 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRealistic Zero-Shot Cross-Lingual Transfer in Legal Topic Classification
Jun 08, 2022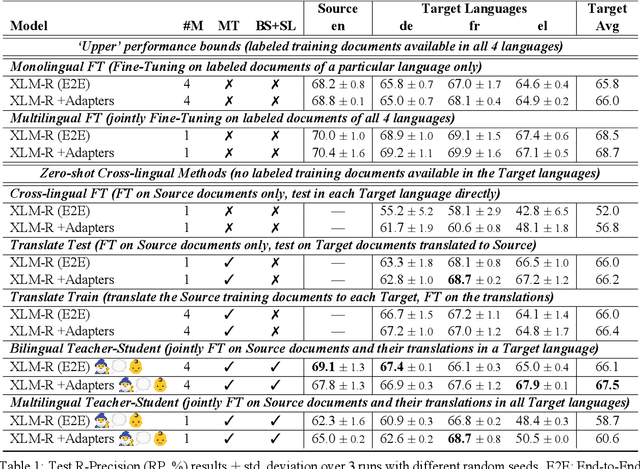
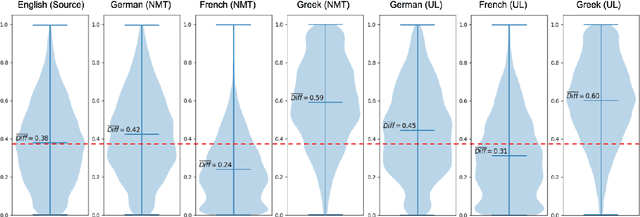
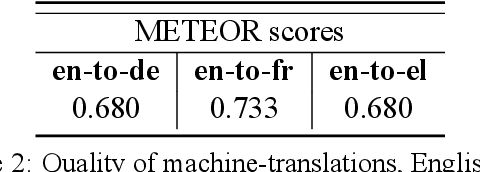
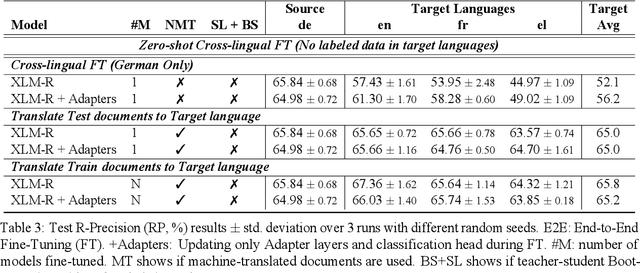
We consider zero-shot cross-lingual transfer in legal topic classification using the recent MultiEURLEX dataset. Since the original dataset contains parallel documents, which is unrealistic for zero-shot cross-lingual transfer, we develop a new version of the dataset without parallel documents. We use it to show that translation-based methods vastly outperform cross-lingual fine-tuning of multilingually pre-trained models, the best previous zero-shot transfer method for MultiEURLEX. We also develop a bilingual teacher-student zero-shot transfer approach, which exploits additional unlabeled documents of the target language and performs better than a model fine-tuned directly on labeled target language documents.
Revisiting Transformer-based Models for Long Document Classification
Apr 14, 2022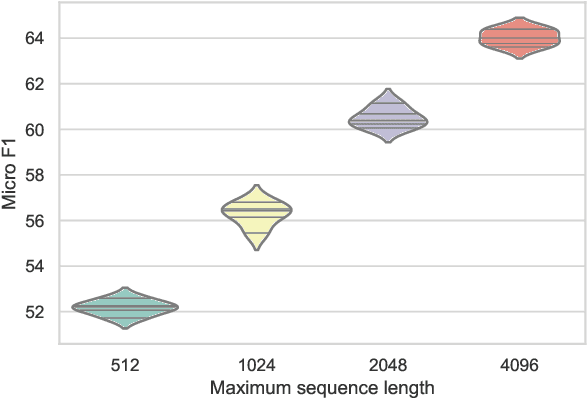
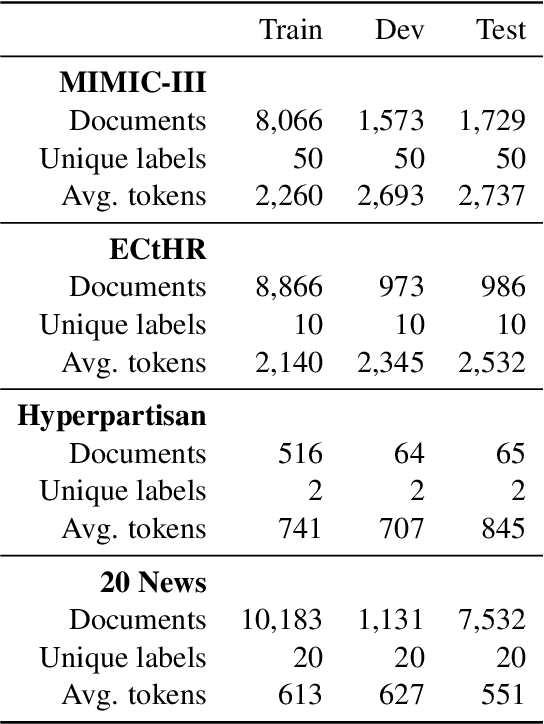
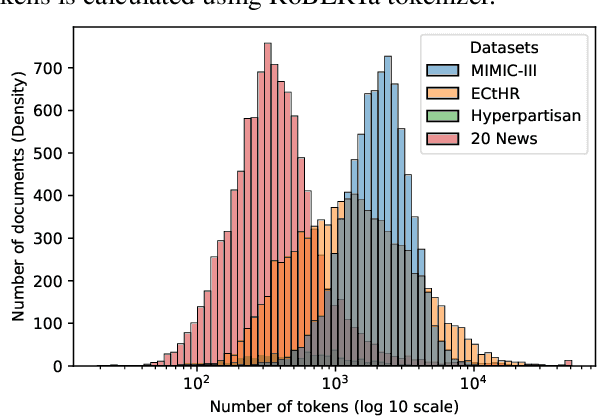
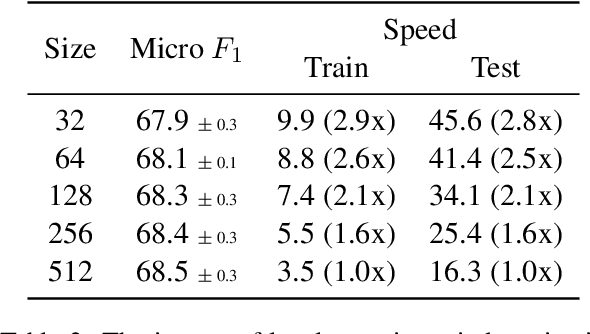
The recent literature in text classification is biased towards short text sequences (e.g., sentences or paragraphs). In real-world applications, multi-page multi-paragraph documents are common and they cannot be efficiently encoded by vanilla Transformer-based models. We compare different Transformer-based Long Document Classification (TrLDC) approaches that aim to mitigate the computational overhead of vanilla transformers to encode much longer text, namely sparse attention and hierarchical encoding methods. We examine several aspects of sparse attention (e.g., size of local attention window, use of global attention) and hierarchical (e.g., document splitting strategy) transformers on four document classification datasets covering different domains. We observe a clear benefit from being able to process longer text, and, based on our results, we derive practical advice of applying Transformer-based models on long document classification tasks.
Challenges and Strategies in Cross-Cultural NLP
Mar 18, 2022
Various efforts in the Natural Language Processing (NLP) community have been made to accommodate linguistic diversity and serve speakers of many different languages. However, it is important to acknowledge that speakers and the content they produce and require, vary not just by language, but also by culture. Although language and culture are tightly linked, there are important differences. Analogous to cross-lingual and multilingual NLP, cross-cultural and multicultural NLP considers these differences in order to better serve users of NLP systems. We propose a principled framework to frame these efforts, and survey existing and potential strategies.
Improved Multi-label Classification under Temporal Concept Drift: Rethinking Group-Robust Algorithms in a Label-Wise Setting
Mar 15, 2022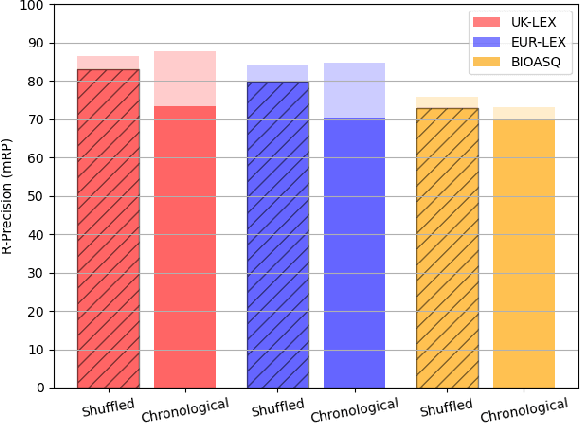

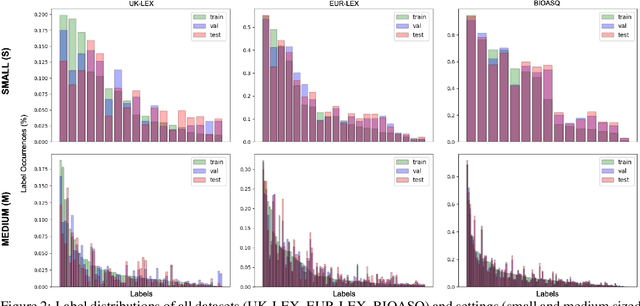
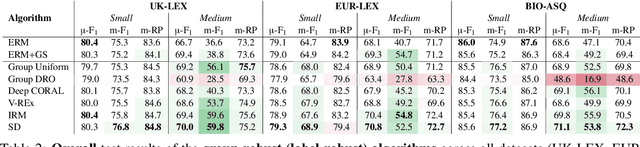
In document classification for, e.g., legal and biomedical text, we often deal with hundreds of classes, including very infrequent ones, as well as temporal concept drift caused by the influence of real world events, e.g., policy changes, conflicts, or pandemics. Class imbalance and drift can sometimes be mitigated by resampling the training data to simulate (or compensate for) a known target distribution, but what if the target distribution is determined by unknown future events? Instead of simply resampling uniformly to hedge our bets, we focus on the underlying optimization algorithms used to train such document classifiers and evaluate several group-robust optimization algorithms, initially proposed to mitigate group-level disparities. Reframing group-robust algorithms as adaptation algorithms under concept drift, we find that Invariant Risk Minimization and Spectral Decoupling outperform sampling-based approaches to class imbalance and concept drift, and lead to much better performance on minority classes. The effect is more pronounced the larger the label set.
FairLex: A Multilingual Benchmark for Evaluating Fairness in Legal Text Processing
Mar 14, 2022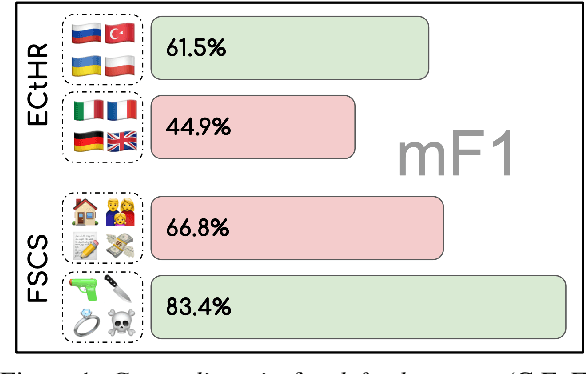

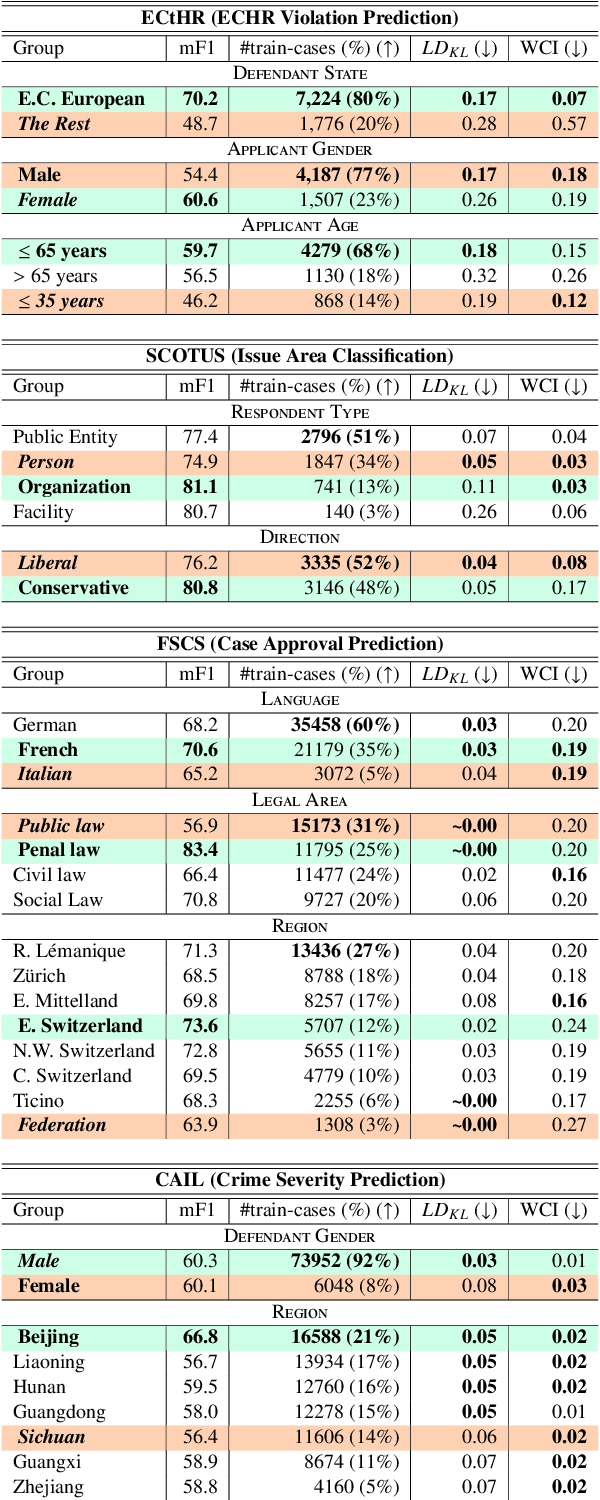

We present a benchmark suite of four datasets for evaluating the fairness of pre-trained language models and the techniques used to fine-tune them for downstream tasks. Our benchmarks cover four jurisdictions (European Council, USA, Switzerland, and China), five languages (English, German, French, Italian and Chinese) and fairness across five attributes (gender, age, region, language, and legal area). In our experiments, we evaluate pre-trained language models using several group-robust fine-tuning techniques and show that performance group disparities are vibrant in many cases, while none of these techniques guarantee fairness, nor consistently mitigate group disparities. Furthermore, we provide a quantitative and qualitative analysis of our results, highlighting open challenges in the development of robustness methods in legal NLP.
FiNER: Financial Numeric Entity Recognition for XBRL Tagging
Mar 12, 2022
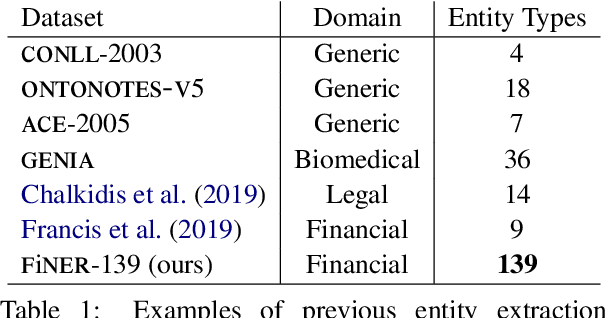
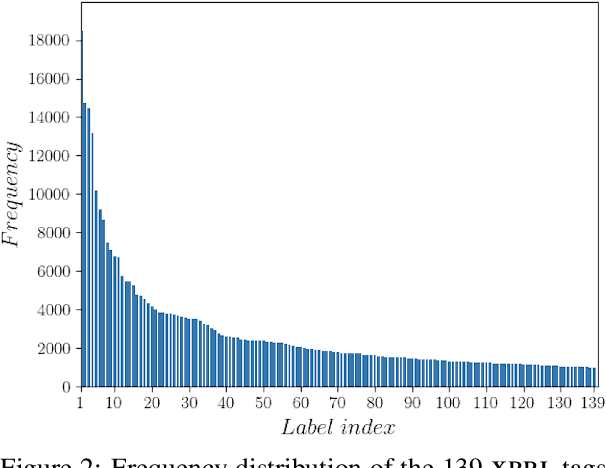
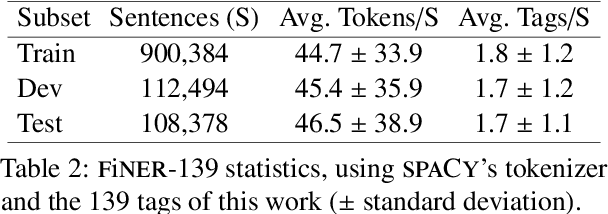
Publicly traded companies are required to submit periodic reports with eXtensive Business Reporting Language (XBRL) word-level tags. Manually tagging the reports is tedious and costly. We, therefore, introduce XBRL tagging as a new entity extraction task for the financial domain and release FiNER-139, a dataset of 1.1M sentences with gold XBRL tags. Unlike typical entity extraction datasets, FiNER-139 uses a much larger label set of 139 entity types. Most annotated tokens are numeric, with the correct tag per token depending mostly on context, rather than the token itself. We show that subword fragmentation of numeric expressions harms BERT's performance, allowing word-level BILSTMs to perform better. To improve BERT's performance, we propose two simple and effective solutions that replace numeric expressions with pseudo-tokens reflecting original token shapes and numeric magnitudes. We also experiment with FIN-BERT, an existing BERT model for the financial domain, and release our own BERT (SEC-BERT), pre-trained on financial filings, which performs best. Through data and error analysis, we finally identify possible limitations to inspire future work on XBRL tagging.
LexGLUE: A Benchmark Dataset for Legal Language Understanding in English
Oct 13, 2021
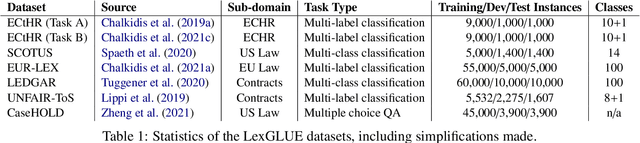

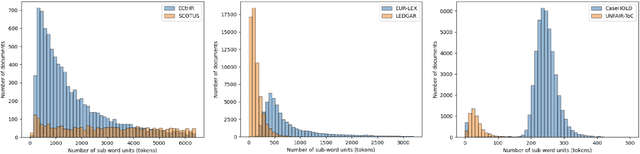
Law, interpretations of law, legal arguments, agreements, etc. are typically expressed in writing, leading to the production of vast corpora of legal text. Their analysis, which is at the center of legal practice, becomes increasingly elaborate as these collections grow in size. Natural language understanding (NLU) technologies can be a valuable tool to support legal practitioners in these endeavors. Their usefulness, however, largely depends on whether current state-of-the-art models can generalize across various tasks in the legal domain. To answer this currently open question, we introduce the Legal General Language Understanding Evaluation (LexGLUE) benchmark, a collection of datasets for evaluating model performance across a diverse set of legal NLU tasks in a standardized way. We also provide an evaluation and analysis of several generic and legal-oriented models demonstrating that the latter consistently offer performance improvements across multiple tasks.
Swiss-Judgment-Prediction: A Multilingual Legal Judgment Prediction Benchmark
Oct 02, 2021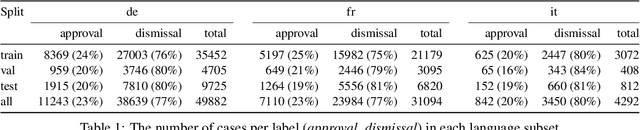
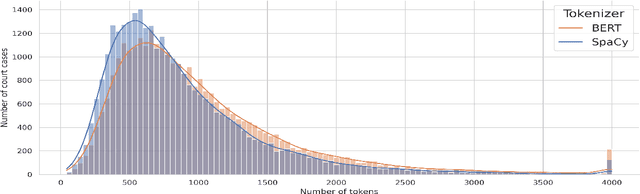
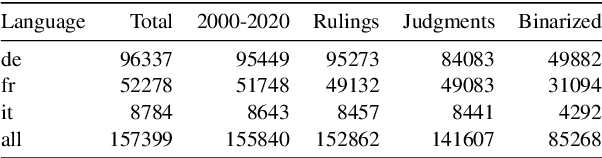
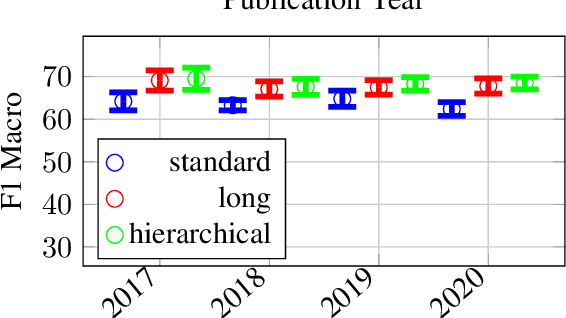
In many jurisdictions, the excessive workload of courts leads to high delays. Suitable predictive AI models can assist legal professionals in their work, and thus enhance and speed up the process. So far, Legal Judgment Prediction (LJP) datasets have been released in English, French, and Chinese. We publicly release a multilingual (German, French, and Italian), diachronic (2000-2020) corpus of 85K cases from the Federal Supreme Court of Switzerland (FSCS). We evaluate state-of-the-art BERT-based methods including two variants of BERT that overcome the BERT input (text) length limitation (up to 512 tokens). Hierarchical BERT has the best performance (approx. 68-70% Macro-F1-Score in German and French). Furthermore, we study how several factors (canton of origin, year of publication, text length, legal area) affect performance. We release both the benchmark dataset and our code to accelerate future research and ensure reproducibility.
Multi-granular Legal Topic Classification on Greek Legislation
Sep 30, 2021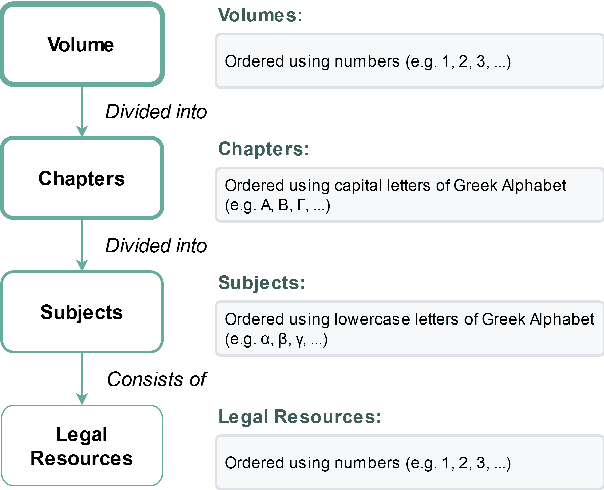
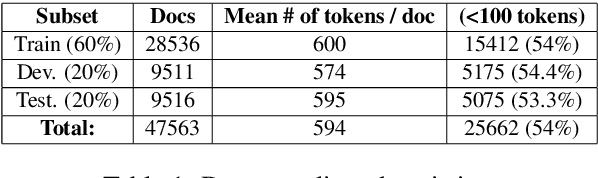
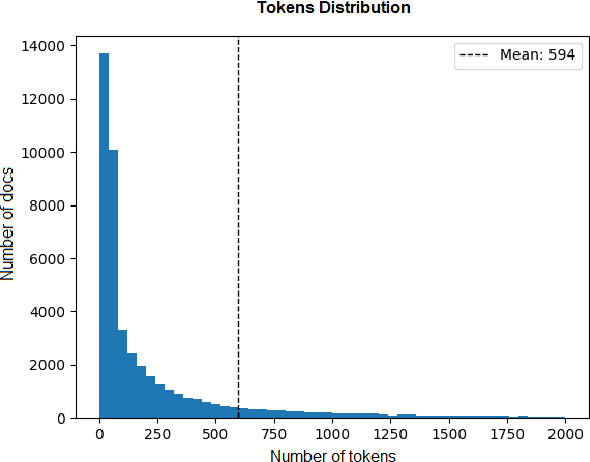
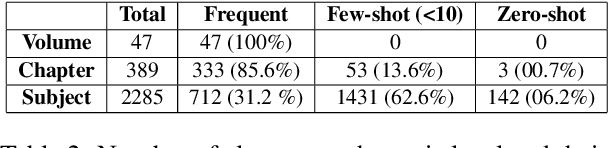
In this work, we study the task of classifying legal texts written in the Greek language. We introduce and make publicly available a novel dataset based on Greek legislation, consisting of more than 47 thousand official, categorized Greek legislation resources. We experiment with this dataset and evaluate a battery of advanced methods and classifiers, ranging from traditional machine learning and RNN-based methods to state-of-the-art Transformer-based methods. We show that recurrent architectures with domain-specific word embeddings offer improved overall performance while being competitive even to transformer-based models. Finally, we show that cutting-edge multilingual and monolingual transformer-based models brawl on the top of the classifiers' ranking, making us question the necessity of training monolingual transfer learning models as a rule of thumb. To the best of our knowledge, this is the first time the task of Greek legal text classification is considered in an open research project, while also Greek is a language with very limited NLP resources in general.
MultiEURLEX -- A multi-lingual and multi-label legal document classification dataset for zero-shot cross-lingual transfer
Sep 06, 2021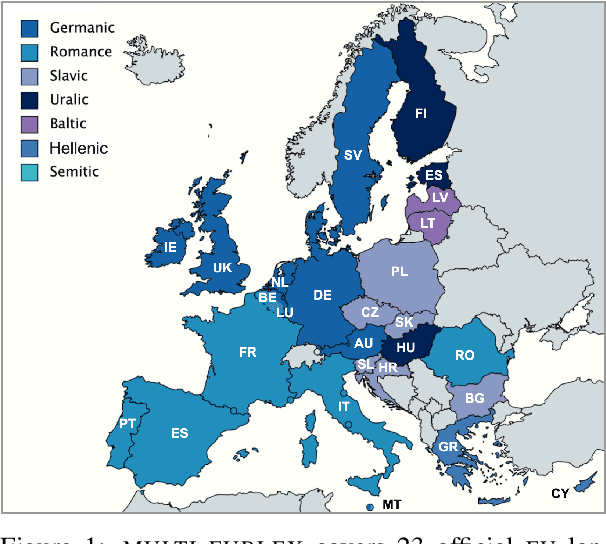
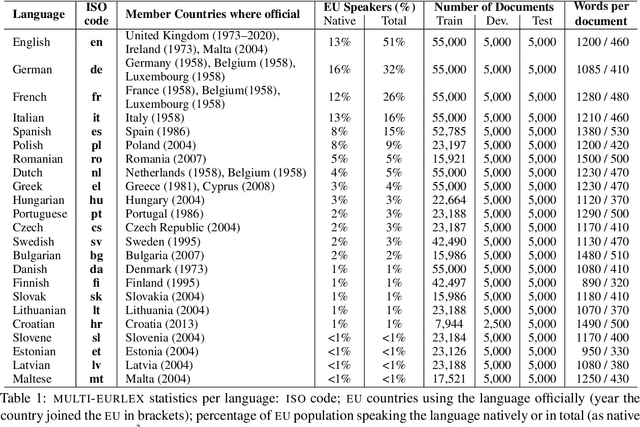
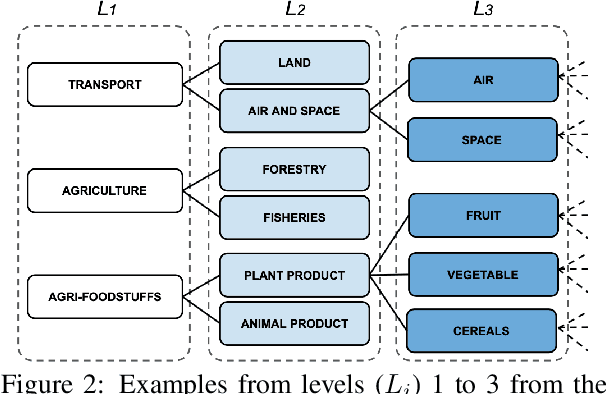
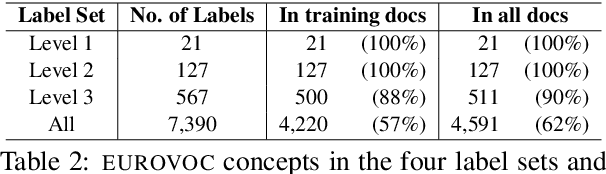
We introduce MULTI-EURLEX, a new multilingual dataset for topic classification of legal documents. The dataset comprises 65k European Union (EU) laws, officially translated in 23 languages, annotated with multiple labels from the EUROVOC taxonomy. We highlight the effect of temporal concept drift and the importance of chronological, instead of random splits. We use the dataset as a testbed for zero-shot cross-lingual transfer, where we exploit annotated training documents in one language (source) to classify documents in another language (target). We find that fine-tuning a multilingually pretrained model (XLM-ROBERTA, MT5) in a single source language leads to catastrophic forgetting of multilingual knowledge and, consequently, poor zero-shot transfer to other languages. Adaptation strategies, namely partial fine-tuning, adapters, BITFIT, LNFIT, originally proposed to accelerate fine-tuning for new end-tasks, help retain multilingual knowledge from pretraining, substantially improving zero-shot cross-lingual transfer, but their impact also depends on the pretrained model used and the size of the label set.