 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Real-time Video Stabilization
Nov 10, 2021
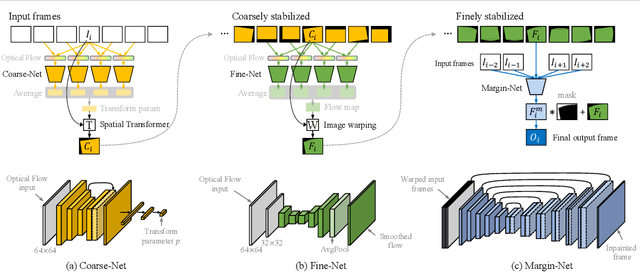

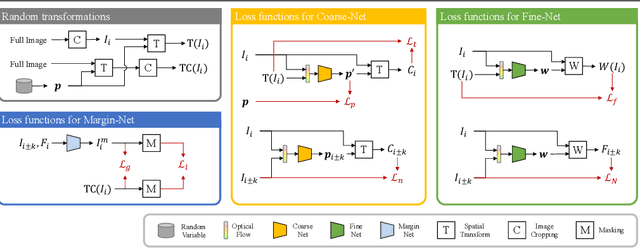
Videos are a popular media form, where online video streaming has recently gathered much popularity. In this work, we propose a novel method of real-time video stabilization - transforming a shaky video to a stabilized video as if it were stabilized via gimbals in real-time. Our framework is trainable in a self-supervised manner, which does not require data captured with special hardware setups (i.e., two cameras on a stereo rig or additional motion sensors). Our framework consists of a transformation estimator between given frames for global stability adjustments, followed by scene parallax reduction module via spatially smoothed optical flow for further stability. Then, a margin inpainting module fills in the missing margin regions created during stabilization to reduce the amount of post-cropping. These sequential steps reduce distortion and margin cropping to a minimum while enhancing stability. Hence, our approach outperforms state-of-the-art real-time video stabilization methods as well as offline methods that require camera trajectory optimization. Our method procedure takes approximately 24.3 ms yielding 41 fps regardless of resolution (e.g., 480p or 1080p).
Attentive and Contrastive Learning for Joint Depth and Motion Field Estimation
Oct 13, 2021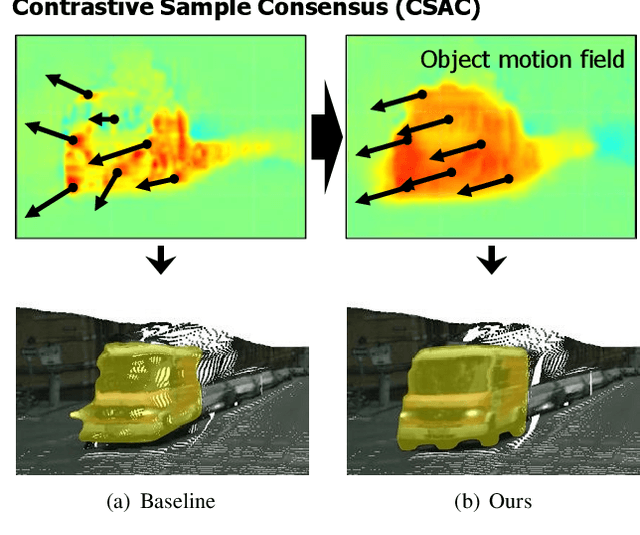
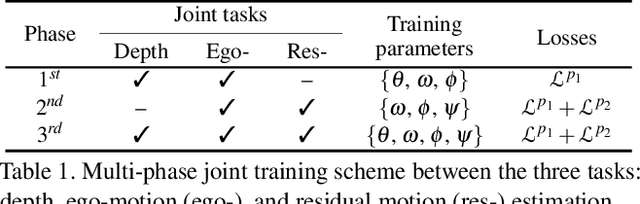
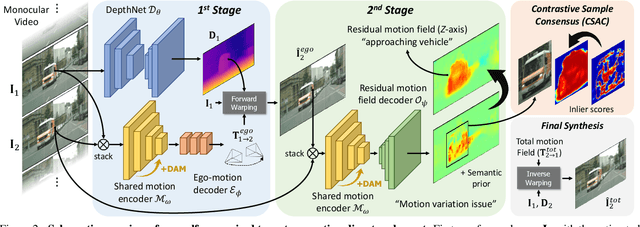

Estimating the motion of the camera together with the 3D structure of the scene from a monocular vision system is a complex task that often relies on the so-called scene rigidity assumption. When observing a dynamic environment, this assumption is violated which leads to an ambiguity between the ego-motion of the camera and the motion of the objects. To solve this problem, we present a self-supervised learning framework for 3D object motion field estimation from monocular videos. Our contributions are two-fold. First, we propose a two-stage projection pipeline to explicitly disentangle the camera ego-motion and the object motions with dynamics attention module, called DAM. Specifically, we design an integrated motion model that estimates the motion of the camera and object in the first and second warping stages, respectively, controlled by the attention module through a shared motion encoder. Second, we propose an object motion field estimation through contrastive sample consensus, called CSAC, taking advantage of weak semantic prior (bounding box from an object detector) and geometric constraints (each object respects the rigid body motion model). Experiments on KITTI, Cityscapes, and Waymo Open Dataset demonstrate the relevance of our approach and show that our method outperforms state-of-the-art algorithms for the tasks of self-supervised monocular depth estimation, object motion segmentation, monocular scene flow estimation, and visual odometry.
Adversarial Robustness Comparison of Vision Transformer and MLP-Mixer to CNNs
Oct 11, 2021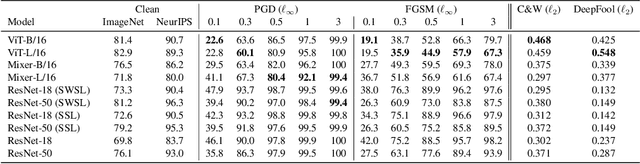


Convolutional Neural Networks (CNNs) have become the de facto gold standard in computer vision applications in the past years. Recently, however, new model architectures have been proposed challenging the status quo. The Vision Transformer (ViT) relies solely on attention modules, while the MLP-Mixer architecture substitutes the self-attention modules with Multi-Layer Perceptrons (MLPs). Despite their great success, CNNs have been widely known to be vulnerable to adversarial attacks, causing serious concerns for security-sensitive applications. Thus, it is critical for the community to know whether the newly proposed ViT and MLP-Mixer are also vulnerable to adversarial attacks. To this end, we empirically evaluate their adversarial robustness under several adversarial attack setups and benchmark them against the widely used CNNs. Overall, we find that the two architectures, especially ViT, are more robust than their CNN models. Using a toy example, we also provide empirical evidence that the lower adversarial robustness of CNNs can be partially attributed to their shift-invariant property. Our frequency analysis suggests that the most robust ViT architectures tend to rely more on low-frequency features compared with CNNs. Additionally, we have an intriguing finding that MLP-Mixer is extremely vulnerable to universal adversarial perturbations.
Discover, Hallucinate, and Adapt: Open Compound Domain Adaptation for Semantic Segmentation
Oct 08, 2021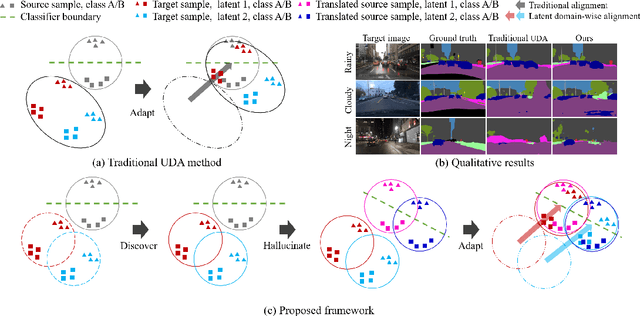
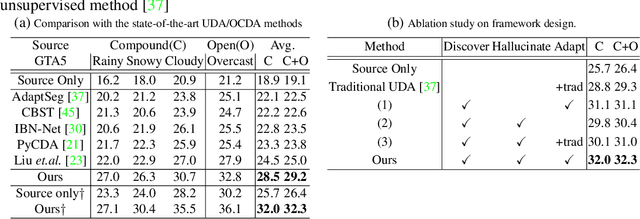
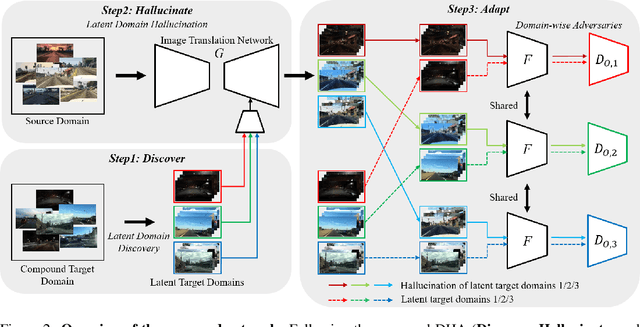
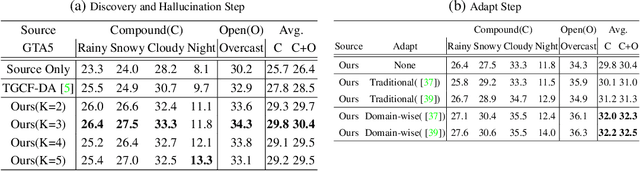
Unsupervised domain adaptation (UDA) for semantic segmentation has been attracting attention recently, as it could be beneficial for various label-scarce real-world scenarios (e.g., robot control, autonomous driving, medical imaging, etc.). Despite the significant progress in this field, current works mainly focus on a single-source single-target setting, which cannot handle more practical settings of multiple targets or even unseen targets. In this paper, we investigate open compound domain adaptation (OCDA), which deals with mixed and novel situations at the same time, for semantic segmentation. We present a novel framework based on three main design principles: discover, hallucinate, and adapt. The scheme first clusters compound target data based on style, discovering multiple latent domains (discover). Then, it hallucinates multiple latent target domains in source by using image-translation (hallucinate). This step ensures the latent domains in the source and the target to be paired. Finally, target-to-source alignment is learned separately between domains (adapt). In high-level, our solution replaces a hard OCDA problem with much easier multiple UDA problems. We evaluate our solution on standard benchmark GTA to C-driving, and achieved new state-of-the-art results.
ACP++: Action Co-occurrence Priors for Human-Object Interaction Detection
Sep 09, 2021
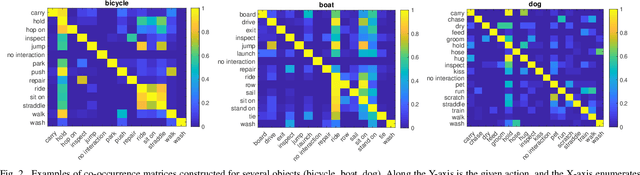
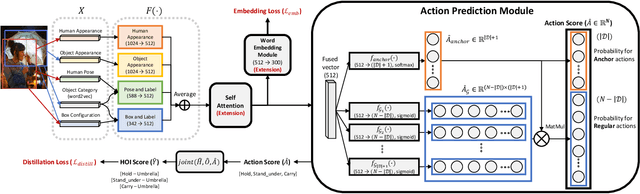

A common problem in the task of human-object interaction (HOI) detection is that numerous HOI classes have only a small number of labeled examples, resulting in training sets with a long-tailed distribution. The lack of positive labels can lead to low classification accuracy for these classes. Towards addressing this issue, we observe that there exist natural correlations and anti-correlations among human-object interactions. In this paper, we model the correlations as action co-occurrence matrices and present techniques to learn these priors and leverage them for more effective training, especially on rare classes. The efficacy of our approach is demonstrated experimentally, where the performance of our approach consistently improves over the state-of-the-art methods on both of the two leading HOI detection benchmark datasets, HICO-Det and V-COCO.
Category-Level Metric Scale Object Shape and Pose Estimation
Sep 01, 2021
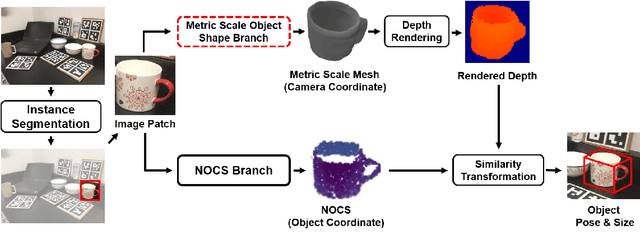
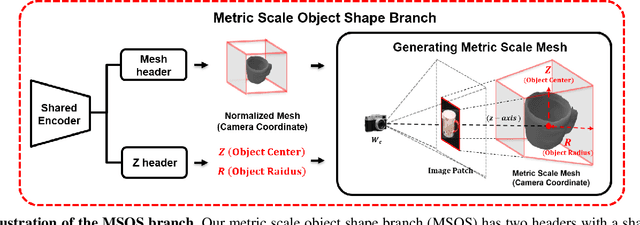
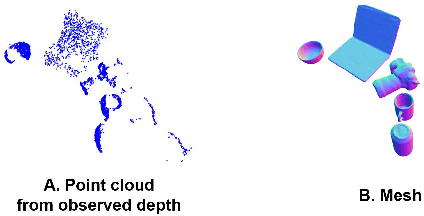
Advances in deep learning recognition have led to accurate object detection with 2D images. However, these 2D perception methods are insufficient for complete 3D world information. Concurrently, advanced 3D shape estimation approaches focus on the shape itself, without considering metric scale. These methods cannot determine the accurate location and orientation of objects. To tackle this problem, we propose a framework that jointly estimates a metric scale shape and pose from a single RGB image. Our framework has two branches: the Metric Scale Object Shape branch (MSOS) and the Normalized Object Coordinate Space branch (NOCS). The MSOS branch estimates the metric scale shape observed in the camera coordinates. The NOCS branch predicts the normalized object coordinate space (NOCS) map and performs similarity transformation with the rendered depth map from a predicted metric scale mesh to obtain 6d pose and size. Additionally, we introduce the Normalized Object Center Estimation (NOCE) to estimate the geometrically aligned distance from the camera to the object center. We validated our method on both synthetic and real-world datasets to evaluate category-level object pose and shape.
VolumeFusion: Deep Depth Fusion for 3D Scene Reconstruction
Aug 19, 2021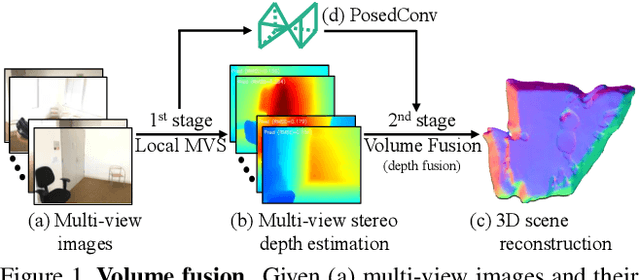
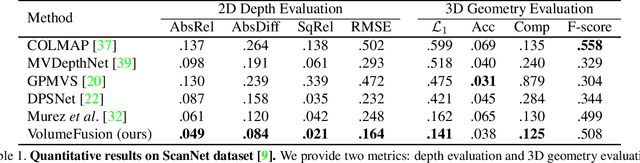
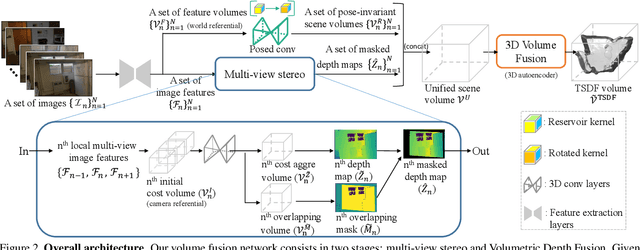

To reconstruct a 3D scene from a set of calibrated views, traditional multi-view stereo techniques rely on two distinct stages: local depth maps computation and global depth maps fusion. Recent studies concentrate on deep neural architectures for depth estimation by using conventional depth fusion method or direct 3D reconstruction network by regressing Truncated Signed Distance Function (TSDF). In this paper, we advocate that replicating the traditional two stages framework with deep neural networks improves both the interpretability and the accuracy of the results. As mentioned, our network operates in two steps: 1) the local computation of the local depth maps with a deep MVS technique, and, 2) the depth maps and images' features fusion to build a single TSDF volume. In order to improve the matching performance between images acquired from very different viewpoints (e.g., large-baseline and rotations), we introduce a rotation-invariant 3D convolution kernel called PosedConv. The effectiveness of the proposed architecture is underlined via a large series of experiments conducted on the ScanNet dataset where our approach compares favorably against both traditional and deep learning techniques.
Learning Open-World Object Proposals without Learning to Classify
Aug 15, 2021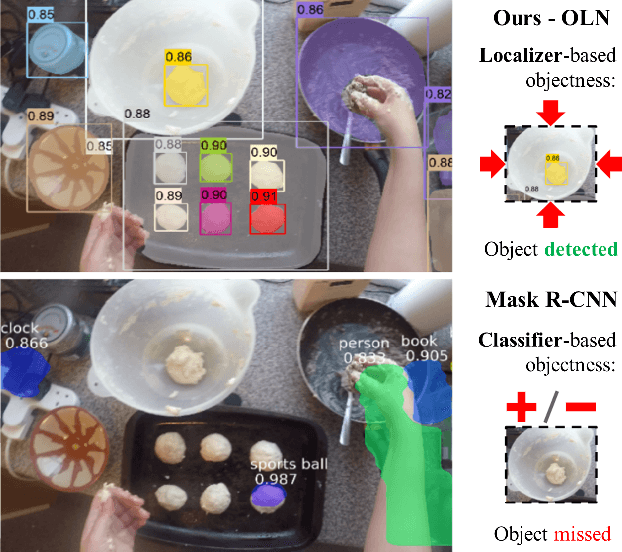
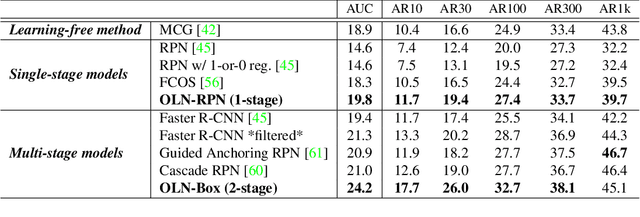
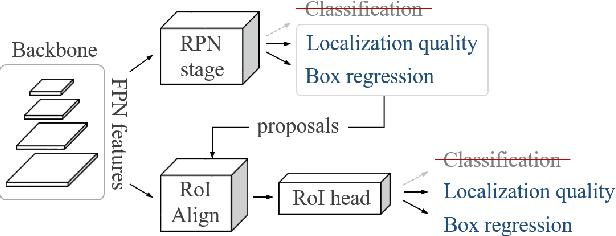
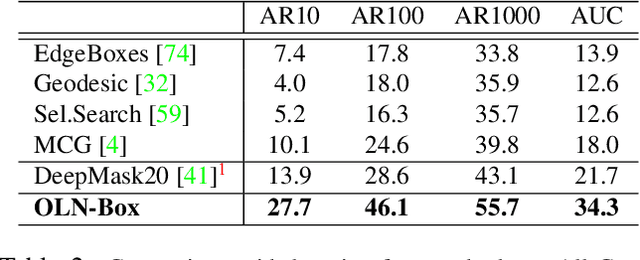
Object proposals have become an integral preprocessing steps of many vision pipelines including object detection, weakly supervised detection, object discovery, tracking, etc. Compared to the learning-free methods, learning-based proposals have become popular recently due to the growing interest in object detection. The common paradigm is to learn object proposals from data labeled with a set of object regions and their corresponding categories. However, this approach often struggles with novel objects in the open world that are absent in the training set. In this paper, we identify that the problem is that the binary classifiers in existing proposal methods tend to overfit to the training categories. Therefore, we propose a classification-free Object Localization Network (OLN) which estimates the objectness of each region purely by how well the location and shape of a region overlap with any ground-truth object (e.g., centerness and IoU). This simple strategy learns generalizable objectness and outperforms existing proposals on cross-category generalization on COCO, as well as cross-dataset evaluation on RoboNet, Object365, and EpicKitchens. Finally, we demonstrate the merit of OLN for long-tail object detection on large vocabulary dataset, LVIS, where we notice clear improvement in rare and common categories.
Correlate-and-Excite: Real-Time Stereo Matching via Guided Cost Volume Excitation
Aug 12, 2021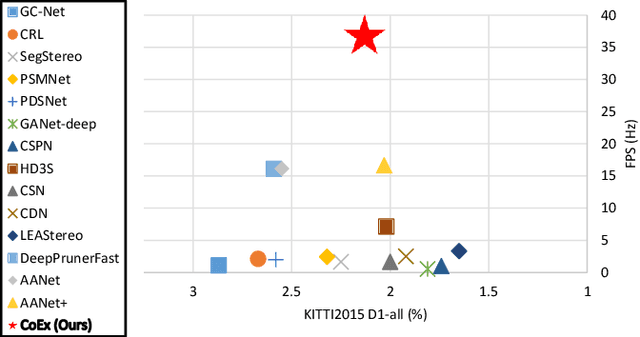
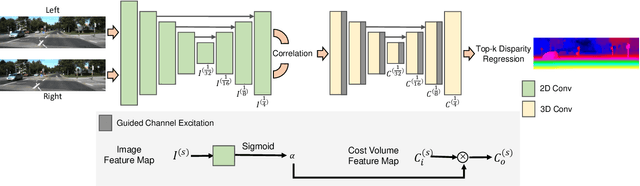

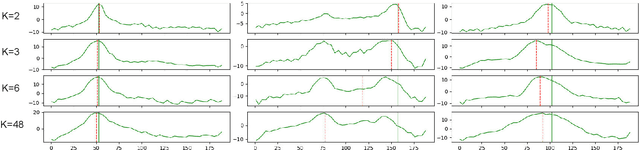
Volumetric deep learning approach towards stereo matching aggregates a cost volume computed from input left and right images using 3D convolutions. Recent works showed that utilization of extracted image features and a spatially varying cost volume aggregation complements 3D convolutions. However, existing methods with spatially varying operations are complex, cost considerable computation time, and cause memory consumption to increase. In this work, we construct Guided Cost volume Excitation (GCE) and show that simple channel excitation of cost volume guided by image can improve performance considerably. Moreover, we propose a novel method of using top-k selection prior to soft-argmin disparity regression for computing the final disparity estimate. Combining our novel contributions, we present an end-to-end network that we call Correlate-and-Excite (CoEx). Extensive experiments of our model on the SceneFlow, KITTI 2012, and KITTI 2015 datasets demonstrate the effectiveness and efficiency of our model and show that our model outperforms other speed-based algorithms while also being competitive to other state-of-the-art algorithms. Codes will be made available at https://github.com/antabangun/coex.
LabOR: Labeling Only if Required for Domain Adaptive Semantic Segmentation
Aug 12, 2021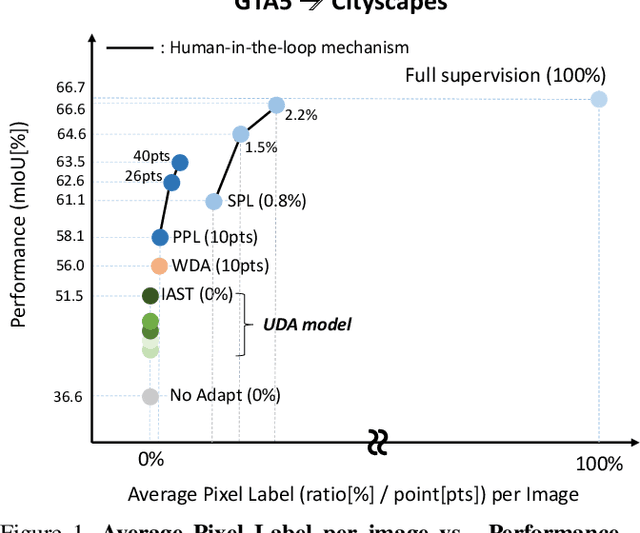
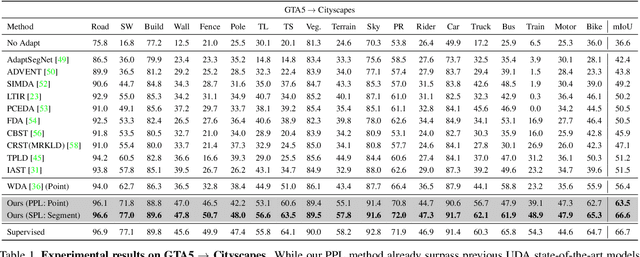
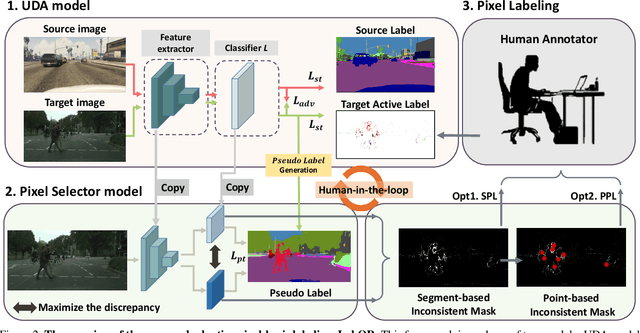
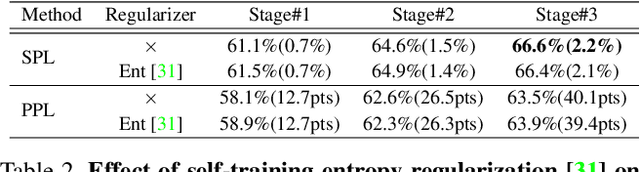
Unsupervised Domain Adaptation (UDA) for semantic segmentation has been actively studied to mitigate the domain gap between label-rich source data and unlabeled target data. Despite these efforts, UDA still has a long way to go to reach the fully supervised performance. To this end, we propose a Labeling Only if Required strategy, LabOR, where we introduce a human-in-the-loop approach to adaptively give scarce labels to points that a UDA model is uncertain about. In order to find the uncertain points, we generate an inconsistency mask using the proposed adaptive pixel selector and we label these segment-based regions to achieve near supervised performance with only a small fraction (about 2.2%) ground truth points, which we call "Segment based Pixel-Labeling (SPL)". To further reduce the efforts of the human annotator, we also propose "Point-based Pixel-Labeling (PPL)", which finds the most representative points for labeling within the generated inconsistency mask. This reduces efforts from 2.2% segment label to 40 points label while minimizing performance degradation. Through extensive experimentation, we show the advantages of this new framework for domain adaptive semantic segmentation while minimizing human labor costs.