 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnswering Product-Questions by Utilizing Questions from Other Contextually Similar Products
May 19, 2021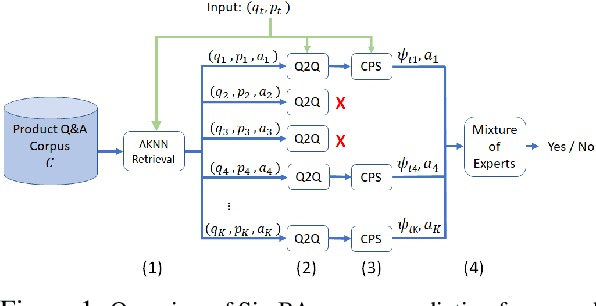
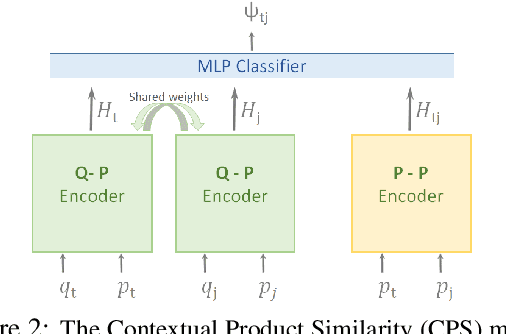


Predicting the answer to a product-related question is an emerging field of research that recently attracted a lot of attention. Answering subjective and opinion-based questions is most challenging due to the dependency on customer-generated content. Previous works mostly focused on review-aware answer prediction; however, these approaches fail for new or unpopular products, having no (or only a few) reviews at hand. In this work, we propose a novel and complementary approach for predicting the answer for such questions, based on the answers for similar questions asked on similar products. We measure the contextual similarity between products based on the answers they provide for the same question. A mixture-of-expert framework is used to predict the answer by aggregating the answers from contextually similar products. Empirical results demonstrate that our model outperforms strong baselines on some segments of questions, namely those that have roughly ten or more similar resolved questions in the corpus. We additionally publish two large-scale datasets used in this work, one is of similar product question pairs, and the second is of product question-answer pairs.
Diversify Your Datasets: Analyzing Generalization via Controlled Variance in Adversarial Datasets
Oct 21, 2019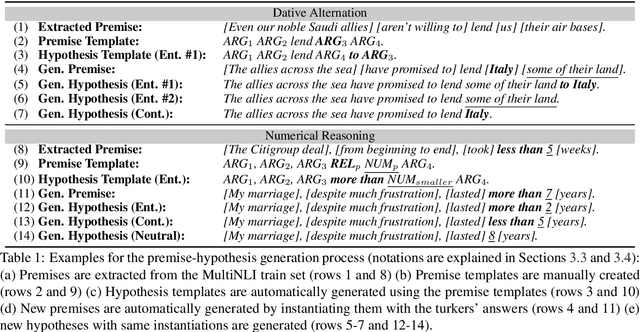
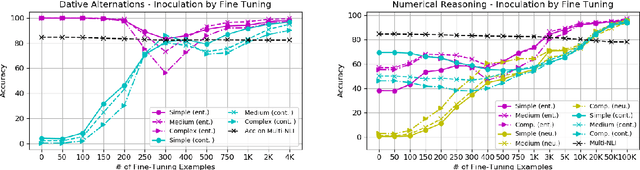
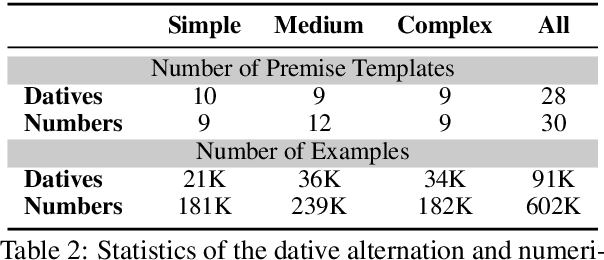
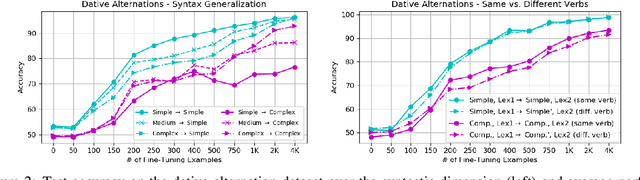
Phenomenon-specific "adversarial" datasets have been recently designed to perform targeted stress-tests for particular inference types. Recent work (Liu et al., 2019a) proposed that such datasets can be utilized for training NLI and other types of models, often allowing to learn the phenomenon in focus and improve on the challenge dataset, indicating a "blind spot" in the original training data. Yet, although a model can improve in such a training process, it might still be vulnerable to other challenge datasets targeting the same phenomenon but drawn from a different distribution, such as having a different syntactic complexity level. In this work, we extend this method to drive conclusions about a model's ability to learn and generalize a target phenomenon rather than to "learn" a dataset, by controlling additional aspects in the adversarial datasets. We demonstrate our approach on two inference phenomena - dative alternation and numerical reasoning, elaborating, and in some cases contradicting, the results of Liu et al.. Our methodology enables building better challenge datasets for creating more robust models, and may yield better model understanding and subsequent overarching improvements.