 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaLI-3 Vision Language Models: Smaller, Faster, Stronger
Oct 17, 2023



This paper presents PaLI-3, a smaller, faster, and stronger vision language model (VLM) that compares favorably to similar models that are 10x larger. As part of arriving at this strong performance, we compare Vision Transformer (ViT) models pretrained using classification objectives to contrastively (SigLIP) pretrained ones. We find that, while slightly underperforming on standard image classification benchmarks, SigLIP-based PaLI shows superior performance across various multimodal benchmarks, especially on localization and visually-situated text understanding. We scale the SigLIP image encoder up to 2 billion parameters, and achieves a new state-of-the-art on multilingual cross-modal retrieval. We hope that PaLI-3, at only 5B parameters, rekindles research on fundamental pieces of complex VLMs, and could fuel a new generation of scaled-up models.
Patch n' Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolution
Jul 12, 2023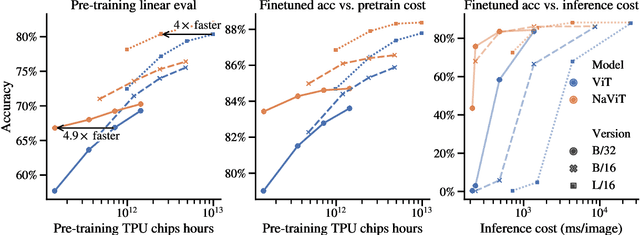
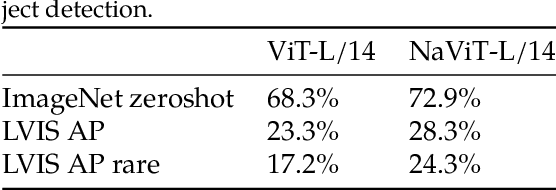
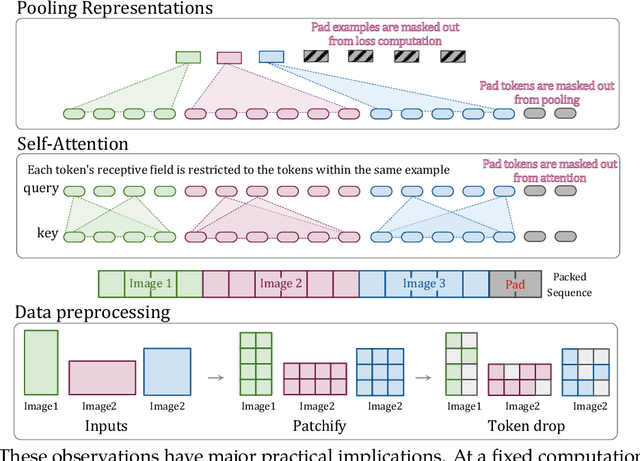
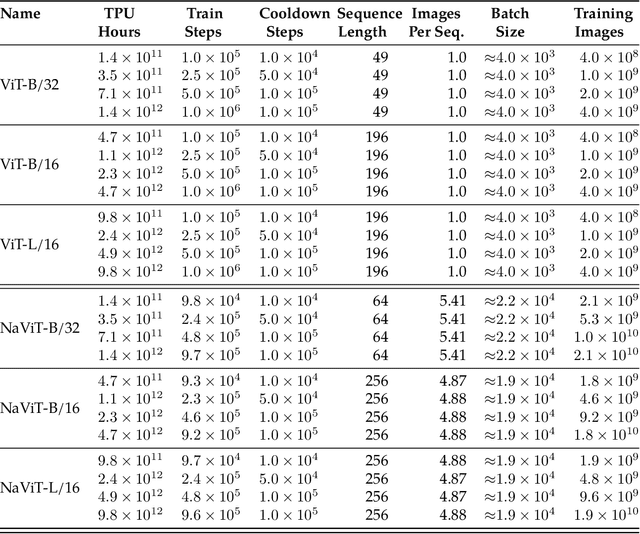
The ubiquitous and demonstrably suboptimal choice of resizing images to a fixed resolution before processing them with computer vision models has not yet been successfully challenged. However, models such as the Vision Transformer (ViT) offer flexible sequence-based modeling, and hence varying input sequence lengths. We take advantage of this with NaViT (Native Resolution ViT) which uses sequence packing during training to process inputs of arbitrary resolutions and aspect ratios. Alongside flexible model usage, we demonstrate improved training efficiency for large-scale supervised and contrastive image-text pretraining. NaViT can be efficiently transferred to standard tasks such as image and video classification, object detection, and semantic segmentation and leads to improved results on robustness and fairness benchmarks. At inference time, the input resolution flexibility can be used to smoothly navigate the test-time cost-performance trade-off. We believe that NaViT marks a departure from the standard, CNN-designed, input and modelling pipeline used by most computer vision models, and represents a promising direction for ViTs.
PaLI-X: On Scaling up a Multilingual Vision and Language Model
May 29, 2023



We present the training recipe and results of scaling up PaLI-X, a multilingual vision and language model, both in terms of size of the components and the breadth of its training task mixture. Our model achieves new levels of performance on a wide-range of varied and complex tasks, including multiple image-based captioning and question-answering tasks, image-based document understanding and few-shot (in-context) learning, as well as object detection, video question answering, and video captioning. PaLI-X advances the state-of-the-art on most vision-and-language benchmarks considered (25+ of them). Finally, we observe emerging capabilities, such as complex counting and multilingual object detection, tasks that are not explicitly in the training mix.
Getting ViT in Shape: Scaling Laws for Compute-Optimal Model Design
May 22, 2023



Scaling laws have been recently employed to derive compute-optimal model size (number of parameters) for a given compute duration. We advance and refine such methods to infer compute-optimal model shapes, such as width and depth, and successfully implement this in vision transformers. Our shape-optimized vision transformer, SoViT, achieves results competitive with models that exceed twice its size, despite being pre-trained with an equivalent amount of compute. For example, SoViT-400m/14 achieves 90.3% fine-tuning accuracy on ILSRCV2012, surpassing the much larger ViT-g/14 and approaching ViT-G/14 under identical settings, with also less than half the inference cost. We conduct a thorough evaluation across multiple tasks, such as image classification, captioning, VQA and zero-shot transfer, demonstrating the effectiveness of our model across a broad range of domains and identifying limitations. Overall, our findings challenge the prevailing approach of blindly scaling up vision models and pave a path for a more informed scaling.
Scaling Vision Transformers to 22 Billion Parameters
Feb 10, 2023



The scaling of Transformers has driven breakthrough capabilities for language models. At present, the largest large language models (LLMs) contain upwards of 100B parameters. Vision Transformers (ViT) have introduced the same architecture to image and video modelling, but these have not yet been successfully scaled to nearly the same degree; the largest dense ViT contains 4B parameters (Chen et al., 2022). We present a recipe for highly efficient and stable training of a 22B-parameter ViT (ViT-22B) and perform a wide variety of experiments on the resulting model. When evaluated on downstream tasks (often with a lightweight linear model on frozen features), ViT-22B demonstrates increasing performance with scale. We further observe other interesting benefits of scale, including an improved tradeoff between fairness and performance, state-of-the-art alignment to human visual perception in terms of shape/texture bias, and improved robustness. ViT-22B demonstrates the potential for "LLM-like" scaling in vision, and provides key steps towards getting there.
Adapting to Latent Subgroup Shifts via Concepts and Proxies
Dec 21, 2022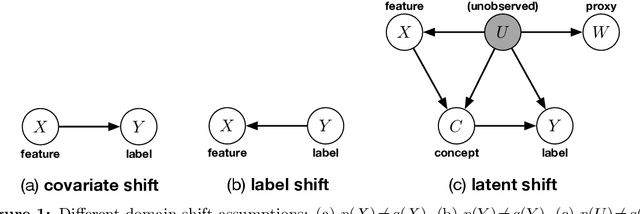

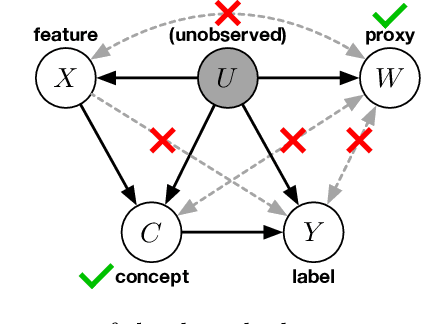
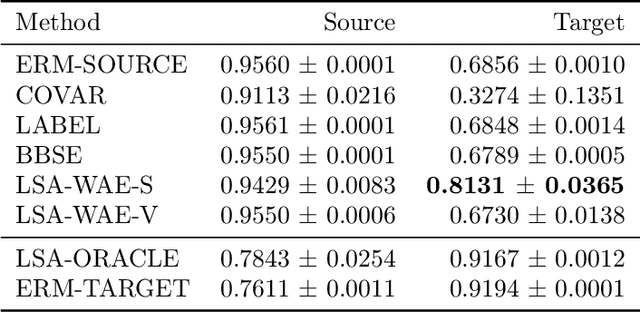
We address the problem of unsupervised domain adaptation when the source domain differs from the target domain because of a shift in the distribution of a latent subgroup. When this subgroup confounds all observed data, neither covariate shift nor label shift assumptions apply. We show that the optimal target predictor can be non-parametrically identified with the help of concept and proxy variables available only in the source domain, and unlabeled data from the target. The identification results are constructive, immediately suggesting an algorithm for estimating the optimal predictor in the target. For continuous observations, when this algorithm becomes impractical, we propose a latent variable model specific to the data generation process at hand. We show how the approach degrades as the size of the shift changes, and verify that it outperforms both covariate and label shift adjustment.
FlexiViT: One Model for All Patch Sizes
Dec 15, 2022



Vision Transformers convert images to sequences by slicing them into patches. The size of these patches controls a speed/accuracy tradeoff, with smaller patches leading to higher accuracy at greater computational cost, but changing the patch size typically requires retraining the model. In this paper, we demonstrate that simply randomizing the patch size at training time leads to a single set of weights that performs well across a wide range of patch sizes, making it possible to tailor the model to different compute budgets at deployment time. We extensively evaluate the resulting model, which we call FlexiViT, on a wide range of tasks, including classification, image-text retrieval, open-world detection, panoptic segmentation, and semantic segmentation, concluding that it usually matches, and sometimes outperforms, standard ViT models trained at a single patch size in an otherwise identical setup. Hence, FlexiViT training is a simple drop-in improvement for ViT that makes it easy to add compute-adaptive capabilities to most models relying on a ViT backbone architecture. Code and pre-trained models are available at https://github.com/google-research/big_vision
Layer-Stack Temperature Scaling
Nov 18, 2022



Recent works demonstrate that early layers in a neural network contain useful information for prediction. Inspired by this, we show that extending temperature scaling across all layers improves both calibration and accuracy. We call this procedure "layer-stack temperature scaling" (LATES). Informally, LATES grants each layer a weighted vote during inference. We evaluate it on five popular convolutional neural network architectures both in- and out-of-distribution and observe a consistent improvement over temperature scaling in terms of accuracy, calibration, and AUC. All conclusions are supported by comprehensive statistical analyses. Since LATES neither retrains the architecture nor introduces many more parameters, its advantages can be reaped without requiring additional data beyond what is used in temperature scaling. Finally, we show that combining LATES with Monte Carlo Dropout matches state-of-the-art results on CIFAR10/100.
Revisiting Neural Scaling Laws in Language and Vision
Sep 13, 2022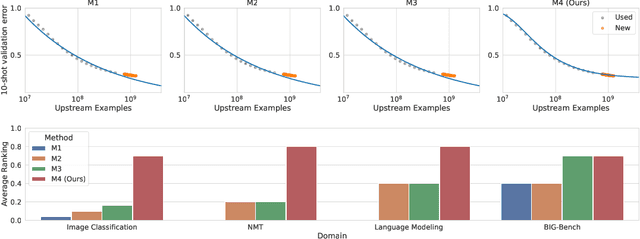
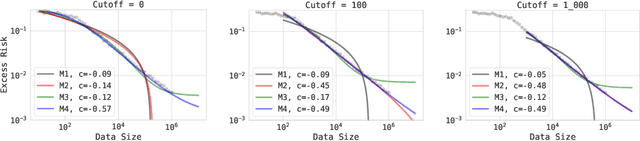
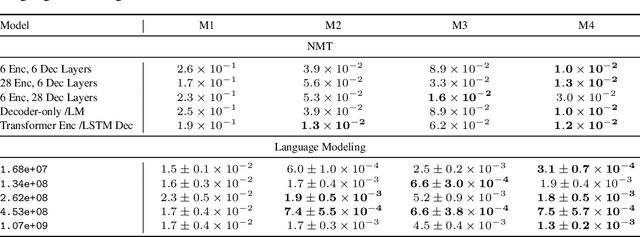
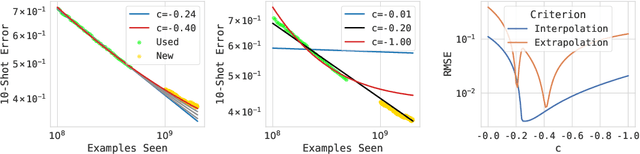
The remarkable progress in deep learning in recent years is largely driven by improvements in scale, where bigger models are trained on larger datasets for longer schedules. To predict the benefit of scale empirically, we argue for a more rigorous methodology based on the extrapolation loss, instead of reporting the best-fitting (interpolating) parameters. We then present a recipe for estimating scaling law parameters reliably from learning curves. We demonstrate that it extrapolates more accurately than previous methods in a wide range of architecture families across several domains, including image classification, neural machine translation (NMT) and language modeling, in addition to tasks from the BIG-Bench evaluation benchmark. Finally, we release a benchmark dataset comprising of 90 evaluation tasks to facilitate research in this domain.
A Reduction to Binary Approach for Debiasing Multiclass Datasets
May 31, 2022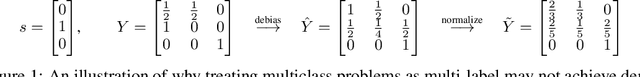
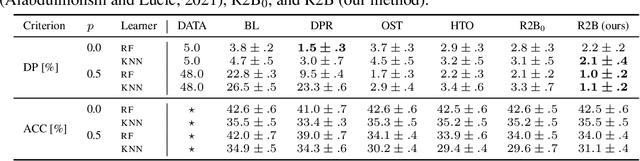
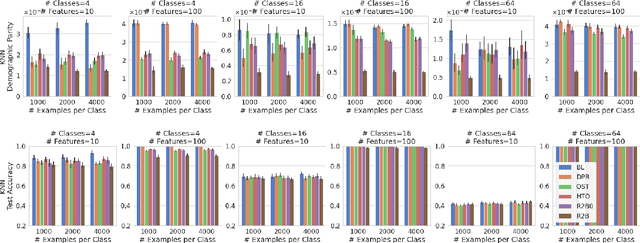

We propose a novel reduction-to-binary (R2B) approach that enforces demographic parity for multiclass classification with non-binary sensitive attributes via a reduction to a sequence of binary debiasing tasks. We prove that R2B satisfies optimality and bias guarantees and demonstrate empirically that it can lead to an improvement over two baselines: (1) treating multiclass problems as multi-label by debiasing labels independently and (2) transforming the features instead of the labels. Surprisingly, we also demonstrate that independent label debiasing yields competitive results in most (but not all) settings. We validate these conclusions on synthetic and real-world datasets from social science, computer vision, and healthcare.