 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeManipArena: Comprehensive Real-world Evaluation of Reasoning-Oriented Generalist Robot Manipulation
Mar 30, 2026Vision-Language-Action (VLA) models and world models have recently emerged as promising paradigms for general-purpose robotic intelligence, yet their progress is hindered by the lack of reliable evaluation protocols that reflect real-world deployment. Existing benchmarks are largely simulator-centric, which provide controllability but fail to capture the reality gap caused by perception noise, complex contact dynamics, hardware constraints, and system latency. Moreover, fragmented real-world evaluations across different robot platforms prevent fair and reproducible comparison. To address these challenges, we introduce ManipArena, a standardized evaluation framework designed to bridge simulation and real-world execution. ManipArena comprises 20 diverse tasks across 10,812 expert trajectories emphasizing reasoning-oriented manipulation tasks requiring semantic and spatial reasoning, supports multi-level generalization through controlled out-of-distribution settings, and incorporates long-horizon mobile manipulation beyond tabletop scenarios. The framework further provides rich sensory diagnostics, including low-level motor signals, and synchronized real-to-sim environments constructed via high-quality 3D scanning. Together, these features enable fair, realistic, and reproducible evaluation for both VLA and world model approaches, providing a scalable foundation for diagnosing and advancing embodied intelligence systems.
When LLMs step into the 3D World: A Survey and Meta-Analysis of 3D Tasks via Multi-modal Large Language Models
May 16, 2024



As large language models (LLMs) evolve, their integration with 3D spatial data (3D-LLMs) has seen rapid progress, offering unprecedented capabilities for understanding and interacting with physical spaces. This survey provides a comprehensive overview of the methodologies enabling LLMs to process, understand, and generate 3D data. Highlighting the unique advantages of LLMs, such as in-context learning, step-by-step reasoning, open-vocabulary capabilities, and extensive world knowledge, we underscore their potential to significantly advance spatial comprehension and interaction within embodied Artificial Intelligence (AI) systems. Our investigation spans various 3D data representations, from point clouds to Neural Radiance Fields (NeRFs). It examines their integration with LLMs for tasks such as 3D scene understanding, captioning, question-answering, and dialogue, as well as LLM-based agents for spatial reasoning, planning, and navigation. The paper also includes a brief review of other methods that integrate 3D and language. The meta-analysis presented in this paper reveals significant progress yet underscores the necessity for novel approaches to harness the full potential of 3D-LLMs. Hence, with this paper, we aim to chart a course for future research that explores and expands the capabilities of 3D-LLMs in understanding and interacting with the complex 3D world. To support this survey, we have established a project page where papers related to our topic are organized and listed: https://github.com/ActiveVisionLab/Awesome-LLM-3D.
gSLICr: SLIC superpixels at over 250Hz
Sep 14, 2015
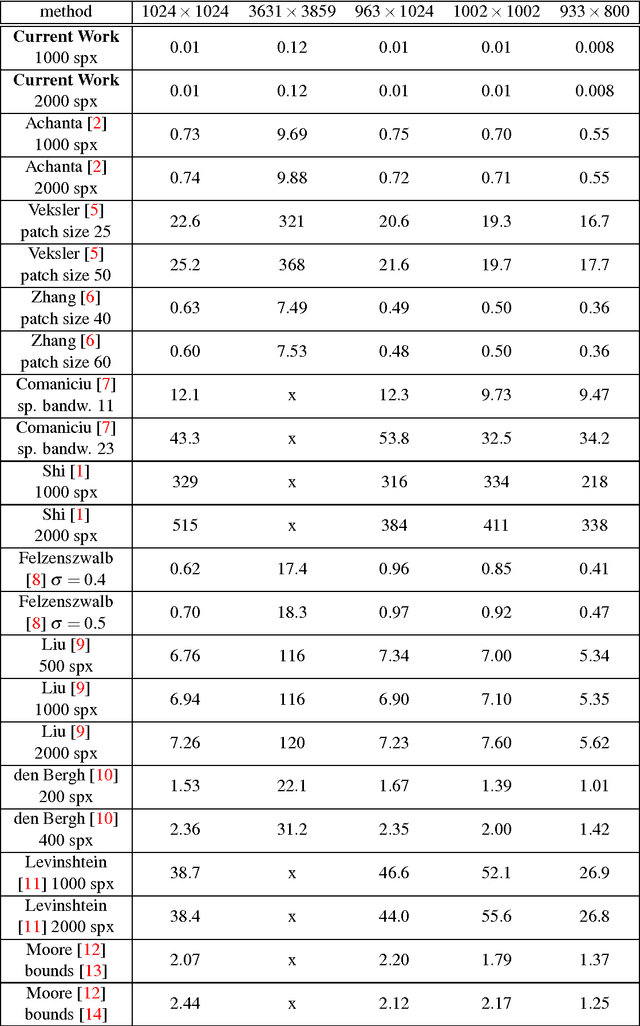
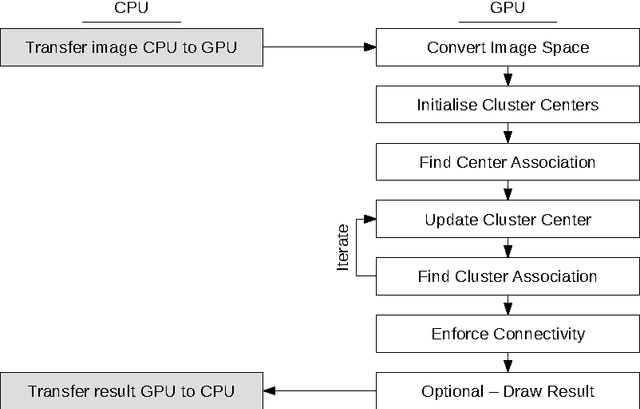
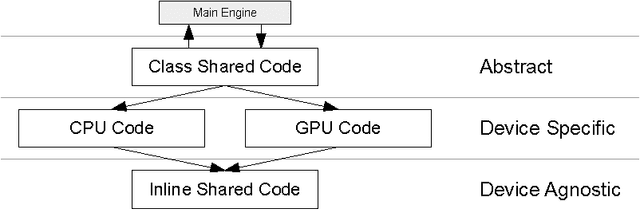
We introduce a parallel GPU implementation of the Simple Linear Iterative Clustering (SLIC) superpixel segmentation. Using a single graphic card, our implementation achieves speedups of up to $83\times$ from the standard sequential implementation. Our implementation is fully compatible with the standard sequential implementation and the software is now available online and is open source.