs, nor with convnets. Second, these features are also excellent k-NN classifiers, reaching 78.3% top-1 on ImageNet with a small ViT. Our study also underlines the importance of momentum encoder, multi-crop training, and the use of small patches with ViTs. We implement our findings into a simple self-supervised method, called DINO, which we interpret as a form of self-distillation with no labels. We show the synergy between DINO and ViTs by achieving 80.1% top-1 on ImageNet in linear evaluation with ViT-Base.
3D Spatial Recognition without Spatially Labeled 3D
May 13, 2021

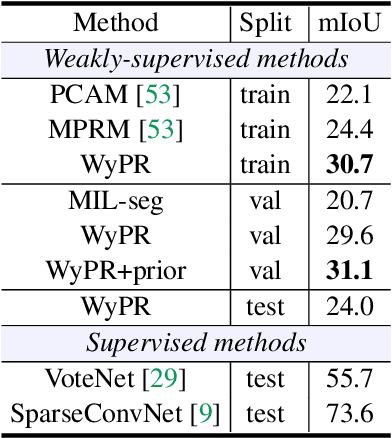

We introduce WyPR, a Weakly-supervised framework for Point cloud Recognition, requiring only scene-level class tags as supervision. WyPR jointly addresses three core 3D recognition tasks: point-level semantic segmentation, 3D proposal generation, and 3D object detection, coupling their predictions through self and cross-task consistency losses. We show that in conjunction with standard multiple-instance learning objectives, WyPR can detect and segment objects in point cloud data without access to any spatial labels at training time. We demonstrate its efficacy using the ScanNet and S3DIS datasets, outperforming prior state of the art on weakly-supervised segmentation by more than 6% mIoU. In addition, we set up the first benchmark for weakly-supervised 3D object detection on both datasets, where WyPR outperforms standard approaches and establishes strong baselines for future work.