 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreamlining Cross-Document Coreference Resolution: Evaluation and Modeling
Sep 23, 2020

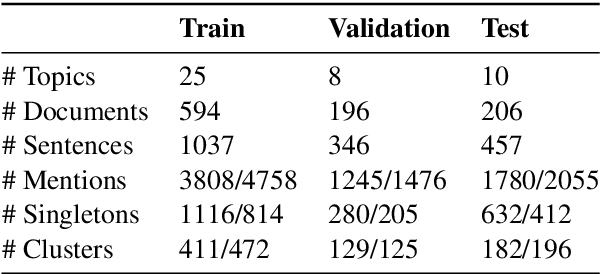
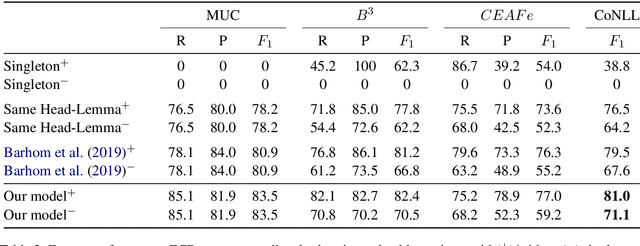
Recent evaluation protocols for Cross-document (CD) coreference resolution have often been inconsistent or lenient, leading to incomparable results across works and overestimation of performance. To facilitate proper future research on this task, our primary contribution is proposing a pragmatic evaluation methodology which assumes access to only raw text -- rather than assuming gold mentions, disregards singleton prediction, and addresses typical targeted settings in CD coreference resolution. Aiming to set baseline results for future research that would follow our evaluation methodology, we build the first end-to-end model for this task. Our model adapts and extends recent neural models for within-document coreference resolution to address the CD coreference setting, which outperforms state-of-the-art results by a significant margin.
Evaluating Interactive Summarization: an Expansion-Based Framework
Sep 17, 2020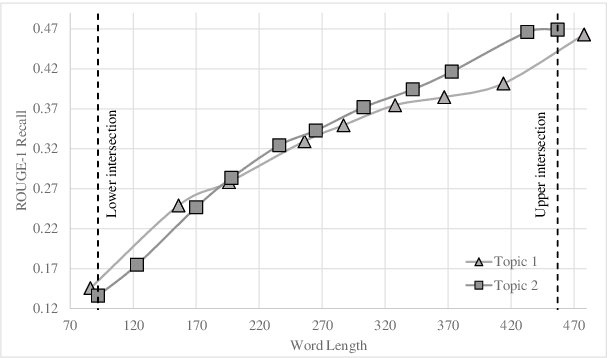
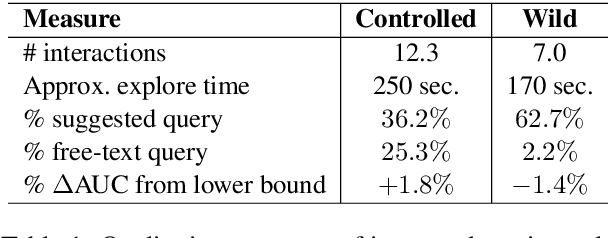

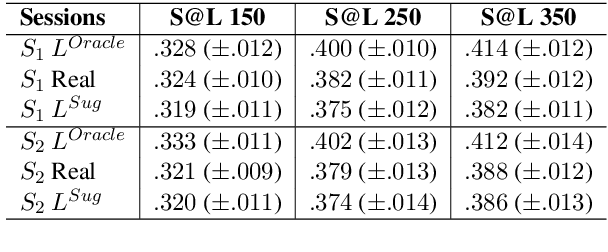
Allowing users to interact with multi-document summarizers is a promising direction towards improving and customizing summary results. Different ideas for interactive summarization have been proposed in previous work but these solutions are highly divergent and incomparable. In this paper, we develop an end-to-end evaluation framework for expansion-based interactive summarization, which considers the accumulating information along an interactive session. Our framework includes a procedure of collecting real user sessions and evaluation measures relying on standards, but adapted to reflect interaction. All of our solutions are intended to be released publicly as a benchmark, allowing comparison of future developments in interactive summarization. We demonstrate the use of our framework by evaluating and comparing baseline implementations that we developed for this purpose, which will serve as part of our benchmark. Our extensive experimentation and analysis of these systems motivate our design choices and support the viability of our framework.
SuperPAL: Supervised Proposition ALignment for Multi-Document Summarization and Derivative Sub-Tasks
Sep 01, 2020

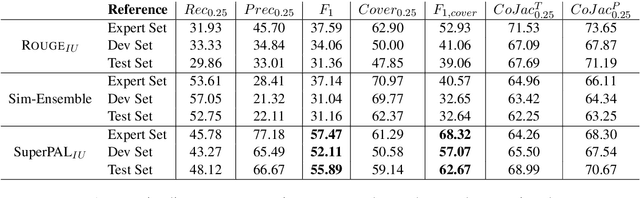
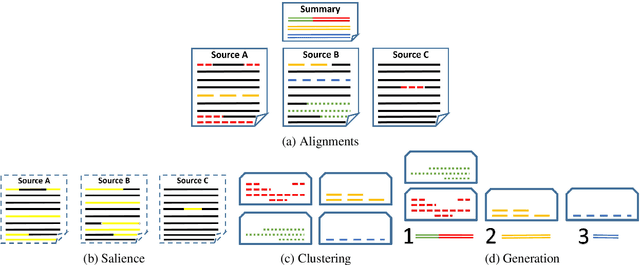
Multi-document summarization (MDS) is a challenging task, often decomposed to subtasks of salience and redundancy detection, followed by generation. While alignment of spans between reference summaries and source documents has been leveraged for training component tasks, the underlying alignment step was never independently addressed or evaluated. We advocate developing high quality source-reference alignment algorithms, that can be applied to recent large-scale datasets to obtain useful "silver", i.e. approximate, training data. As a first step, we present an annotation methodology by which we create gold standard development and test sets for summary-source alignment, and suggest its utility for tuning and evaluating effective alignment algorithms, as well as for properly evaluating MDS subtasks. Second, we introduce a new large-scale alignment dataset for training, with which an automatic alignment model was trained. This aligner achieves higher coherency with the reference summary than previous aligners used for summarization, and gets significantly higher ROUGE results when replacing a simpler aligner in a competitive summarization model. Finally, we release three additional datasets (for salience, clustering and generation), naturally derived from our alignment datasets. Furthermore, these datasets can be derived from any summarization dataset automatically after extracting alignments with our trained aligner. Hence, they can be utilized for training summarization sub-tasks.
Paraphrasing vs Coreferring: Two Sides of the Same Coin
Apr 30, 2020
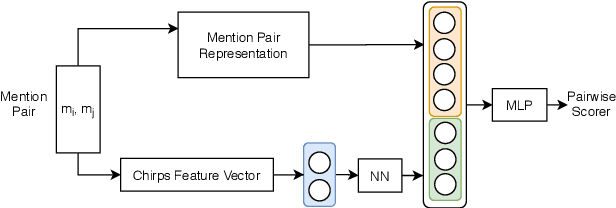

We study the potential synergy between two different NLP tasks, both confronting lexical variability: identifying predicate paraphrases and event coreference resolution. First, we used annotations from an event coreference dataset as distant supervision to re-score heuristically-extracted predicate paraphrases. The new scoring gained more than 18 points in average precision upon their ranking by the original scoring method. Then, we used the same re-ranking features as additional inputs to a state-of-the-art event coreference resolution model, which yielded modest but consistent improvements to the model's performance. The results suggest a promising direction to leverage data and models for each of the tasks to the benefit of the other.
Crowdsourcing a High-Quality Gold Standard for QA-SRL
Nov 08, 2019
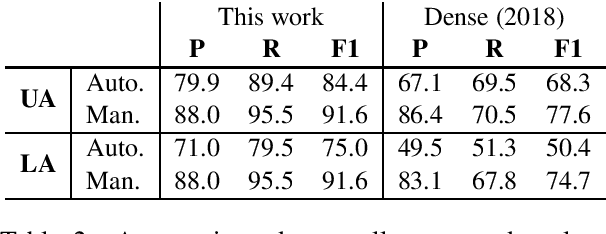
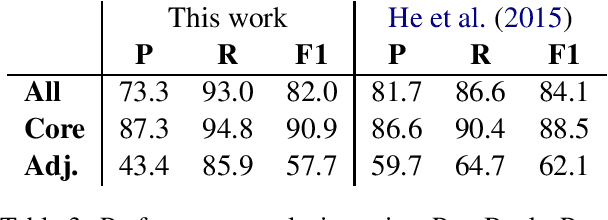
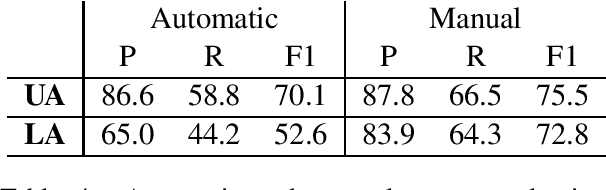
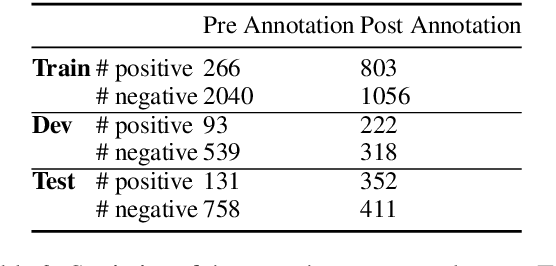
Question-answer driven Semantic Role Labeling (QA-SRL) has been proposed as an attractive open and natural form of SRL, easily crowdsourceable for new corpora. Recently, a large-scale QA-SRL corpus and a trained parser were released, accompanied by a densely annotated dataset for evaluation. Trying to replicate the QA-SRL annotation and evaluation scheme for new texts, we observed that the resulting annotations were lacking in quality and coverage, particularly insufficient for creating gold standards for evaluation. In this paper, we present an improved QA-SRL annotation protocol, involving crowd-worker selection and training, followed by data consolidation. Applying this process, we release a new gold evaluation dataset for QA-SRL, yielding more consistent annotations and greater coverage. We believe that our new annotation protocol and gold standard will facilitate future replicable research of natural semantic annotations.
Diversify Your Datasets: Analyzing Generalization via Controlled Variance in Adversarial Datasets
Oct 21, 2019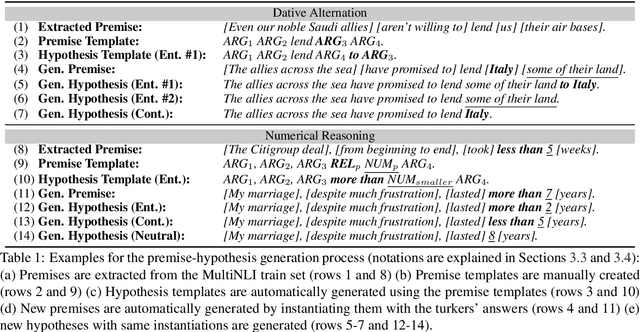
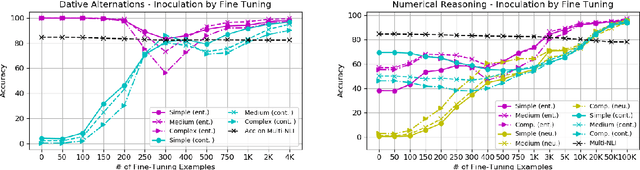
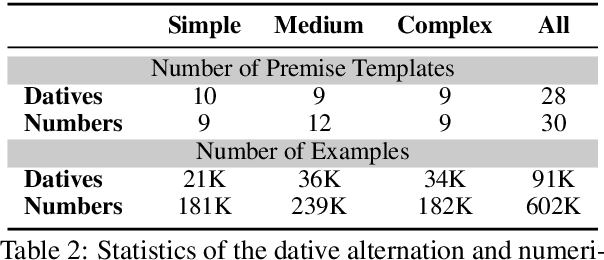
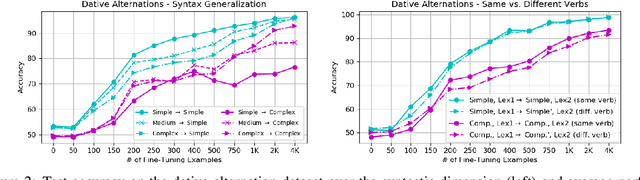
Phenomenon-specific "adversarial" datasets have been recently designed to perform targeted stress-tests for particular inference types. Recent work (Liu et al., 2019a) proposed that such datasets can be utilized for training NLI and other types of models, often allowing to learn the phenomenon in focus and improve on the challenge dataset, indicating a "blind spot" in the original training data. Yet, although a model can improve in such a training process, it might still be vulnerable to other challenge datasets targeting the same phenomenon but drawn from a different distribution, such as having a different syntactic complexity level. In this work, we extend this method to drive conclusions about a model's ability to learn and generalize a target phenomenon rather than to "learn" a dataset, by controlling additional aspects in the adversarial datasets. We demonstrate our approach on two inference phenomena - dative alternation and numerical reasoning, elaborating, and in some cases contradicting, the results of Liu et al.. Our methodology enables building better challenge datasets for creating more robust models, and may yield better model understanding and subsequent overarching improvements.
Improving Quality and Efficiency in Plan-based Neural Data-to-Text Generation
Sep 22, 2019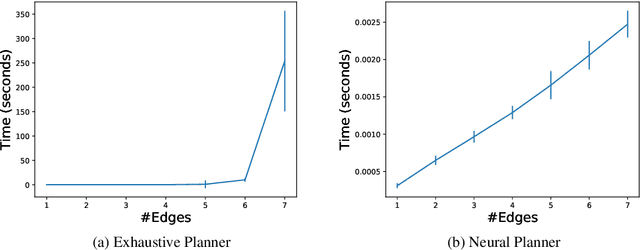
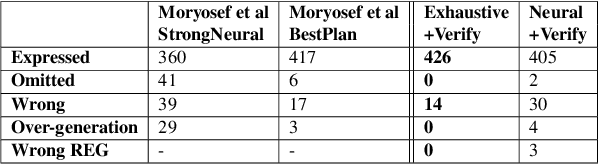

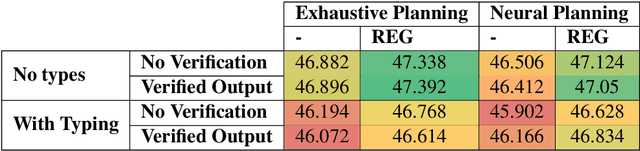
We follow the step-by-step approach to neural data-to-text generation we proposed in Moryossef et al (2019), in which the generation process is divided into a text-planning stage followed by a plan-realization stage. We suggest four extensions to that framework: (1) we introduce a trainable neural planning component that can generate effective plans several orders of magnitude faster than the original planner; (2) we incorporate typing hints that improve the model's ability to deal with unseen relations and entities; (3) we introduce a verification-by-reranking stage that substantially improves the faithfulness of the resulting texts; (4) we incorporate a simple but effective referring expression generation module. These extensions result in a generation process that is faster, more fluent, and more accurate.
ABSApp: A Portable Weakly-Supervised Aspect-Based Sentiment Extraction System
Sep 12, 2019


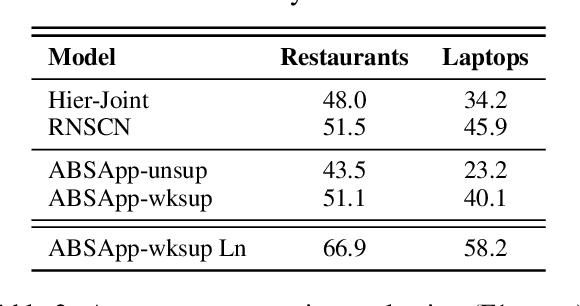
We present ABSApp, a portable system for weakly-supervised aspect-based sentiment extraction. The system is interpretable and user friendly and does not require labeled training data, hence can be rapidly and cost-effectively used across different domains in applied setups. The system flow includes three stages: First, it generates domain-specific aspect and opinion lexicons based on an unlabeled dataset; second, it enables the user to view and edit those lexicons (weak supervision); and finally, it enables the user to select an unlabeled target dataset from the same domain, classify it, and generate an aspect-based sentiment report. ABSApp has been successfully used in a number of real-life use cases, among them movie review analysis and convention impact analysis.
Better Rewards Yield Better Summaries: Learning to Summarise Without References
Sep 03, 2019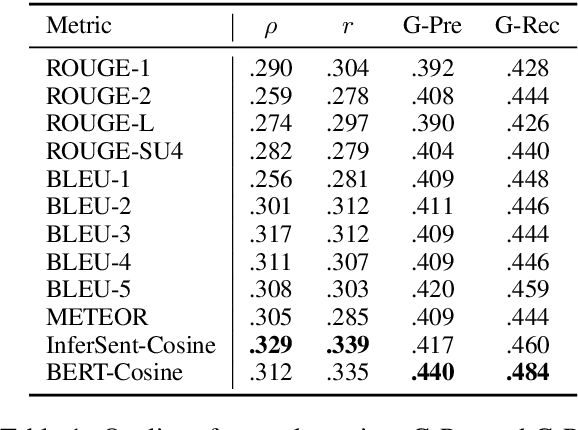
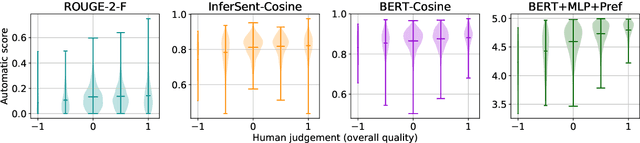
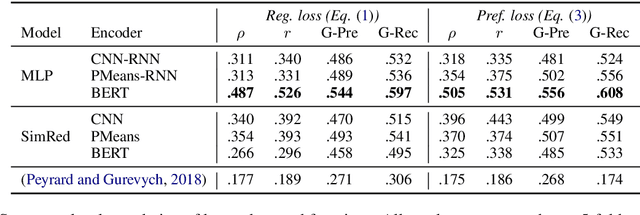
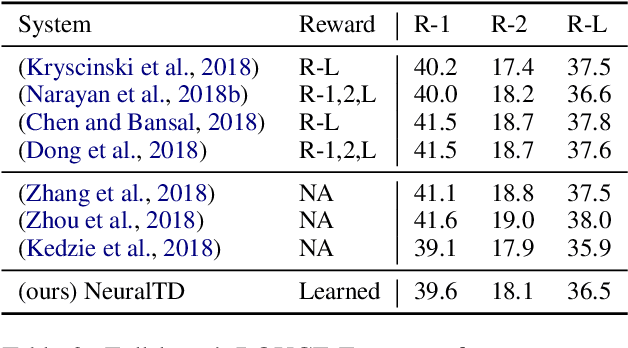
Reinforcement Learning (RL) based document summarisation systems yield state-of-the-art performance in terms of ROUGE scores, because they directly use ROUGE as the rewards during training. However, summaries with high ROUGE scores often receive low human judgement. To find a better reward function that can guide RL to generate human-appealing summaries, we learn a reward function from human ratings on 2,500 summaries. Our reward function only takes the document and system summary as input. Hence, once trained, it can be used to train RL-based summarisation systems without using any reference summaries. We show that our learned rewards have significantly higher correlation with human ratings than previous approaches. Human evaluation experiments show that, compared to the state-of-the-art supervised-learning systems and ROUGE-as-rewards RL summarisation systems, the RL systems using our learned rewards during training generate summarieswith higher human ratings. The learned reward function and our source code are available at https://github.com/yg211/summary-reward-no-reference.
Revisiting Joint Modeling of Cross-document Entity and Event Coreference Resolution
Jun 04, 2019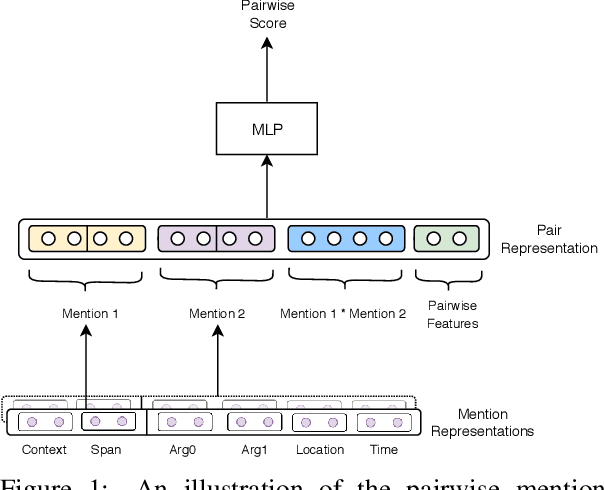


Recognizing coreferring events and entities across multiple texts is crucial for many NLP applications. Despite the task's importance, research focus was given mostly to within-document entity coreference, with rather little attention to the other variants. We propose a neural architecture for cross-document coreference resolution. Inspired by Lee et al (2012), we jointly model entity and event coreference. We represent an event (entity) mention using its lexical span, surrounding context, and relation to entity (event) mentions via predicate-arguments structures. Our model outperforms the previous state-of-the-art event coreference model on ECB+, while providing the first entity coreference results on this corpus. Our analysis confirms that all our representation elements, including the mention span itself, its context, and the relation to other mentions contribute to the model's success.