 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHamiltonian Generative Networks
Sep 30, 2019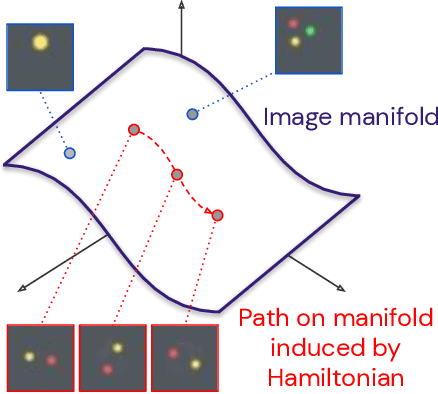

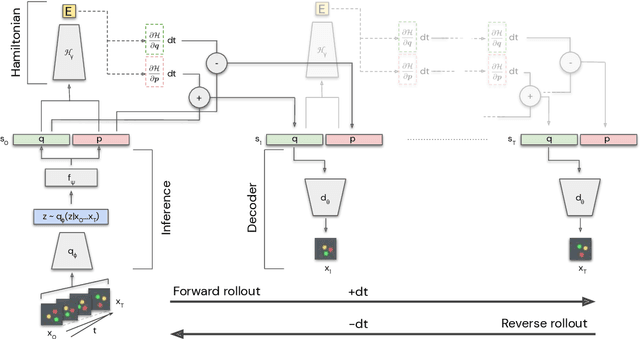

The Hamiltonian formalism plays a central role in classical and quantum physics. Hamiltonians are the main tool for modelling the continuous time evolution of systems with conserved quantities, and they come equipped with many useful properties, like time reversibility and smooth interpolation in time. These properties are important for many machine learning problems - from sequence prediction to reinforcement learning and density modelling - but are not typically provided out of the box by standard tools such as recurrent neural networks. In this paper, we introduce the Hamiltonian Generative Network (HGN), the first approach capable of consistently learning Hamiltonian dynamics from high-dimensional observations (such as images) without restrictive domain assumptions. Once trained, we can use HGN to sample new trajectories, perform rollouts both forward and backward in time and even speed up or slow down the learned dynamics. We demonstrate how a simple modification of the network architecture turns HGN into a powerful normalising flow model, called Neural Hamiltonian Flow (NHF), that uses Hamiltonian dynamics to model expressive densities. We hope that our work serves as a first practical demonstration of the value that the Hamiltonian formalism can bring to deep learning.
Equivariant Hamiltonian Flows
Sep 30, 2019
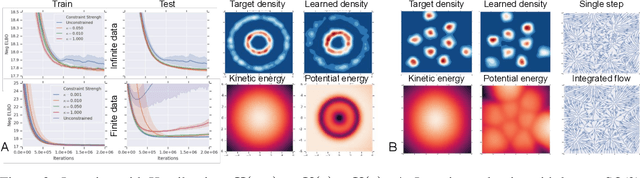
This paper introduces equivariant hamiltonian flows, a method for learning expressive densities that are invariant with respect to a known Lie-algebra of local symmetry transformations while providing an equivariant representation of the data. We provide proof of principle demonstrations of how such flows can be learnt, as well as how the addition of symmetry invariance constraints can improve data efficiency and generalisation. Finally, we make connections to disentangled representation learning and show how this work relates to a recently proposed definition.
A Heuristic for Unsupervised Model Selection for Variational Disentangled Representation Learning
May 29, 2019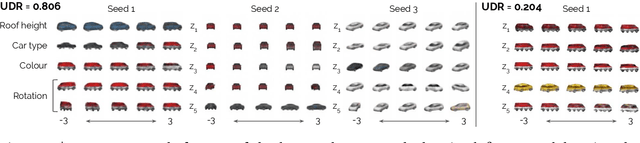

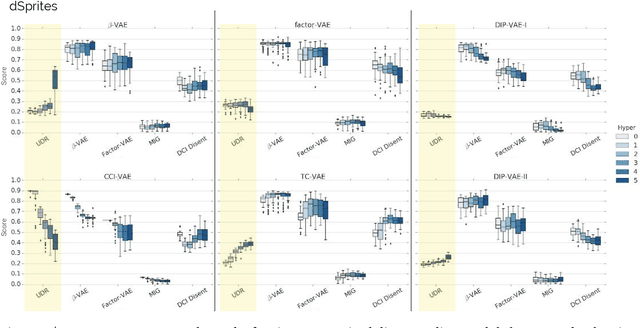

Disentangled representations have recently been shown to improve data efficiency, generalisation, robustness and interpretability in simple supervised and reinforcement learning tasks. To extend such results to more complex domains, it is important to address a major shortcoming of the current state of the art unsupervised disentangling approaches -- high convergence variance, whereby different disentanglement quality may be achieved by the same model depending on its initial state. The existing model selection methods require access to the ground truth attribute labels, which are not available for most datasets. Hence, the benefits of disentangled representations have not yet been fully explored in practical applications. This paper addresses this problem by introducing a simple yet robust and reliable method for unsupervised disentangled model selection. We show that our approach performs comparably to the existing supervised alternatives across 5400 models from six state of the art unsupervised disentangled representation learning model classes.
MONet: Unsupervised Scene Decomposition and Representation
Jan 22, 2019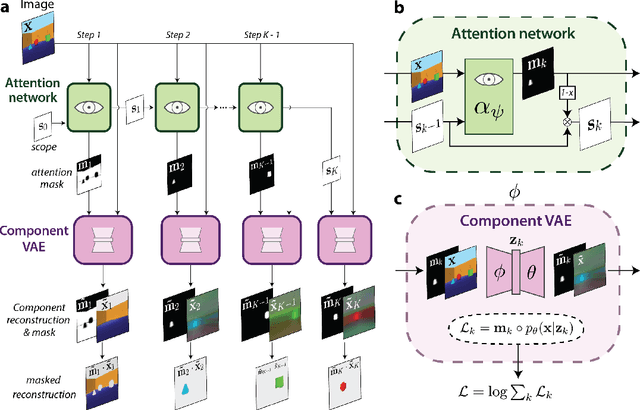
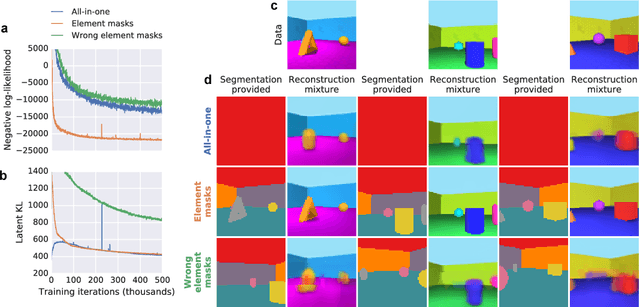
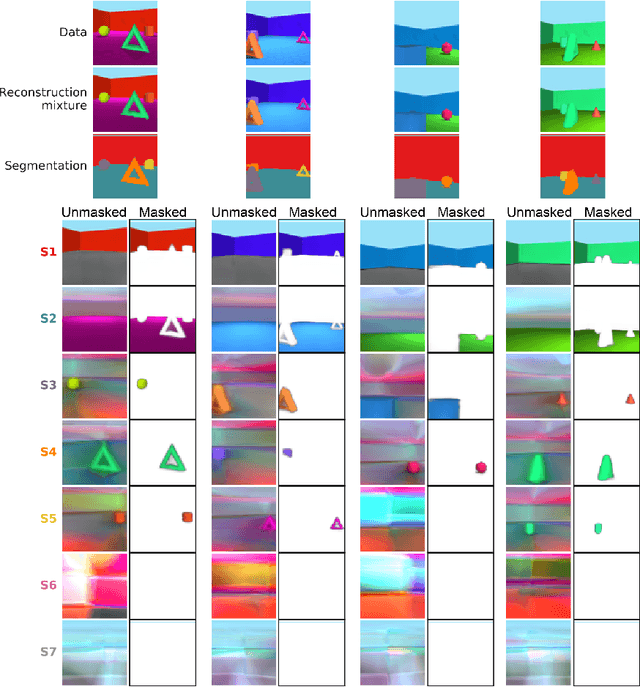
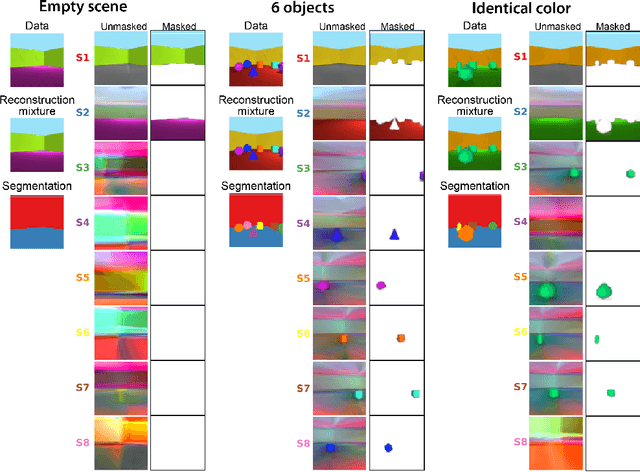
The ability to decompose scenes in terms of abstract building blocks is crucial for general intelligence. Where those basic building blocks share meaningful properties, interactions and other regularities across scenes, such decompositions can simplify reasoning and facilitate imagination of novel scenarios. In particular, representing perceptual observations in terms of entities should improve data efficiency and transfer performance on a wide range of tasks. Thus we need models capable of discovering useful decompositions of scenes by identifying units with such regularities and representing them in a common format. To address this problem, we have developed the Multi-Object Network (MONet). In this model, a VAE is trained end-to-end together with a recurrent attention network -- in a purely unsupervised manner -- to provide attention masks around, and reconstructions of, regions of images. We show that this model is capable of learning to decompose and represent challenging 3D scenes into semantically meaningful components, such as objects and background elements.
Towards a Definition of Disentangled Representations
Dec 05, 2018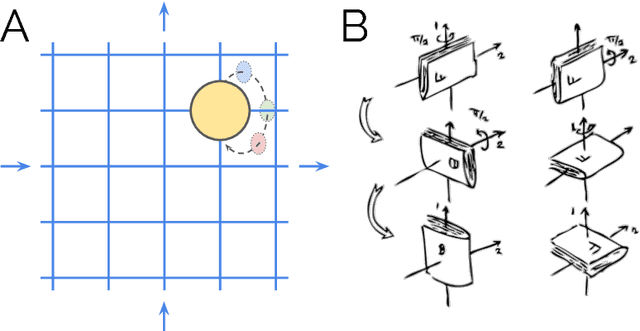
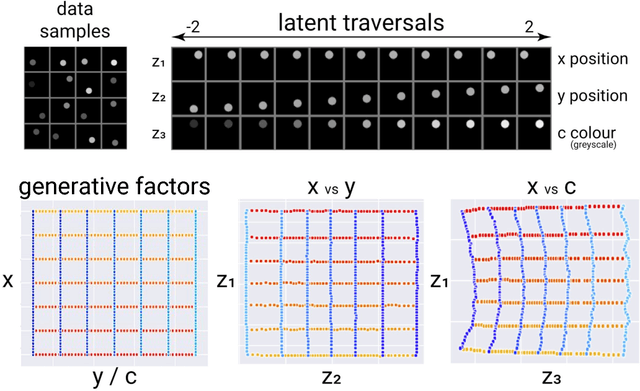
How can intelligent agents solve a diverse set of tasks in a data-efficient manner? The disentangled representation learning approach posits that such an agent would benefit from separating out (disentangling) the underlying structure of the world into disjoint parts of its representation. However, there is no generally agreed-upon definition of disentangling, not least because it is unclear how to formalise the notion of world structure beyond toy datasets with a known ground truth generative process. Here we propose that a principled solution to characterising disentangled representations can be found by focusing on the transformation properties of the world. In particular, we suggest that those transformations that change only some properties of the underlying world state, while leaving all other properties invariant, are what gives exploitable structure to any kind of data. Similar ideas have already been successfully applied in physics, where the study of symmetry transformations has revolutionised the understanding of the world structure. By connecting symmetry transformations to vector representations using the formalism of group and representation theory we arrive at the first formal definition of disentangled representations. Our new definition is in agreement with many of the current intuitions about disentangling, while also providing principled resolutions to a number of previous points of contention. While this work focuses on formally defining disentangling - as opposed to solving the learning problem - we believe that the shift in perspective to studying data transformations can stimulate the development of better representation learning algorithms.
Life-Long Disentangled Representation Learning with Cross-Domain Latent Homologies
Aug 20, 2018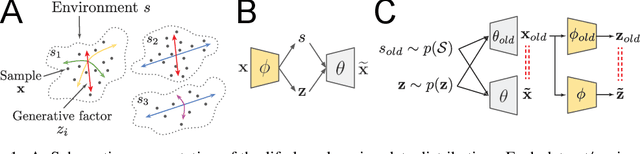
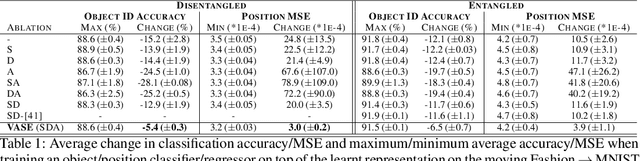
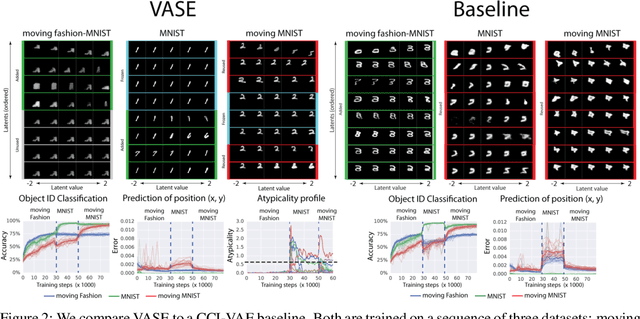
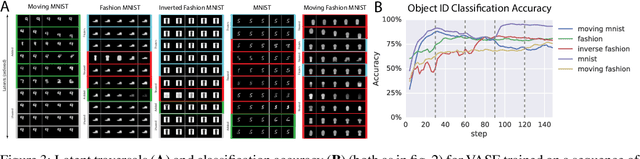
Intelligent behaviour in the real-world requires the ability to acquire new knowledge from an ongoing sequence of experiences while preserving and reusing past knowledge. We propose a novel algorithm for unsupervised representation learning from piece-wise stationary visual data: Variational Autoencoder with Shared Embeddings (VASE). Based on the Minimum Description Length principle, VASE automatically detects shifts in the data distribution and allocates spare representational capacity to new knowledge, while simultaneously protecting previously learnt representations from catastrophic forgetting. Our approach encourages the learnt representations to be disentangled, which imparts a number of desirable properties: VASE can deal sensibly with ambiguous inputs, it can enhance its own representations through imagination-based exploration, and most importantly, it exhibits semantically meaningful sharing of latents between different datasets. Compared to baselines with entangled representations, our approach is able to reason beyond surface-level statistics and perform semantically meaningful cross-domain inference.
SCAN: Learning Hierarchical Compositional Visual Concepts
Jun 06, 2018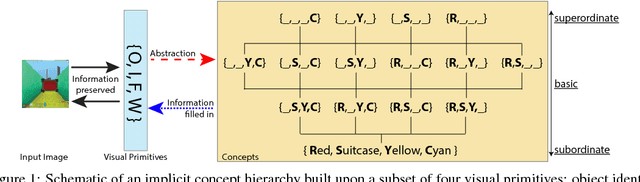
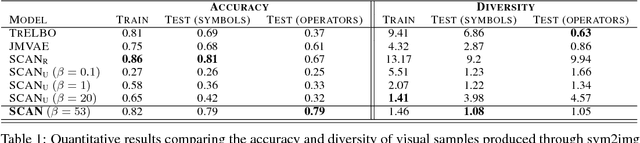
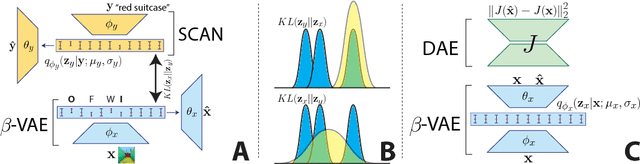
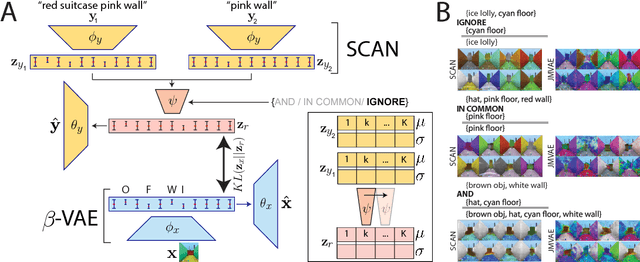
The seemingly infinite diversity of the natural world arises from a relatively small set of coherent rules, such as the laws of physics or chemistry. We conjecture that these rules give rise to regularities that can be discovered through primarily unsupervised experiences and represented as abstract concepts. If such representations are compositional and hierarchical, they can be recombined into an exponentially large set of new concepts. This paper describes SCAN (Symbol-Concept Association Network), a new framework for learning such abstractions in the visual domain. SCAN learns concepts through fast symbol association, grounding them in disentangled visual primitives that are discovered in an unsupervised manner. Unlike state of the art multimodal generative model baselines, our approach requires very few pairings between symbols and images and makes no assumptions about the form of symbol representations. Once trained, SCAN is capable of multimodal bi-directional inference, generating a diverse set of image samples from symbolic descriptions and vice versa. It also allows for traversal and manipulation of the implicit hierarchy of visual concepts through symbolic instructions and learnt logical recombination operations. Such manipulations enable SCAN to break away from its training data distribution and imagine novel visual concepts through symbolically instructed recombination of previously learnt concepts.
DARLA: Improving Zero-Shot Transfer in Reinforcement Learning
Jun 06, 2018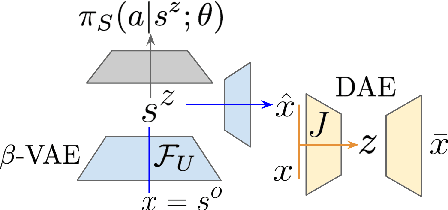
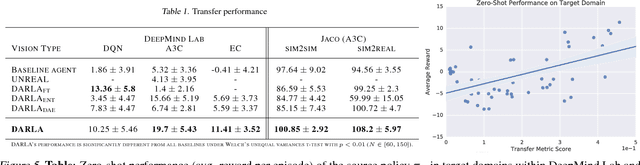
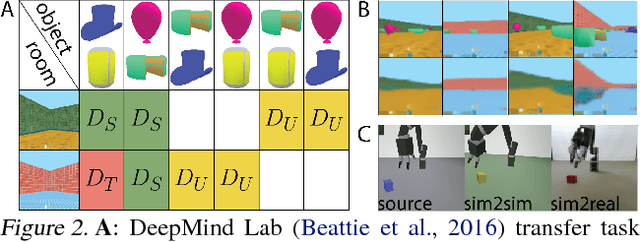
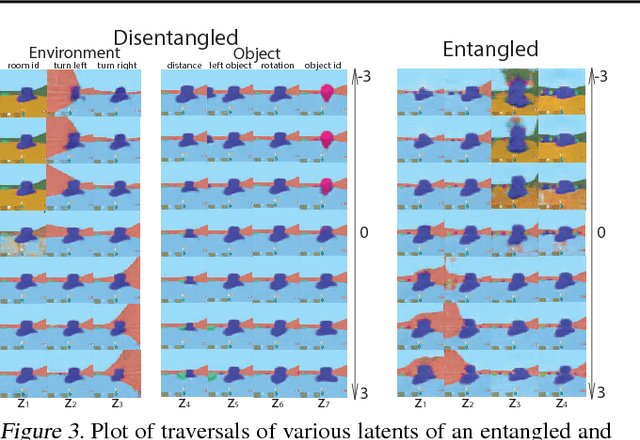
Domain adaptation is an important open problem in deep reinforcement learning (RL). In many scenarios of interest data is hard to obtain, so agents may learn a source policy in a setting where data is readily available, with the hope that it generalises well to the target domain. We propose a new multi-stage RL agent, DARLA (DisentAngled Representation Learning Agent), which learns to see before learning to act. DARLA's vision is based on learning a disentangled representation of the observed environment. Once DARLA can see, it is able to acquire source policies that are robust to many domain shifts - even with no access to the target domain. DARLA significantly outperforms conventional baselines in zero-shot domain adaptation scenarios, an effect that holds across a variety of RL environments (Jaco arm, DeepMind Lab) and base RL algorithms (DQN, A3C and EC).
Understanding disentangling in $β$-VAE
Apr 10, 2018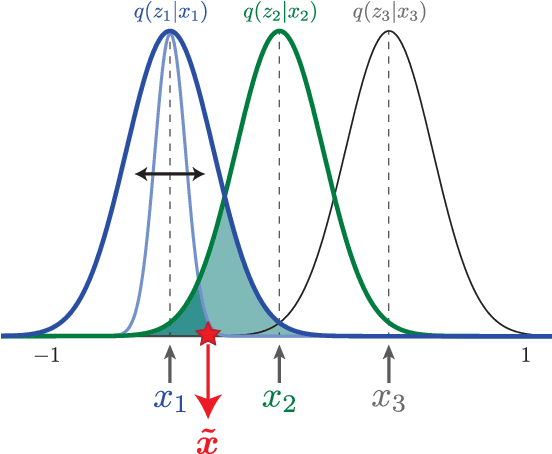

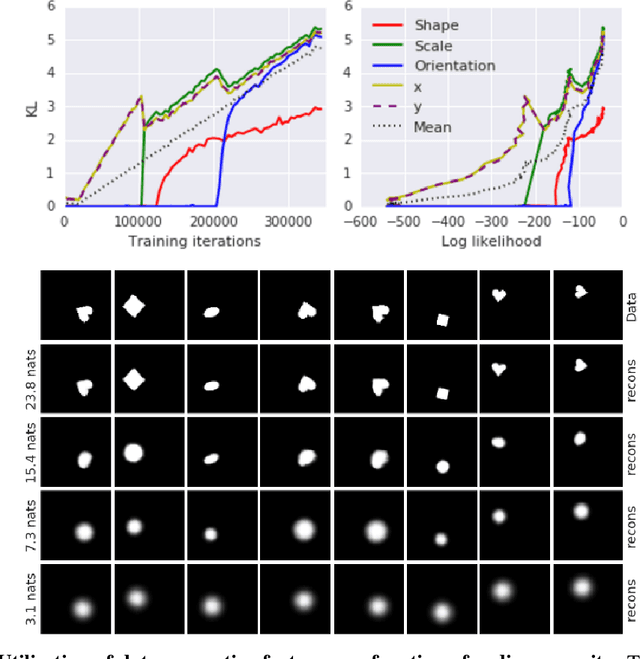

We present new intuitions and theoretical assessments of the emergence of disentangled representation in variational autoencoders. Taking a rate-distortion theory perspective, we show the circumstances under which representations aligned with the underlying generative factors of variation of data emerge when optimising the modified ELBO bound in $\beta$-VAE, as training progresses. From these insights, we propose a modification to the training regime of $\beta$-VAE, that progressively increases the information capacity of the latent code during training. This modification facilitates the robust learning of disentangled representations in $\beta$-VAE, without the previous trade-off in reconstruction accuracy.
Early Visual Concept Learning with Unsupervised Deep Learning
Sep 20, 2016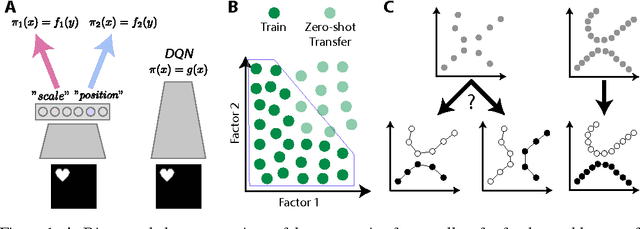
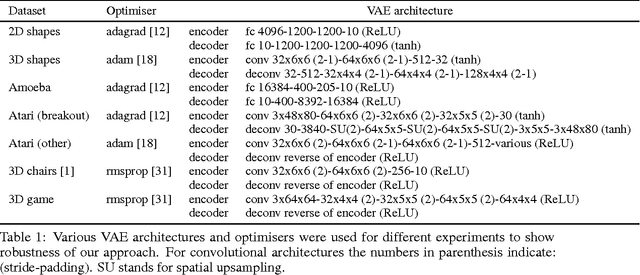
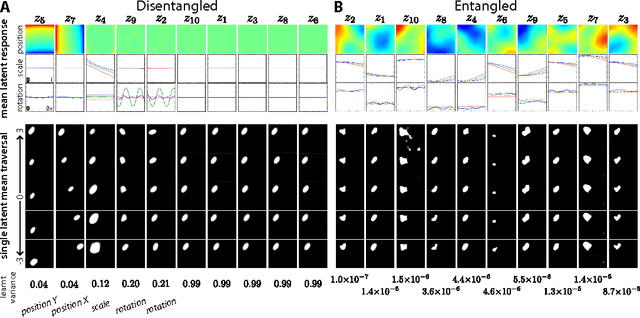

Automated discovery of early visual concepts from raw image data is a major open challenge in AI research. Addressing this problem, we propose an unsupervised approach for learning disentangled representations of the underlying factors of variation. We draw inspiration from neuroscience, and show how this can be achieved in an unsupervised generative model by applying the same learning pressures as have been suggested to act in the ventral visual stream in the brain. By enforcing redundancy reduction, encouraging statistical independence, and exposure to data with transform continuities analogous to those to which human infants are exposed, we obtain a variational autoencoder (VAE) framework capable of learning disentangled factors. Our approach makes few assumptions and works well across a wide variety of datasets. Furthermore, our solution has useful emergent properties, such as zero-shot inference and an intuitive understanding of "objectness".