 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Multi-Resolution Transformer Fine-tuning for Extreme Multi-label Text Classification
Oct 01, 2021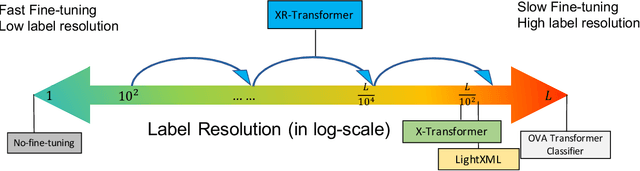
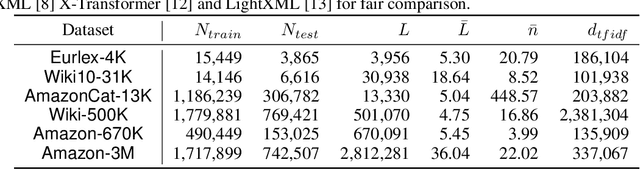
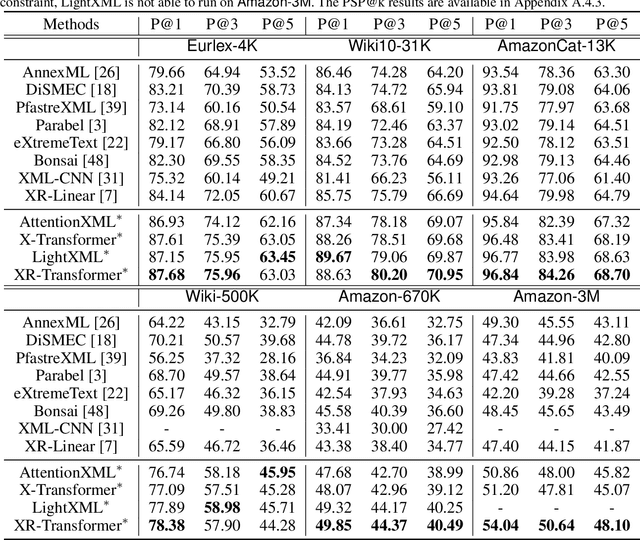

Extreme multi-label text classification (XMC) seeks to find relevant labels from an extreme large label collection for a given text input. Many real-world applications can be formulated as XMC problems, such as recommendation systems, document tagging and semantic search. Recently, transformer based XMC methods, such as X-Transformer and LightXML, have shown significant improvement over other XMC methods. Despite leveraging pre-trained transformer models for text representation, the fine-tuning procedure of transformer models on large label space still has lengthy computational time even with powerful GPUs. In this paper, we propose a novel recursive approach, XR-Transformer to accelerate the procedure through recursively fine-tuning transformer models on a series of multi-resolution objectives related to the original XMC objective function. Empirical results show that XR-Transformer takes significantly less training time compared to other transformer-based XMC models while yielding better state-of-the-art results. In particular, on the public Amazon-3M dataset with 3 million labels, XR-Transformer is not only 20x faster than X-Transformer but also improves the Precision@1 from 51% to 54%.
Label Disentanglement in Partition-based Extreme Multilabel Classification
Jun 24, 2021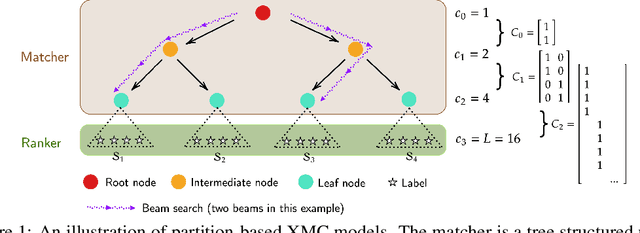
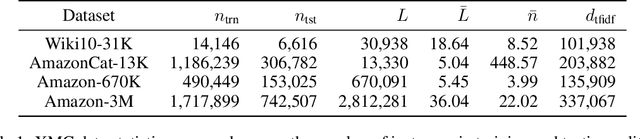
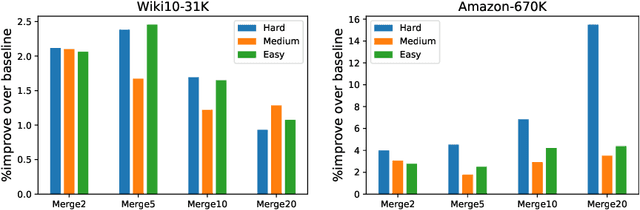
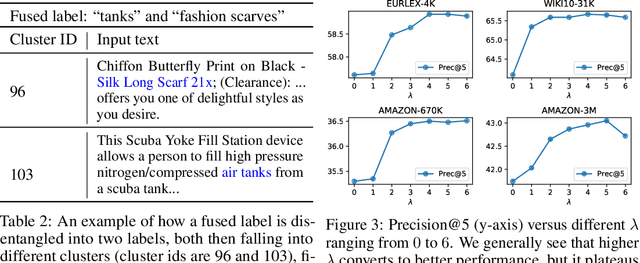
Partition-based methods are increasingly-used in extreme multi-label classification (XMC) problems due to their scalability to large output spaces (e.g., millions or more). However, existing methods partition the large label space into mutually exclusive clusters, which is sub-optimal when labels have multi-modality and rich semantics. For instance, the label "Apple" can be the fruit or the brand name, which leads to the following research question: can we disentangle these multi-modal labels with non-exclusive clustering tailored for downstream XMC tasks? In this paper, we show that the label assignment problem in partition-based XMC can be formulated as an optimization problem, with the objective of maximizing precision rates. This leads to an efficient algorithm to form flexible and overlapped label clusters, and a method that can alternatively optimizes the cluster assignments and the model parameters for partition-based XMC. Experimental results on synthetic and real datasets show that our method can successfully disentangle multi-modal labels, leading to state-of-the-art (SOTA) results on four XMC benchmarks.
Extreme Multi-label Learning for Semantic Matching in Product Search
Jun 23, 2021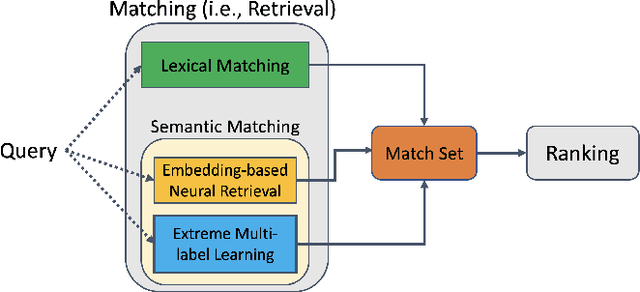

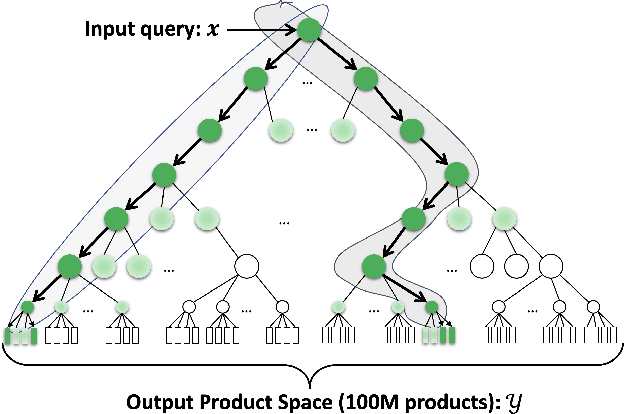
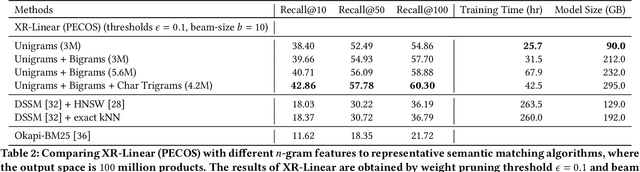
We consider the problem of semantic matching in product search: given a customer query, retrieve all semantically related products from a huge catalog of size 100 million, or more. Because of large catalog spaces and real-time latency constraints, semantic matching algorithms not only desire high recall but also need to have low latency. Conventional lexical matching approaches (e.g., Okapi-BM25) exploit inverted indices to achieve fast inference time, but fail to capture behavioral signals between queries and products. In contrast, embedding-based models learn semantic representations from customer behavior data, but the performance is often limited by shallow neural encoders due to latency constraints. Semantic product search can be viewed as an eXtreme Multi-label Classification (XMC) problem, where customer queries are input instances and products are output labels. In this paper, we aim to improve semantic product search by using tree-based XMC models where inference time complexity is logarithmic in the number of products. We consider hierarchical linear models with n-gram features for fast real-time inference. Quantitatively, our method maintains a low latency of 1.25 milliseconds per query and achieves a 65% improvement of Recall@100 (60.9% v.s. 36.8%) over a competing embedding-based DSSM model. Our model is robust to weight pruning with varying thresholds, which can flexibly meet different system requirements for online deployments. Qualitatively, our method can retrieve products that are complementary to existing product search system and add diversity to the match set.
Robust Training in High Dimensions via Block Coordinate Geometric Median Descent
Jun 16, 2021
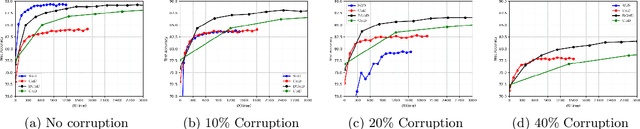
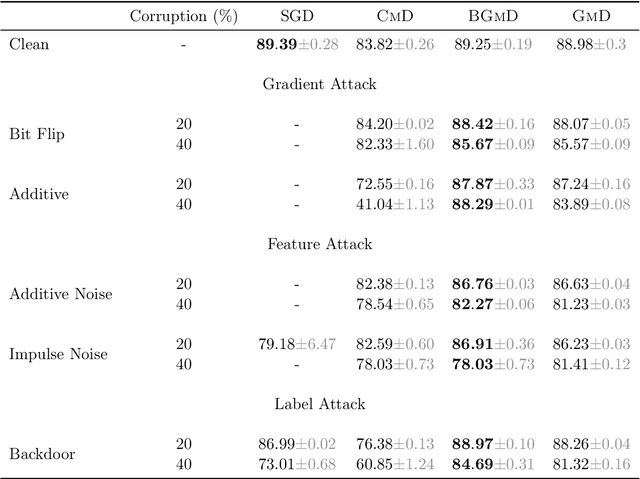
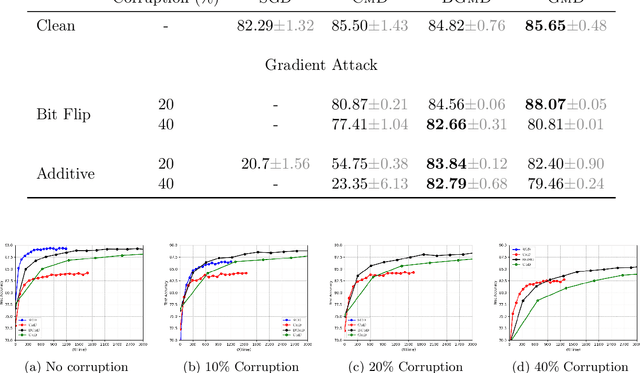
Geometric median (\textsc{Gm}) is a classical method in statistics for achieving a robust estimation of the uncorrupted data; under gross corruption, it achieves the optimal breakdown point of 0.5. However, its computational complexity makes it infeasible for robustifying stochastic gradient descent (SGD) for high-dimensional optimization problems. In this paper, we show that by applying \textsc{Gm} to only a judiciously chosen block of coordinates at a time and using a memory mechanism, one can retain the breakdown point of 0.5 for smooth non-convex problems, with non-asymptotic convergence rates comparable to the SGD with \textsc{Gm}.
DP-NormFedAvg: Normalizing Client Updates for Privacy-Preserving Federated Learning
Jun 13, 2021
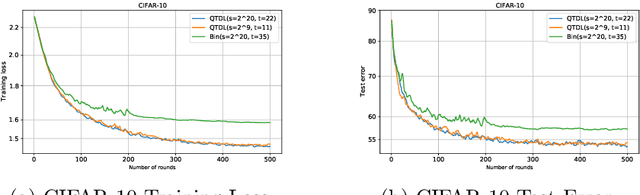

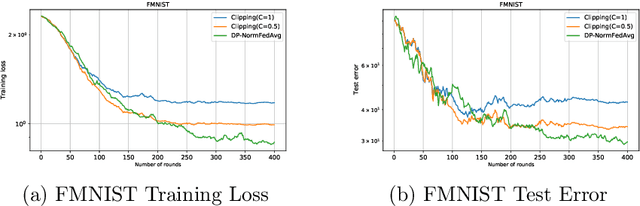
In this paper, we focus on facilitating differentially private quantized communication between the clients and server in federated learning (FL). Towards this end, we propose to have the clients send a \textit{private quantized} version of only the \textit{unit vector} along the change in their local parameters to the server, \textit{completely throwing away the magnitude information}. We call this algorithm \texttt{DP-NormFedAvg} and show that it has the same order-wise convergence rate as \texttt{FedAvg} on smooth quasar-convex functions (an important class of non-convex functions for modeling optimization of deep neural networks), thereby establishing that discarding the magnitude information is not detrimental from an optimization point of view. We also introduce QTDL, a new differentially private quantization mechanism for unit-norm vectors, which we use in \texttt{DP-NormFedAvg}. QTDL employs \textit{discrete} noise having a Laplacian-like distribution on a \textit{finite support} to provide privacy. We show that under a growth-condition assumption on the per-sample client losses, the extra per-coordinate communication cost in each round incurred due to privacy by our method is $\mathcal{O}(1)$ with respect to the model dimension, which is an improvement over prior work. Finally, we show the efficacy of our proposed method with experiments on fully-connected neural networks trained on CIFAR-10 and Fashion-MNIST.
Enabling Efficiency-Precision Trade-offs for Label Trees in Extreme Classification
Jun 01, 2021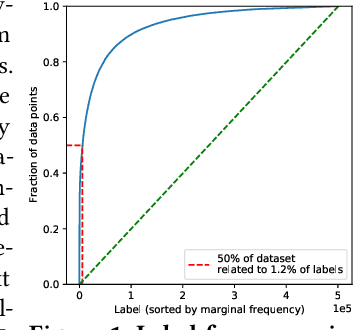
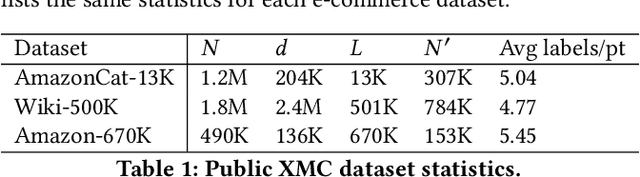
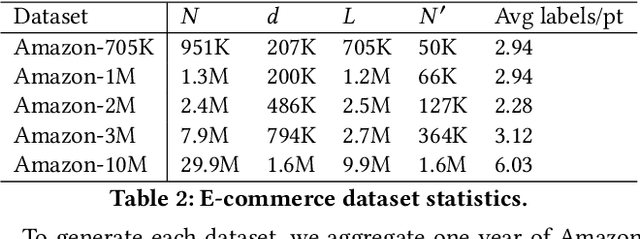
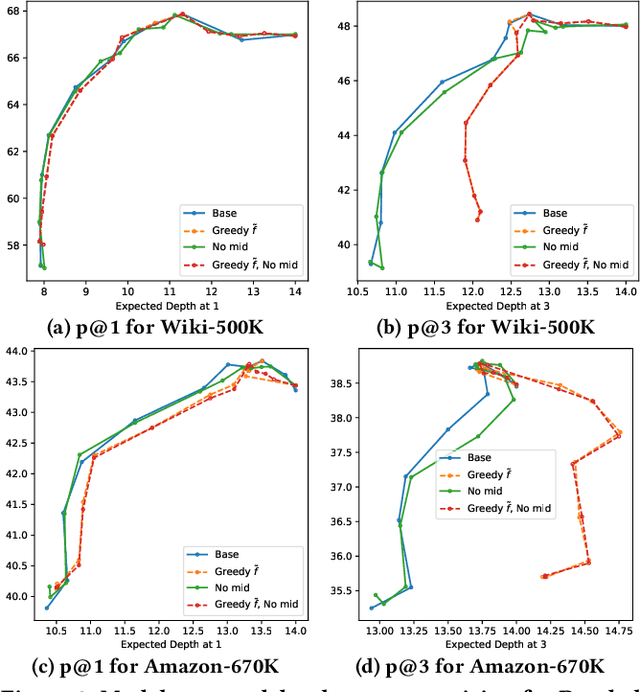
Extreme multi-label classification (XMC) aims to learn a model that can tag data points with a subset of relevant labels from an extremely large label set. Real world e-commerce applications like personalized recommendations and product advertising can be formulated as XMC problems, where the objective is to predict for a user a small subset of items from a catalog of several million products. For such applications, a common approach is to organize these labels into a tree, enabling training and inference times that are logarithmic in the number of labels. While training a model once a label tree is available is well studied, designing the structure of the tree is a difficult task that is not yet well understood, and can dramatically impact both model latency and statistical performance. Existing approaches to tree construction fall at an extreme point, either optimizing exclusively for statistical performance, or for latency. We propose an efficient information theory inspired algorithm to construct intermediary operating points that trade off between the benefits of both. Our algorithm enables interpolation between these objectives, which was not previously possible. We corroborate our theoretical analysis with numerical results, showing that on the Wiki-500K benchmark dataset our method can reduce a proxy for expected latency by up to 28% while maintaining the same accuracy as Parabel. On several datasets derived from e-commerce customer logs, our modified label tree is able to improve this expected latency metric by up to 20% while maintaining the same accuracy. Finally, we discuss challenges in realizing these latency improvements in deployed models.
Combinatorial Bandits without Total Order for Arms
Mar 03, 2021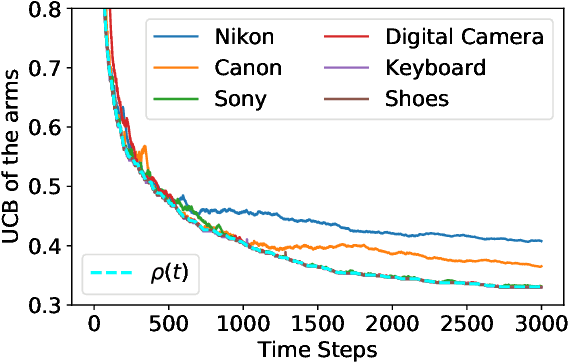
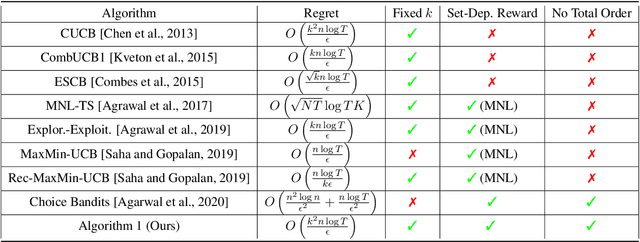
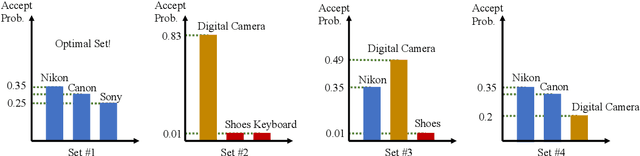
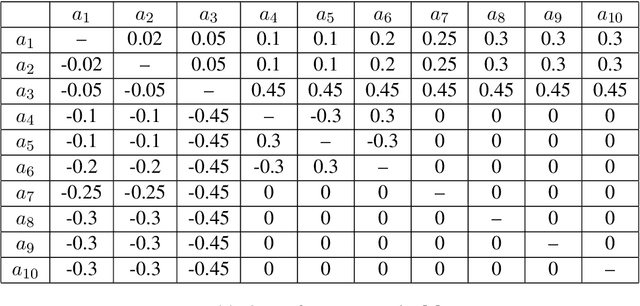
We consider the combinatorial bandits problem, where at each time step, the online learner selects a size-$k$ subset $s$ from the arms set $\mathcal{A}$, where $\left|\mathcal{A}\right| = n$, and observes a stochastic reward of each arm in the selected set $s$. The goal of the online learner is to minimize the regret, induced by not selecting $s^*$ which maximizes the expected total reward. Specifically, we focus on a challenging setting where 1) the reward distribution of an arm depends on the set $s$ it is part of, and crucially 2) there is \textit{no total order} for the arms in $\mathcal{A}$. In this paper, we formally present a reward model that captures set-dependent reward distribution and assumes no total order for arms. Correspondingly, we propose an Upper Confidence Bound (UCB) algorithm that maintains UCB for each individual arm and selects the arms with top-$k$ UCB. We develop a novel regret analysis and show an $O\left(\frac{k^2 n \log T}{\epsilon}\right)$ gap-dependent regret bound as well as an $O\left(k^2\sqrt{n T \log T}\right)$ gap-independent regret bound. We also provide a lower bound for the proposed reward model, which shows our proposed algorithm is near-optimal for any constant $k$. Empirical results on various reward models demonstrate the broad applicability of our algorithm.
Linear Bandit Algorithms with Sublinear Time Complexity
Mar 03, 2021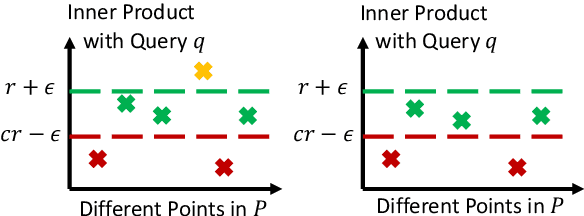
We propose to accelerate existing linear bandit algorithms to achieve per-step time complexity sublinear in the number of arms $K$. The key to sublinear complexity is the realization that the arm selection in many linear bandit algorithms reduces to the maximum inner product search (MIPS) problem. Correspondingly, we propose an algorithm that approximately solves the MIPS problem for a sequence of adaptive queries yielding near-linear preprocessing time complexity and sublinear query time complexity. Using the proposed MIPS solver as a sub-routine, we present two bandit algorithms (one based on UCB, and the other based on TS) that achieve sublinear time complexity. We explicitly characterize the tradeoff between the per-step time complexity and regret, and show that our proposed algorithms can achieve $O(K^{1-\alpha(T)})$ per-step complexity for some $\alpha(T) > 0$ and $\widetilde O(\sqrt{T})$ regret, where $T$ is the time horizon. Further, we present the theoretical limit of the tradeoff, which provides a lower bound for the per-step time complexity. We also discuss other choices of approximate MIPS algorithms and other applications to linear bandit problems.
Improved Convergence Rates for Non-Convex Federated Learning with Compression
Dec 12, 2020
Federated learning is a new distributed learning paradigm that enables efficient training of emerging large-scale machine learning models. In this paper, we consider federated learning on non-convex objectives with compressed communication from the clients to the central server. We propose a novel first-order algorithm (\texttt{FedSTEPH2}) that employs compressed communication and achieves the optimal iteration complexity of $\mathcal{O}(1/\epsilon^{1.5})$ to reach an $\epsilon$-stationary point (i.e. $\mathbb{E}[\|\nabla f(\bm{x})\|^2] \leq \epsilon$) on smooth non-convex objectives. The proposed scheme is the first algorithm that attains the aforementioned optimal complexity with compressed communication and without using full client gradients at each communication round. The key idea of \texttt{FedSTEPH2} that enables attaining this optimal complexity is applying judicious momentum terms both in the local client updates and the global server update. As a prequel to \texttt{FedSTEPH2}, we propose \texttt{FedSTEPH} which involves a momentum term only in the local client updates. We establish that \texttt{FedSTEPH} enjoys improved convergence rates under various non-convex settings (such as the Polyak-\L{}ojasiewicz condition) and with fewer assumptions than prior work.
Session-Aware Query Auto-completion using Extreme Multi-label Ranking
Dec 09, 2020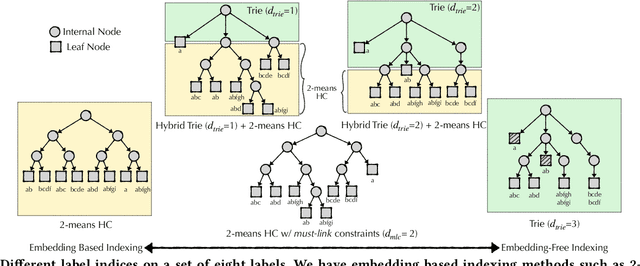
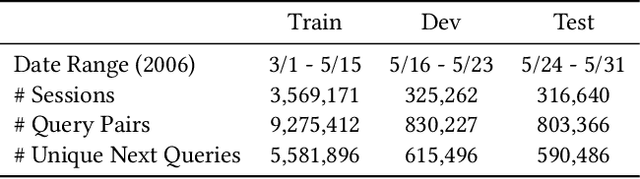
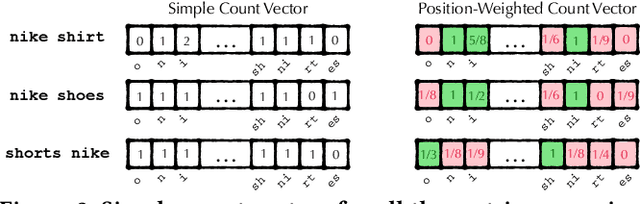
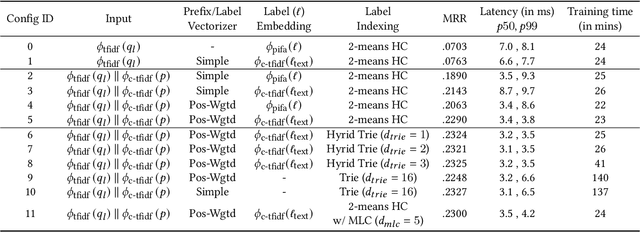
Query auto-completion is a fundamental feature in search engines where the task is to suggest plausible completions of a prefix typed in the search bar. Previous queries in the user session can provide useful context for the user's intent and can be leveraged to suggest auto-completions that are more relevant while adhering to the user's prefix. Such session-aware query auto-completions can be generated by sequence-to-sequence models; however, these generative approaches often do not meet the stringent latency requirements of responding to each user keystroke. Moreover, there is a danger of showing non-sensical queries in a generative approach. Another solution is to pre-compute a relatively small subset of relevant queries for common prefixes and rank them based on the context. However, such an approach would fail if no relevant queries for the current context are present in the pre-computed set. In this paper, we provide a solution to this problem: we take the novel approach of modeling session-aware query auto-completion as an eXtreme Multi-Label Ranking (XMR) problem where the input is the previous query in the session and the user's current prefix, while the output space is the set of millions of queries entered by users in the recent past. We adapt a popular XMR algorithm for this purpose by proposing several modifications to the key steps in the algorithm. The proposed modifications yield a 230% improvement in terms of Mean Reciprocal Rank over the baseline XMR approach on a public search logs dataset. Our approach meets the stringent latency requirements for auto-complete systems while leveraging session information in making suggestions. We show that session context leads to significant improvements in the quality of query auto-completions; in particular, for short prefixes with up to 3 characters, we see a 32% improvement over baselines that meet latency requirements.