 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePropose-and-Attend Single Shot Detector
Jul 30, 2019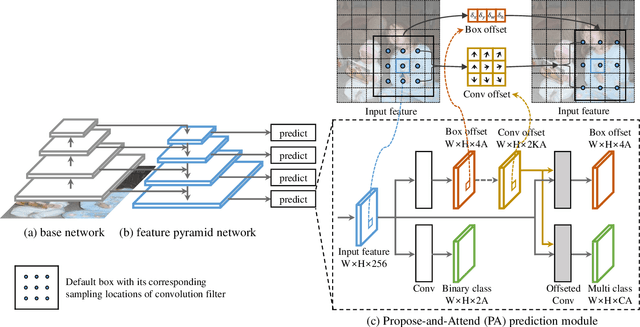

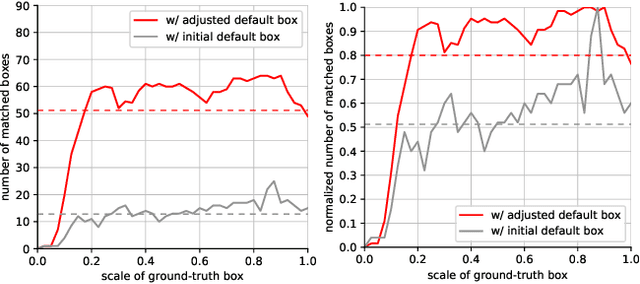
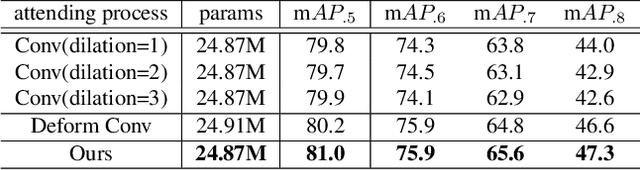
We present a simple yet effective prediction module for a one-stage detector. The main process is conducted in a coarse-to-fine manner. First, the module roughly adjusts the default boxes to well capture the extent of target objects in an image. Second, given the adjusted boxes, the module aligns the receptive field of the convolution filters accordingly, not requiring any embedding layers. Both steps build a propose-and-attend mechanism, mimicking two-stage detectors in a highly efficient manner. To verify its effectiveness, we apply the proposed module to a basic one-stage detector SSD. Our final model achieves an accuracy comparable to that of state-of-the-art detectors while using a fraction of their model parameters and computational overheads. Moreover, we found that the proposed module has two strong applications. 1) The module can be successfully integrated into a lightweight backbone, further pushing the efficiency of the one-stage detector. 2) The module also allows train-from-scratch without relying on any sophisticated base networks as previous methods do.
Camera Exposure Control for Robust Robot Vision with Noise-Aware Image Quality Assessment
Jul 11, 2019



In this paper, we propose a noise-aware exposure control algorithm for robust robot vision. Our method aims to capture the best-exposed image which can boost the performance of various computer vision and robotics tasks. For this purpose, we carefully design an image quality metric which captures complementary quality attributes and ensures light-weight computation. Specifically, our metric consists of a combination of image gradient, entropy, and noise metrics. The synergy of these measures allows preserving sharp edge and rich texture in the image while maintaining a low noise level. Using this novel metric, we propose a real-time and fully automatic exposure and gain control technique based on the Nelder-Mead method. To illustrate the effectiveness of our technique, a large set of experimental results demonstrates higher qualitative and quantitative performances when compared with conventional approaches.
Align-and-Attend Network for Globally and Locally Coherent Video Inpainting
May 30, 2019
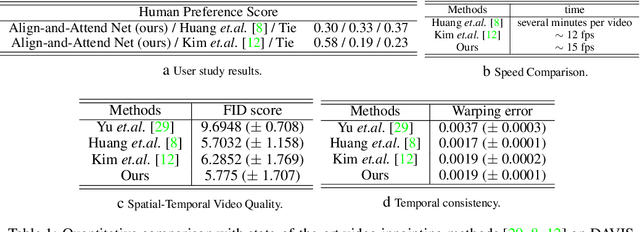
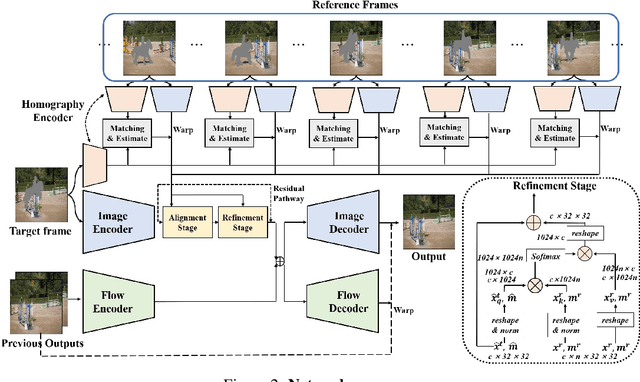

We propose a novel feed-forward network for video inpainting. We use a set of sampled video frames as the reference to take visible contents to fill the hole of a target frame. Our video inpainting network consists of two stages. The first stage is an alignment module that uses computed homographies between the reference frames and the target frame. The visible patches are then aggregated based on the frame similarity to fill in the target holes roughly. The second stage is a non-local attention module that matches the generated patches with known reference patches (in space and time) to refine the previous global alignment stage. Both stages consist of large spatial-temporal window size for the reference and thus enable modeling long-range correlations between distant information and the hole regions. Therefore, even challenging scenes with large or slowly moving holes can be handled, which have been hardly modeled by existing flow-based approach. Our network is also designed with a recurrent propagation stream to encourage temporal consistency in video results. Experiments on video object removal demonstrate that our method inpaints the holes with globally and locally coherent contents.
Learning Loss for Active Learning
May 09, 2019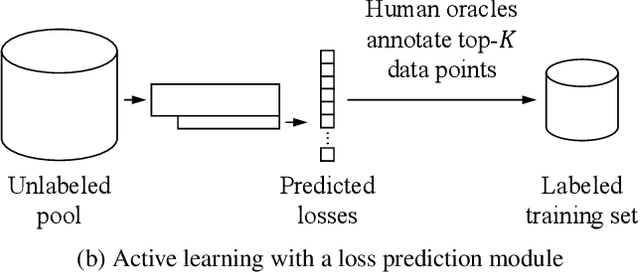
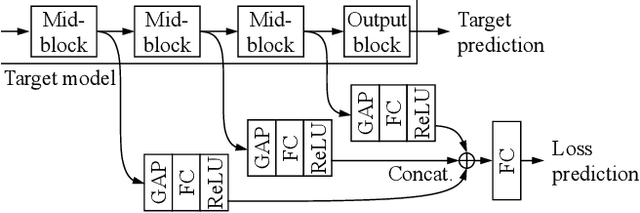
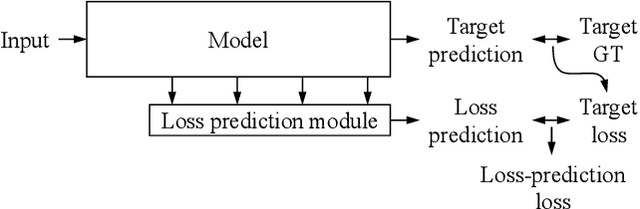
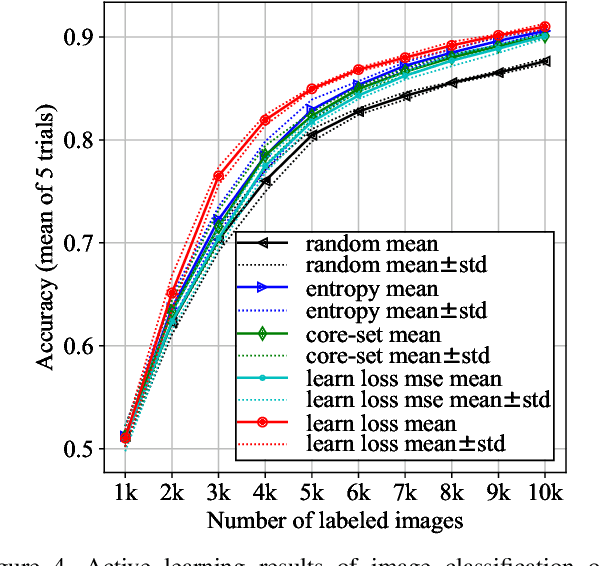
The performance of deep neural networks improves with more annotated data. The problem is that the budget for annotation is limited. One solution to this is active learning, where a model asks human to annotate data that it perceived as uncertain. A variety of recent methods have been proposed to apply active learning to deep networks but most of them are either designed specific for their target tasks or computationally inefficient for large networks. In this paper, we propose a novel active learning method that is simple but task-agnostic, and works efficiently with the deep networks. We attach a small parametric module, named "loss prediction module," to a target network, and learn it to predict target losses of unlabeled inputs. Then, this module can suggest data that the target model is likely to produce a wrong prediction. This method is task-agnostic as networks are learned from a single loss regardless of target tasks. We rigorously validate our method through image classification, object detection, and human pose estimation, with the recent network architectures. The results demonstrate that our method consistently outperforms the previous methods over the tasks.
Deep Blind Video Decaptioning by Temporal Aggregation and Recurrence
May 08, 2019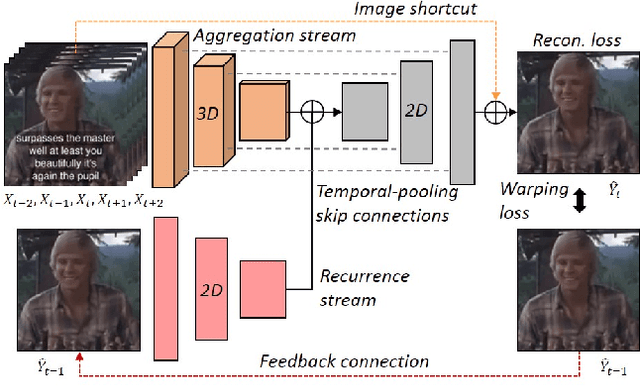

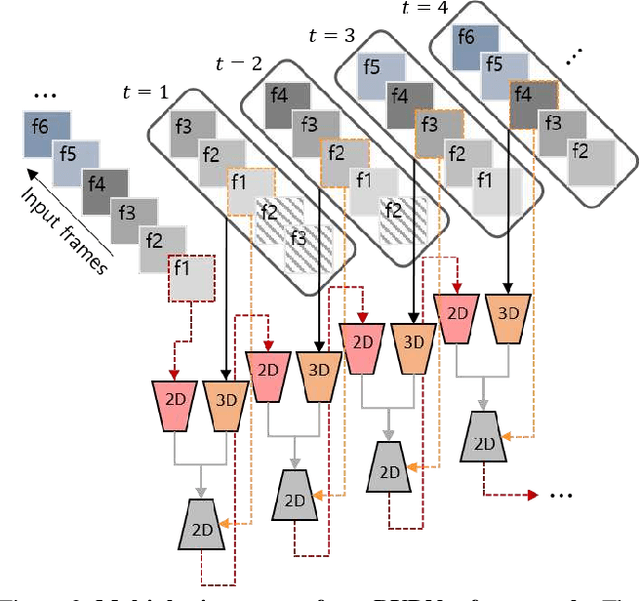
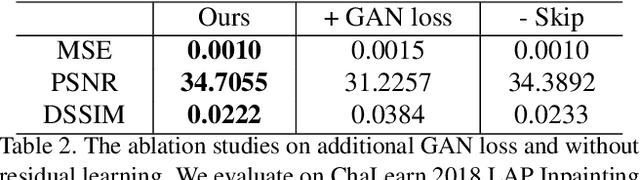
Blind video decaptioning is a problem of automatically removing text overlays and inpainting the occluded parts in videos without any input masks. While recent deep learning based inpainting methods deal with a single image and mostly assume that the positions of the corrupted pixels are known, we aim at automatic text removal in video sequences without mask information. In this paper, we propose a simple yet effective framework for fast blind video decaptioning. We construct an encoder-decoder model, where the encoder takes multiple source frames that can provide visible pixels revealed from the scene dynamics. These hints are aggregated and fed into the decoder. We apply a residual connection from the input frame to the decoder output to enforce our network to focus on the corrupted regions only. Our proposed model was ranked in the first place in the ECCV Chalearn 2018 LAP Inpainting Competition Track2: Video decaptioning. In addition, we further improve this strong model by applying a recurrent feedback. The recurrent feedback not only enforces temporal coherence but also provides strong clues on where the corrupted pixels are. Both qualitative and quantitative experiments demonstrate that our full model produces accurate and temporally consistent video results in real time (50+ fps).
Deep Video Inpainting
May 05, 2019

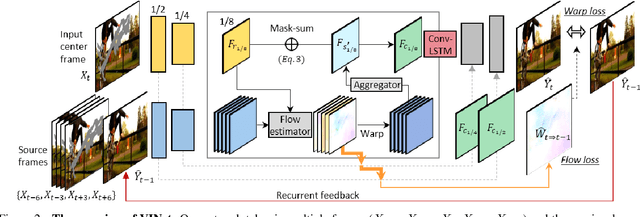

Video inpainting aims to fill spatio-temporal holes with plausible content in a video. Despite tremendous progress of deep neural networks for image inpainting, it is challenging to extend these methods to the video domain due to the additional time dimension. In this work, we propose a novel deep network architecture for fast video inpainting. Built upon an image-based encoder-decoder model, our framework is designed to collect and refine information from neighbor frames and synthesize still-unknown regions. At the same time, the output is enforced to be temporally consistent by a recurrent feedback and a temporal memory module. Compared with the state-of-the-art image inpainting algorithm, our method produces videos that are much more semantically correct and temporally smooth. In contrast to the prior video completion method which relies on time-consuming optimization, our method runs in near real-time while generating competitive video results. Finally, we applied our framework to video retargeting task, and obtain visually pleasing results.
DPSNet: End-to-end Deep Plane Sweep Stereo
May 02, 2019
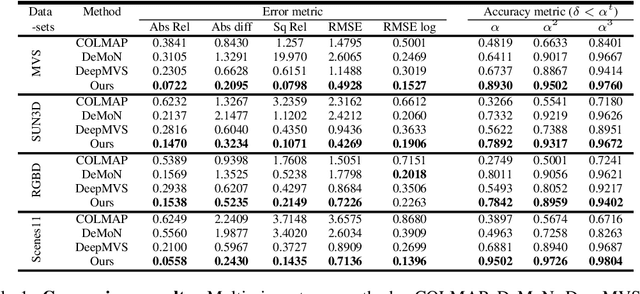
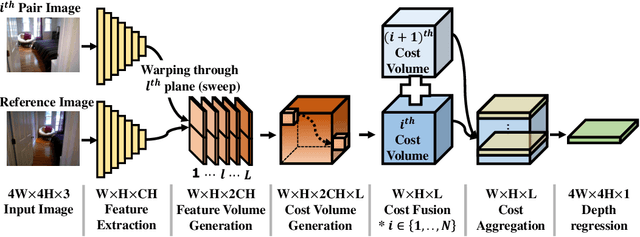
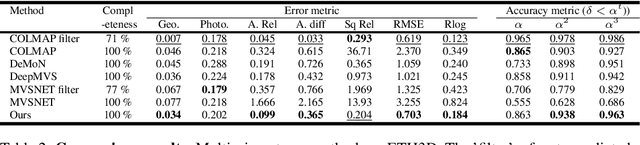
Multiview stereo aims to reconstruct scene depth from images acquired by a camera under arbitrary motion. Recent methods address this problem through deep learning, which can utilize semantic cues to deal with challenges such as textureless and reflective regions. In this paper, we present a convolutional neural network called DPSNet (Deep Plane Sweep Network) whose design is inspired by best practices of traditional geometry-based approaches for dense depth reconstruction. Rather than directly estimating depth and/or optical flow correspondence from image pairs as done in many previous deep learning methods, DPSNet takes a plane sweep approach that involves building a cost volume from deep features using the plane sweep algorithm, regularizing the cost volume via a context-aware cost aggregation, and regressing the dense depth map from the cost volume. The cost volume is constructed using a differentiable warping process that allows for end-to-end training of the network. Through the effective incorporation of conventional multiview stereo concepts within a deep learning framework, DPSNet achieves state-of-the-art reconstruction results on a variety of challenging datasets.
Variational Prototyping-Encoder: One-Shot Learning with Prototypical Images
Apr 17, 2019

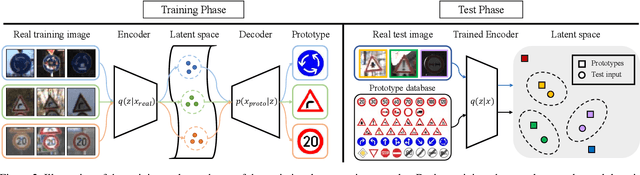
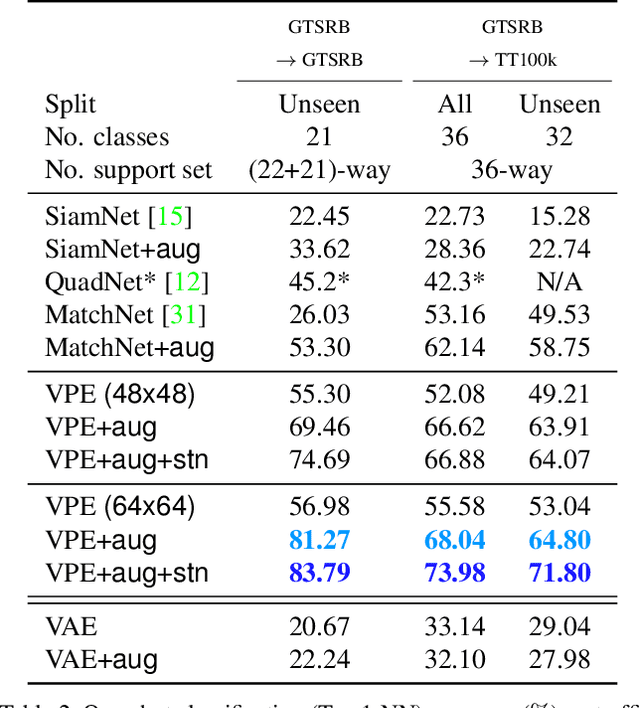
In daily life, graphic symbols, such as traffic signs and brand logos, are ubiquitously utilized around us due to its intuitive expression beyond language boundary. We tackle an open-set graphic symbol recognition problem by one-shot classification with prototypical images as a single training example for each novel class. We take an approach to learn a generalizable embedding space for novel tasks. We propose a new approach called variational prototyping-encoder (VPE) that learns the image translation task from real-world input images to their corresponding prototypical images as a meta-task. As a result, VPE learns image similarity as well as prototypical concepts which differs from widely used metric learning based approaches. Our experiments with diverse datasets demonstrate that the proposed VPE performs favorably against competing metric learning based one-shot methods. Also, our qualitative analyses show that our meta-task induces an effective embedding space suitable for unseen data representation.
Dense Relational Captioning: Triple-Stream Networks for Relationship-Based Captioning
Apr 01, 2019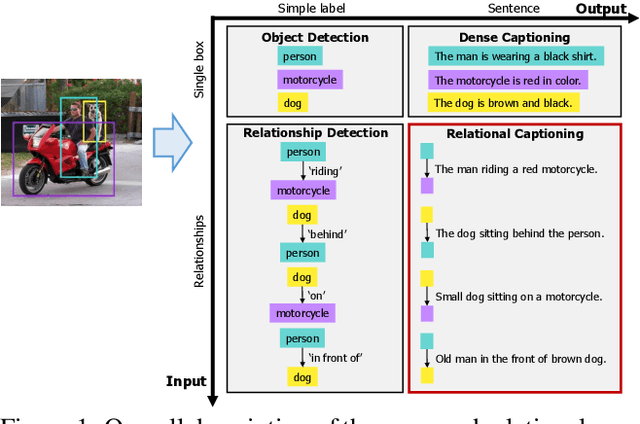
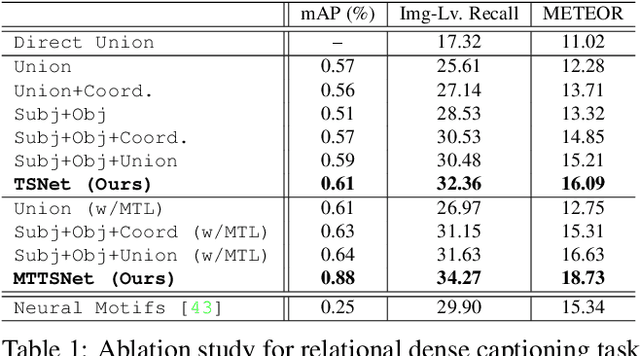
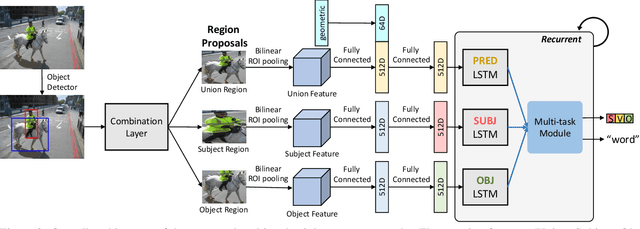
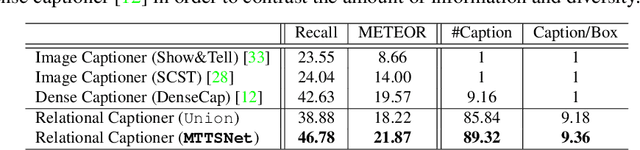
Our goal in this work is to train an image captioning model that generates more dense and informative captions. We introduce "relational captioning," a novel image captioning task which aims to generate multiple captions with respect to relational information between objects in an image. Relational captioning is a framework that is advantageous in both diversity and amount of information, leading to image understanding based on relationships. Part-of speech (POS, i.e. subject-object-predicate categories) tags can be assigned to every English word. We leverage the POS as a prior to guide the correct sequence of words in a caption. To this end, we propose a multi-task triple-stream network (MTTSNet) which consists of three recurrent units for the respective POS and jointly performs POS prediction and captioning. We demonstrate more diverse and richer representations generated by the proposed model against several baselines and competing methods.
Self-Supervised Video Representation Learning with Space-Time Cubic Puzzles
Nov 24, 2018
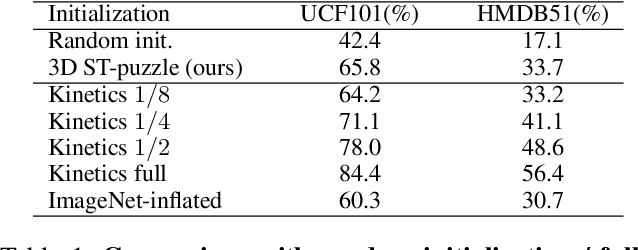
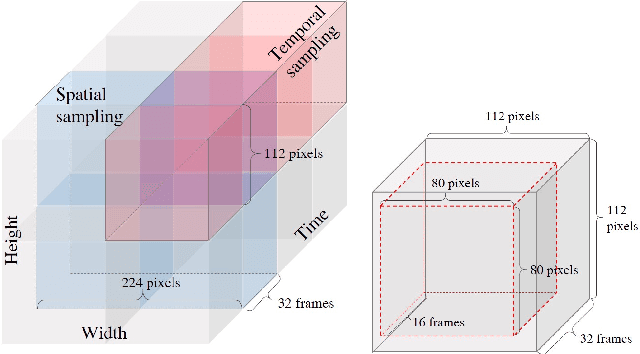

Self-supervised tasks such as colorization, inpainting and zigsaw puzzle have been utilized for visual representation learning for still images, when the number of labeled images is limited or absent at all. Recently, this worthwhile stream of study extends to video domain where the cost of human labeling is even more expensive. However, the most of existing methods are still based on 2D CNN architectures that can not directly capture spatio-temporal information for video applications. In this paper, we introduce a new self-supervised task called as \textit{Space-Time Cubic Puzzles} to train 3D CNNs using large scale video dataset. This task requires a network to arrange permuted 3D spatio-temporal crops. By completing \textit{Space-Time Cubic Puzzles}, the network learns both spatial appearance and temporal relation of video frames, which is our final goal. In experiments, we demonstrate that our learned 3D representation is well transferred to action recognition tasks, and outperforms state-of-the-art 2D CNN-based competitors on UCF101 and HMDB51 datasets.