 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGILBO: One Metric to Measure Them All
Oct 27, 2018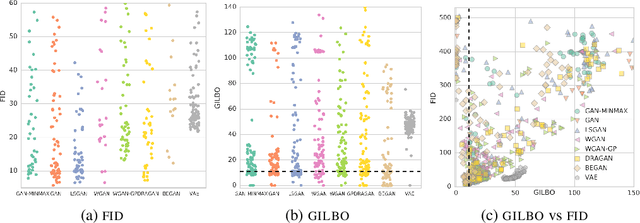
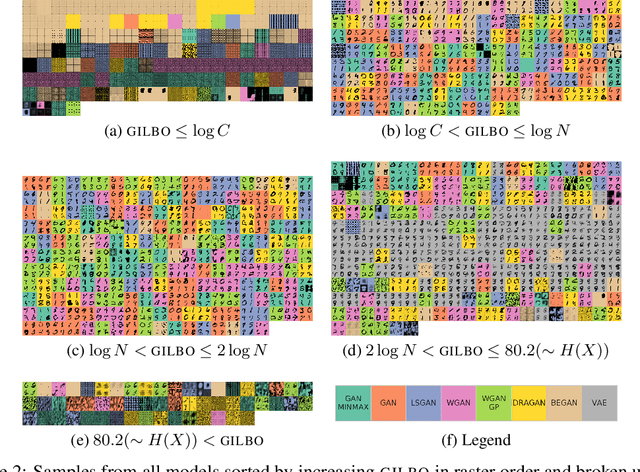
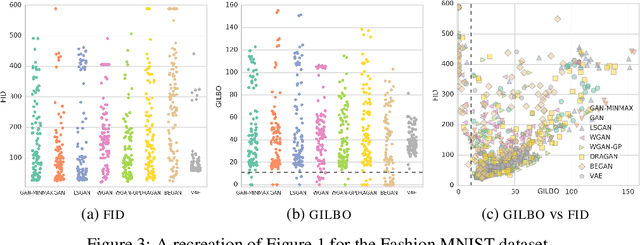
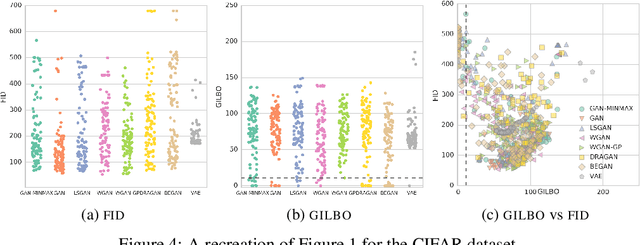
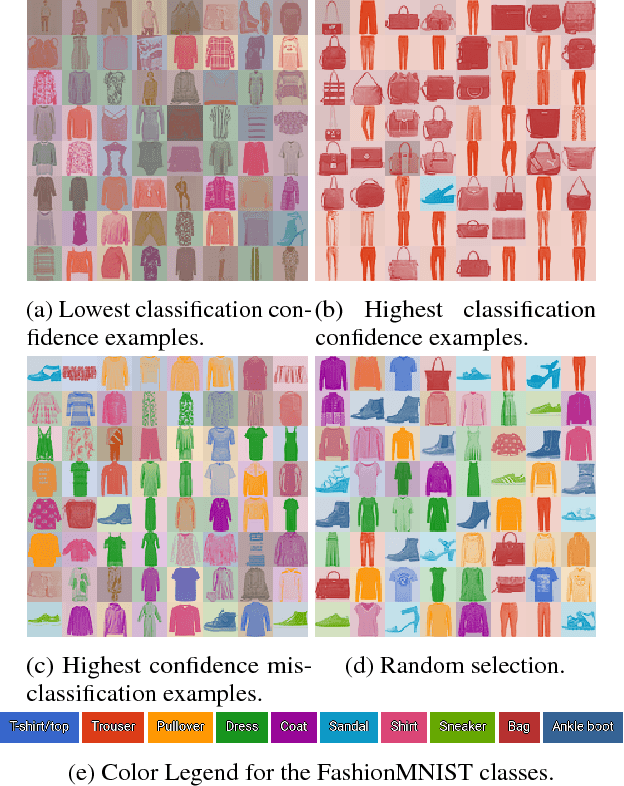
We propose a simple, tractable lower bound on the mutual information contained in the joint generative density of any latent variable generative model: the GILBO (Generative Information Lower BOund). It offers a data-independent measure of the complexity of the learned latent variable description, giving the log of the effective description length. It is well-defined for both VAEs and GANs. We compute the GILBO for 800 GANs and VAEs each trained on four datasets (MNIST, FashionMNIST, CIFAR-10 and CelebA) and discuss the results.
TherML: Thermodynamics of Machine Learning
Oct 04, 2018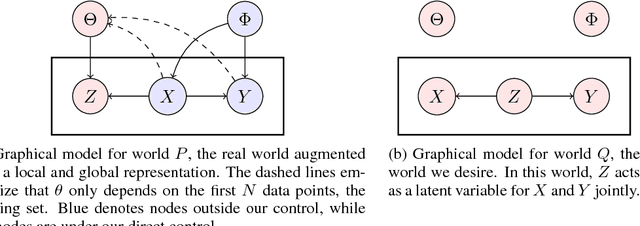
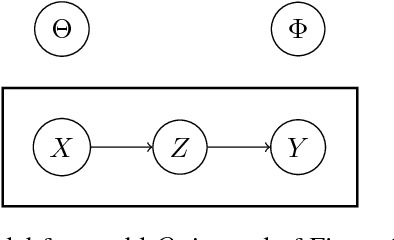
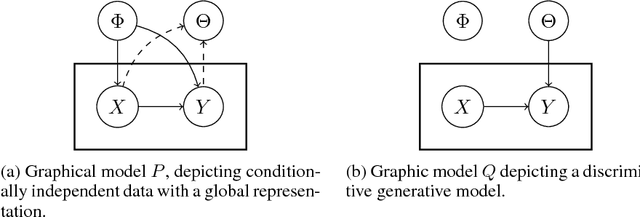
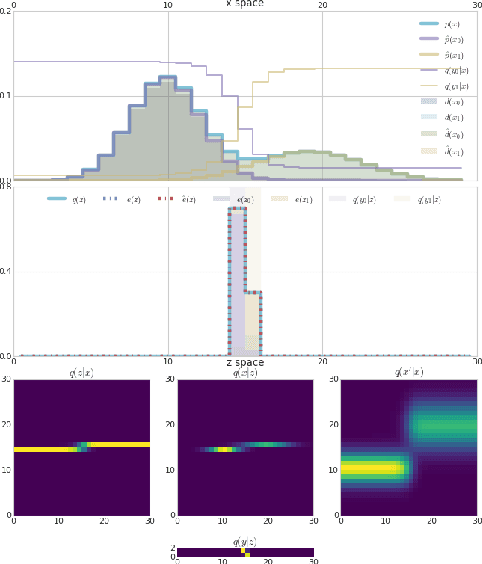
In this work we offer a framework for reasoning about a wide class of existing objectives in machine learning. We develop a formal correspondence between this work and thermodynamics and discuss its implications.
Uncertainty in the Variational Information Bottleneck
Jul 02, 2018
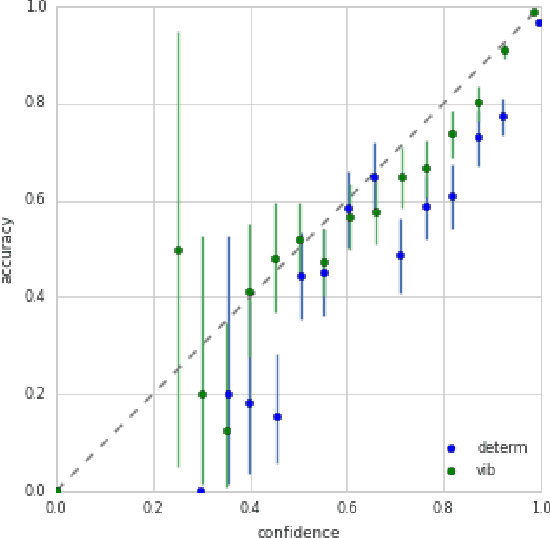
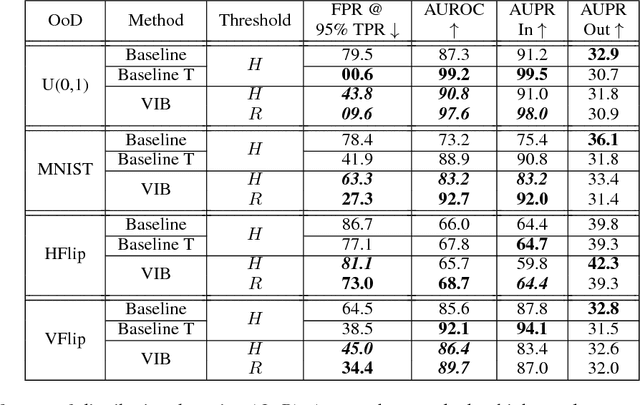
We present a simple case study, demonstrating that Variational Information Bottleneck (VIB) can improve a network's classification calibration as well as its ability to detect out-of-distribution data. Without explicitly being designed to do so, VIB gives two natural metrics for handling and quantifying uncertainty.
Generative Models of Visually Grounded Imagination
Feb 25, 2018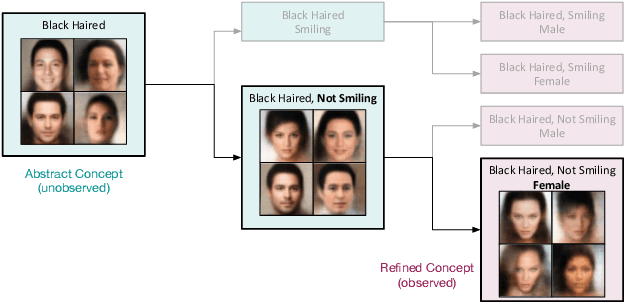
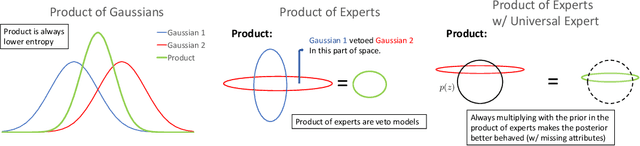
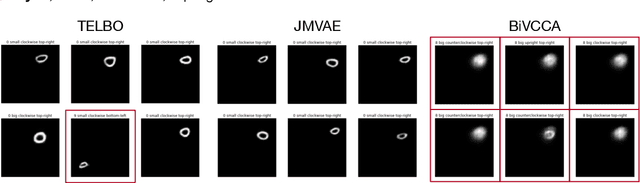
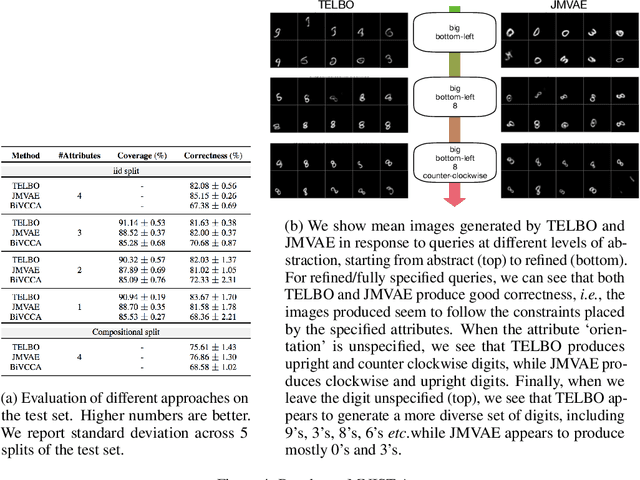
It is easy for people to imagine what a man with pink hair looks like, even if they have never seen such a person before. We call the ability to create images of novel semantic concepts visually grounded imagination. In this paper, we show how we can modify variational auto-encoders to perform this task. Our method uses a novel training objective, and a novel product-of-experts inference network, which can handle partially specified (abstract) concepts in a principled and efficient way. We also propose a set of easy-to-compute evaluation metrics that capture our intuitive notions of what it means to have good visual imagination, namely correctness, coverage, and compositionality (the 3 C's). Finally, we perform a detailed comparison of our method with two existing joint image-attribute VAE methods (the JMVAE method of Suzuki et.al. and the BiVCCA method of Wang et.al.) by applying them to two datasets: the MNIST-with-attributes dataset (which we introduce here), and the CelebA dataset.
Fixing a Broken ELBO
Feb 13, 2018
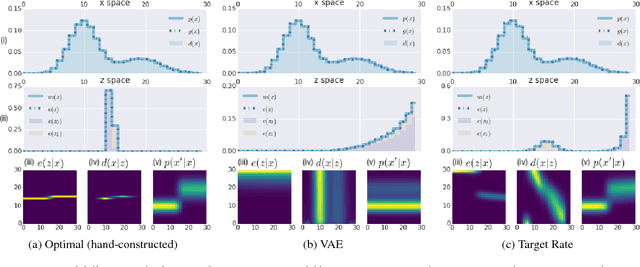
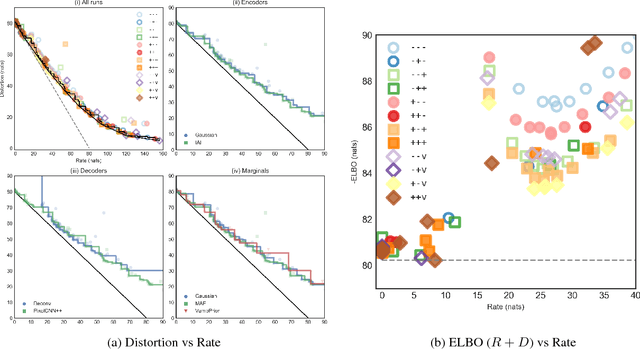
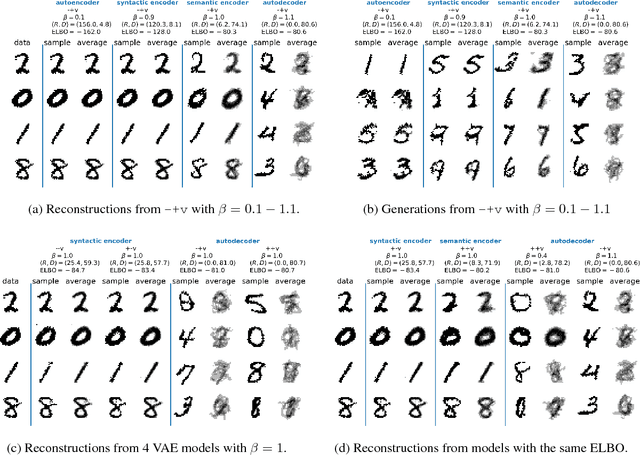
Recent work in unsupervised representation learning has focused on learning deep directed latent-variable models. Fitting these models by maximizing the marginal likelihood or evidence is typically intractable, thus a common approximation is to maximize the evidence lower bound (ELBO) instead. However, maximum likelihood training (whether exact or approximate) does not necessarily result in a good latent representation, as we demonstrate both theoretically and empirically. In particular, we derive variational lower and upper bounds on the mutual information between the input and the latent variable, and use these bounds to derive a rate-distortion curve that characterizes the tradeoff between compression and reconstruction accuracy. Using this framework, we demonstrate that there is a family of models with identical ELBO, but different quantitative and qualitative characteristics. Our framework also suggests a simple new method to ensure that latent variable models with powerful stochastic decoders do not ignore their latent code.
Deep Variational Information Bottleneck
Jul 17, 2017
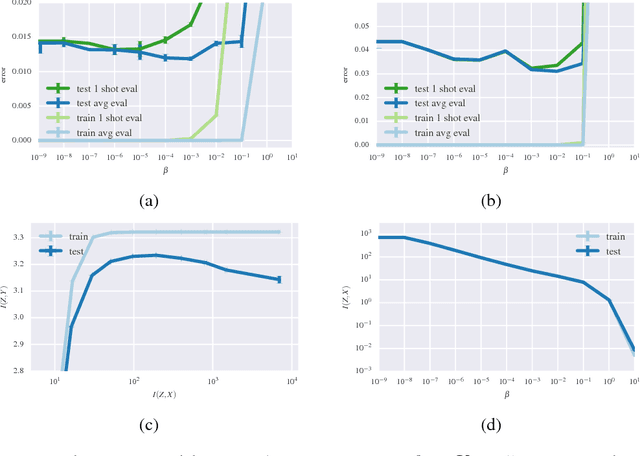
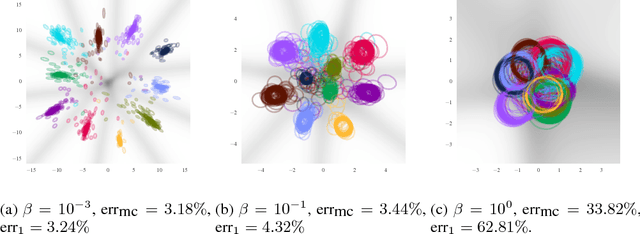
We present a variational approximation to the information bottleneck of Tishby et al. (1999). This variational approach allows us to parameterize the information bottleneck model using a neural network and leverage the reparameterization trick for efficient training. We call this method "Deep Variational Information Bottleneck", or Deep VIB. We show that models trained with the VIB objective outperform those that are trained with other forms of regularization, in terms of generalization performance and robustness to adversarial attack.
Speed/accuracy trade-offs for modern convolutional object detectors
Apr 25, 2017
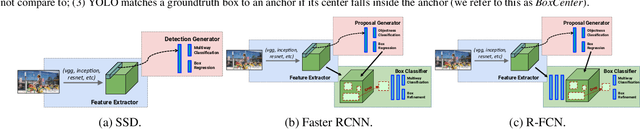

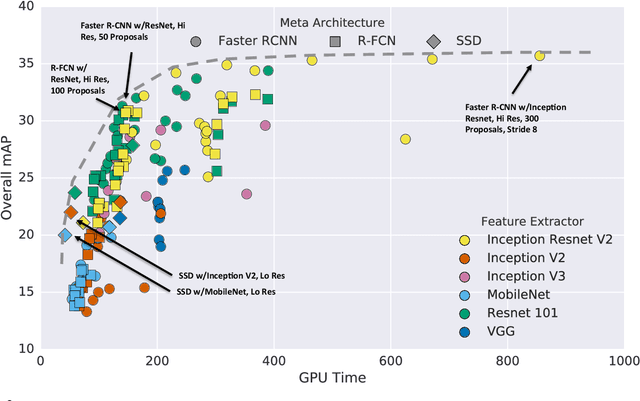
The goal of this paper is to serve as a guide for selecting a detection architecture that achieves the right speed/memory/accuracy balance for a given application and platform. To this end, we investigate various ways to trade accuracy for speed and memory usage in modern convolutional object detection systems. A number of successful systems have been proposed in recent years, but apples-to-apples comparisons are difficult due to different base feature extractors (e.g., VGG, Residual Networks), different default image resolutions, as well as different hardware and software platforms. We present a unified implementation of the Faster R-CNN [Ren et al., 2015], R-FCN [Dai et al., 2016] and SSD [Liu et al., 2015] systems, which we view as "meta-architectures" and trace out the speed/accuracy trade-off curve created by using alternative feature extractors and varying other critical parameters such as image size within each of these meta-architectures. On one extreme end of this spectrum where speed and memory are critical, we present a detector that achieves real time speeds and can be deployed on a mobile device. On the opposite end in which accuracy is critical, we present a detector that achieves state-of-the-art performance measured on the COCO detection task.
Adversarial Transformation Networks: Learning to Generate Adversarial Examples
Mar 28, 2017
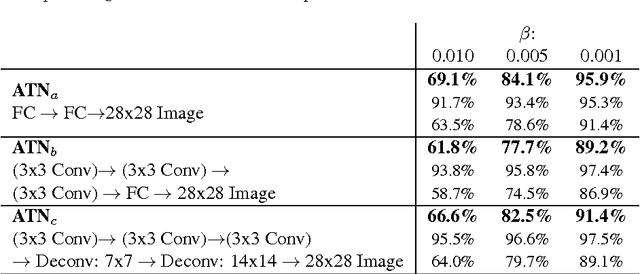

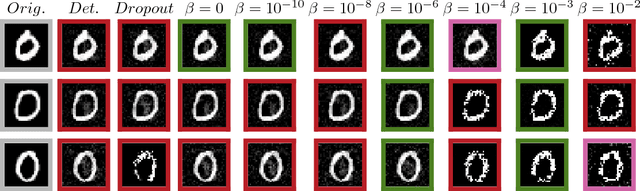
Multiple different approaches of generating adversarial examples have been proposed to attack deep neural networks. These approaches involve either directly computing gradients with respect to the image pixels, or directly solving an optimization on the image pixels. In this work, we present a fundamentally new method for generating adversarial examples that is fast to execute and provides exceptional diversity of output. We efficiently train feed-forward neural networks in a self-supervised manner to generate adversarial examples against a target network or set of networks. We call such a network an Adversarial Transformation Network (ATN). ATNs are trained to generate adversarial examples that minimally modify the classifier's outputs given the original input, while constraining the new classification to match an adversarial target class. We present methods to train ATNs and analyze their effectiveness targeting a variety of MNIST classifiers as well as the latest state-of-the-art ImageNet classifier Inception ResNet v2.
Adversarial examples for generative models
Feb 22, 2017


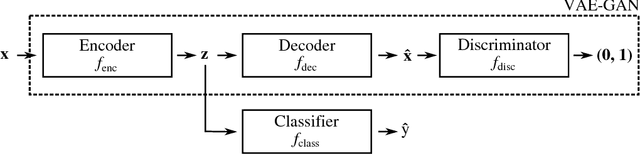
We explore methods of producing adversarial examples on deep generative models such as the variational autoencoder (VAE) and the VAE-GAN. Deep learning architectures are known to be vulnerable to adversarial examples, but previous work has focused on the application of adversarial examples to classification tasks. Deep generative models have recently become popular due to their ability to model input data distributions and generate realistic examples from those distributions. We present three classes of attacks on the VAE and VAE-GAN architectures and demonstrate them against networks trained on MNIST, SVHN and CelebA. Our first attack leverages classification-based adversaries by attaching a classifier to the trained encoder of the target generative model, which can then be used to indirectly manipulate the latent representation. Our second attack directly uses the VAE loss function to generate a target reconstruction image from the adversarial example. Our third attack moves beyond relying on classification or the standard loss for the gradient and directly optimizes against differences in source and target latent representations. We also motivate why an attacker might be interested in deploying such techniques against a target generative network.